Deadlocks⚓︎
约 3875 个字 74 行代码 预计阅读时间 20 分钟
核心知识
- 基本概念:触发死锁的四个条件、资源分配图
- 解决死锁的方法
- 死锁阻止:消除四个条件中的任意一种
- 死锁避免:安全状态、资源分配图算法(单实例
) 、银行家算法(多实例) - 死锁检测 + 恢复(中止 / 抢占
) :- 等待图
死锁(deadlock):一组进程中,每个进程都在等待由这组进程中另一个进程导致的一个事件的现象。
System Model⚓︎
资源类型(resource type) 包括 CPU(周期
线程会按以下步骤使用资源(其中请求和释放资源的操作属于系统调用
- 请求(request)
- 若请求无法立即满足,那么发起请求的线程必须等待,直到获取资源
- 使用(use)
- 释放(release)
系统表(system table) 记录了每个资源被释放和被分配的情况。
Deadlock in Multithreaded Applications⚓︎
例子
以下使用 Pthread 提供的互斥锁的程序可能存在死锁问题:
pthread_mutex_t first_mutex;
pthread_mutex_t second_mutex;
pthread_mutex_init(&first mutex,NULL);
pthread_mutex_init(&second mutex,NULL);
/* thread one runs in this function */
void *do_work_one(void *param) {
pthread_mutex_lock(&first_mutex);
pthread_mutex_lock(&second_mutex);
/**
* Do some work
*/
pthread_mutex_unlock(&second_mutex);
pthread_mutex_unlock(&first_mutex);
pthread_exit(0);
}
/* thread two runs in this function */
void *do_work_two(void *param) {
pthread_mutex_lock(&second_mutex);
pthread_mutex_lock(&first_mutex);
/**
* Do some work
*/
pthread_mutex_unlock(&first_mutex);
pthread_mutex_unlock(&second_mutex);
pthread_exit(0);
}
由于取决于具体的调度情况,因此死锁不总是发生。
活锁(livelock) 类似死锁,但它发生在线程连续尝试会导致失败的行动的时候(就像过道上两个相向而行的人按相同方向(比如你往右,ta 往左)给对方让路,导致谁也过不去pthread_mutex_trylock() 检测活锁:
例子
/* thread one runs in this function */
void *do_work_one(void *param) {
int done = 0;
while (!done) {
pthread_mutex_lock(&first_mutex);
if (pthread_mutex_trylock(&second_mutex)) {
/**
* Do some work
*/
pthread_mutex_unlock(&second_mutex);
pthread_mutex_unlock(&first_mutex);
done = 1;
}
else
pthread_mutex_unlock(&first_mutex);
}
pthread_exit(0);
}
/* thread two runs in this function */
void *do_work_two(void *param)
{
int done = 0;
while (!done) {
pthread_mutex_lock(&second_mutex);
if (pthread_mutex_trylock(&first_mutex)) {
/**
* Do some work
*/
pthread_mutex_unlock(&first_mutex);
pthread_mutex_unlock(&second_mutex);
done = 1;
}
else
pthread_mutex_unlock(&second_mutex);
}
pthread_exit(0);
}
可通过限制重试次数来避免活锁问题。
Deadlock Characterization⚓︎
Necessary Conditions⚓︎
若以下四个条件同时发生,死锁就出现了:
- 互斥(mutual exclusion):至少有一个资源处于非共享模式,即同一时间内只有一个线程能使用该资源;若有别的线程请求该资源,则该线程必须延迟,直到资源被释放
- 保持并等待(hold and wait):线程必须持有至少一个资源,并且等待获取额外的,目前正被其他线程持有的资源
- 无抢占(no preemption):资源无法被抢占,即资源能够被其持有的线程在完成任务后自愿释放
- 循环等待(circular wait):必须存在一组等待线程 \(\{T_0, T_1, \dots, T_n\}\),满足 \(T_i\) 等待 \(T_{(i + 1) \text{ mod } (n + 1)}\ (i = 0, \dots n)\)
注:这四个条件并非完全独立。
Resource-Allocation Graph⚓︎
一种能精确描述死锁的有向图是系统资源分配图(resource-allocation graph)。
- 顶点集合 \(V\) 被划分为两类:活跃线程 \(T = \{T_1, \dots, T_n\}\)(用圆圈表示)和资源类型 \(R = \{R_1, \dots, R_m\}\)(用矩形表示)
- 由于 \(R_j\) 可能有不止一个实例,所以用矩形中的点表示一个个实例
- 边集合 \(E\) 也分为两类:
- 请求边(request edge) \(T_i \rightarrow R_j\):线程 \(T_i\) 正在请求 \(R_j\) 的一个实例,并且当前正在等待该资源
- 分配边(allocation edge) \(R_j \rightarrow T_i\):资源 \(R_j\) 的一个实例已被分配给线程 \(T_i\)
当 \(T_i\) 请求 \(R_j\) 时,需往资源分配图插入一条请求边;若请求得到满足,则需将这条请求边立即转换为分配边。若线程释放该资源,则从图中删掉这条分配边。
下图展示了一张资源分配图:

当图中出现环时,说明可能存在死锁。
- 若一个资源类型只有一个实例,那么死锁一定发生了
-
若一个资源类型只有多个实例,那么死锁不一定发生,比如:
-
发生死锁
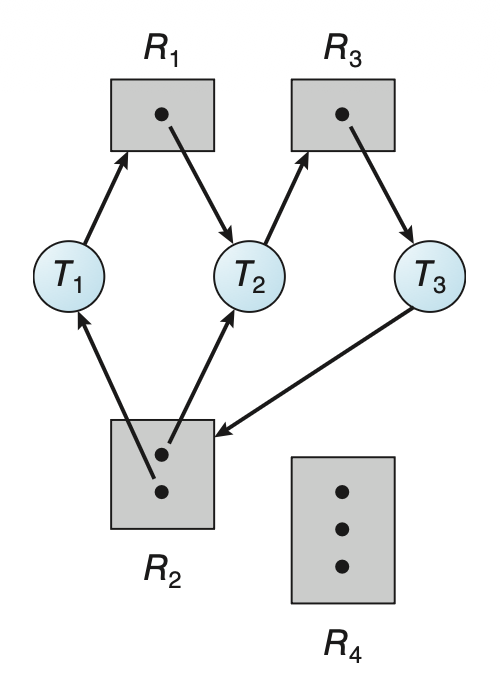
-
未发生死锁

-
Methods for Handling Deadlocks⚓︎
我们有以下应对死锁的办法:
- 忽视死锁问题,就当它不存在
- 啥也不管的结果是系统停止工作,需要重启(虽然粗暴,但是成本低,也不失为一种方法)
- 使用一种阻止或避免死锁发生的协议,确保系统永远不会进入死锁状态
- 死锁阻止(deadlock prevention):确保至少有一个必要条件不成立,通过约束资源请求实现
- 死锁避免(deadlock avoidance):提前提供关于线程在生命周期内会请求和使用什么资源的额外信息
- 允许系统进入死锁状态,但能够检测出来并能恢复系统
Deadlock Prevention⚓︎
下面来看如何依次阻止四种必要条件。
Mutual Exclusion⚓︎
- 可共享 (sharable) 资源(比如只读文件)不要求互斥,因此不会出现死锁
- 但我们可不能通过取消互斥条件来阻止死锁,因为像互斥锁这样的资源不得同时分配给多个线程
Hold and Wait⚓︎
- 一种方法是要求每个线程发起请求,并在开始执行前被分配到所有资源
- 由于资源请求的动态性,这种方法对大多数应用程序而言不太实际
- 另一种方法是仅当线程没有资源时才能去请求资源
- 这两种方法均有以下显著缺点:
- 资源利用率低
- 可能会出现饥饿现象
No Preemption⚓︎
阻止该条件就意味着允许抢占,即:当一个线程已持有一些资源,并请求另一个无法立即分配给它的资源,那么该线程当前持有的所有资源将被抢占,即这些资源被隐式释放。该线程只有在重新获得这些资源后才能重新开始。
该方法通常适用于状态容易被保存和恢复的资源上,比如 CPU 寄存器和数据库事务等;但像互斥锁、信号量等频繁发生死锁的资源就不适合用这种方法。
Circular Wait⚓︎
通过上述分析,我们发现前三种方法在大多数情况下都不太实用。不过我们可以寄希望于这一方法:强迫所有资源类型为全序(total order),并要求每一个线程按枚举的递增顺序请求资源,从而阻止循环等待的发生。
令资源类型集合为 \(R = \{R_1, \dots, R_m\}\)。我们定义一个单射函数 \(F: R \rightarrow \mathbb{N}\),其中 \(\mathbb{N}\) 为自然数集合,为每个资源类型赋予一个唯一的整数,从而比较资源之间的先后顺序。
假如线程请求资源 \(R_i\) 的一个实例,那么它之后只能请求满足 \(F(R_j) > F(R_i)\) 的资源 \(R_j\) 的实例;或者也可以这样:线程请求资源 \(R_j\) 的实例前,必须释放任何满足 \(F(R_i) \le F(R_j)\) 的 \(R_i\) 的实例。
可以用反证法证明该方法的正确性。
顺序本身并不能阻止死锁发生,要编写能够遵循该顺序的程序才能阻止死锁发生。但要建立这样的顺序很困难,因为系统中有成百上千的锁。不过像 Java 等编程语言提供了解决方案。
需要注意的是,如果锁能够动态被获取,那么该方法不一定能阻止死锁发生。
死锁阻止算法的问题是较低的设备利用率和系统吞吐量的下降。
Deadlock Avoidance⚓︎
死锁避免算法中,最简单且最有用的模型是要求每个线程声明它可能需要的资源类型的最大数量。死锁避免算法会动态监测资源分配状态(包括空闲的和分配好的资源数,以及各线程的最大需求)来确保循环等待情况永远不存在。下面将会具体探讨两类死锁避免算法:
Safe State⚓︎
- 若系统能以某种顺序为每个线程(取决于其最大数)分配资源且仍能避免死锁发生,那么该系统是安全的
- 更形式地,仅当存在一个安全序列(safe sequence),即对于当前分配状态,有一个线程序列 \(<T_1, \dots, T_n>\),对其中的每个线程 \(T_i\),它能请求的资源能被当前的空闲资源满足,且持有该资源的线程 \(T_j\) 满足 \(j < i\) 时,系统处于安全状态
- 此时,若 \(T_i\) 所请求的资源并不空闲,那么它就会等到所有 \(T_j\) 完成为止;之后 \(T_i\) 就能获取它要获取的全部资源,完成指定任务后释放资源,随后终止
- 当 \(T_i\) 终止时,\(T_{i+1}\) 能够获取它需要的资源,以此类推
- 若不存在这样的序列,那么系统就是不安全的
- 处于安全状态下的系统一定不会死锁,但处在不安全状态下并不一定会发生死锁;换句话说,不安全状态可能会导致死锁
- 死锁避免算法的思路就是要让系统保持安全状态
- 一开始系统处在安全状态
- 当线程请求一个当前空闲的资源时,系统需决定是否立即将该资源分配给线程,或者必须让线程等待(可能会降低资源利用率)
- 仅当分配后系统仍处于安全状态时,该请求会被满足
Resource-Allocation-Graph Algorithm⚓︎
若每个资源类型只有一个实例,那么可以使用资源分配图的一个变体来实现死锁避免。
- 除了请求边和分配边外,还需额外引入一种声明边(claim edge) \(T_i \rightarrow R_j\),表示 \(T_i\) 可能在将来某个时间会请求资源 \(R_j\),在图中用虚线表示
- 当 \(T_i\) 向 \(R_j\) 发起请求后,声明边就变成了请求边
- 当 \(T_i\) 释放了 \(R_j\) 后,分配边 \(R_j \rightarrow T_i\) 又重新变回声明边 \(T_i \rightarrow R_j\)
- 对资源的声明必须提前(在线程开始执行前)定好
- 可以松弛该条件为:仅当和线程 \(T_i\) 关联的所有边都是声明边时,允许声明边 \(T_i \rightarrow R_j\) 加入;换句话说就是只要在线程还没发起任何请求前就确定好所有声明即可,不必在刚开始执行线程时就要确定
- 仅当请求边变成分配边后,图中没有出现环时,该请求才会被满足
- 通过环检测算法进行安全检查,需要 \(n^2\) 次运算,其中 \(n\) 为线程数
-

安全状态 -

不安全状态
Banker's Algorithm⚓︎
若资源类型存在多个实例,那么上述算法就不适用了。现在介绍一种能应对该情况,但是更低效的算法,称为银行家算法(banker's algorithm)。
- 当新线程进入系统时,必须声明它可能需要的每个资源类型的最大实例数(不得超过资源总数)
-
实现该算法要用到的一些数据结构(其中
n为线程数,m为资源类型数;数据结构的规模和值会随时间变化)Available:长为m的向量,表示每个资源类型的空闲实例数;Available[j] = k表示 \(R_j\) 有 \(k\) 个空闲实例Max:n * m的矩阵,定义每个线程的最大需求;Max[i][j] = k表示 \(T_i\) 最多向 \(R_j\) 请求 \(k\) 个实例Allocation:n * m的矩阵,定义每个资源类型当前分配给线程的实例数;Allocation[i][j] = k表示 \(T_i\) 以被分配到 \(R_j\) 的 \(k\) 个实例Need:n * m的矩阵,表示每个线程剩余的资源需求;Need[i][j] = k表示 \(T_i\) 可能还需要 \(k\) 个 \(R_j\) 的实例来完成任务Need[i][j] = Max[i][j] - Allocation[i][j]
-
为简化表示,我们设定一些记号:令
X,Y是长为n的向量,当且仅当X[i] <= Y[i],i = 1, 2, ..., n时,X <= Y- 我们将矩阵
Allocation和Need的行元素看作向量,即Allocation[i](当前分配给 \(T_i\) 的资源)和Need[i](\(T_i\) 还需请求的额外资源)
- 我们将矩阵
先给出判断系统是否处在安全状态下的算法(需要 \(m \times n^2\) 次运算
- 令
Work和Finish分别为长为m,n的向量;初始化Work = Available, Finish[i] = false(i = 0, ..., n - 1) -
寻找索引
i,需同时满足:Finish[i] == falseNeed[i] <= Work
若不存在这样的
i,直接来到步骤 4 -
Work += Allocation[i],Finish[i] = true,跳转到步骤 2 - 若对所有
i,Finish[i] == true,那么系统处于安全状态
再给出确定某个请求是否能被安全满足的算法。令 Request[i] 为 \(T_i\) 的请求向量,若 Request[i][j] == k,那么 \(T_i\) 需要 \(k\) 个 \(R_j\) 的实例。当发生 \(T_i\) 的请求时,需要采取以下行动:
- 若
Request[i] <= Need[i],跳转到步骤 2,否则抛出错误(因为线程请求超出最大的声明数量) - 若
Request[i] <= Available,跳转到步骤 3,否则 \(T_i\) 必须等待,因为资源不可用 -
让系统假装已经将请求的资源分配给线程 \(T_i\),通过如下方式修改状态:
若结果的资源分配状态是安全的,那么 \(T_i\) 就能被分配到资源;否则 \(T_i\) 必须等待
Request[i],并恢复原来的资源分配状态
例子
考虑一个包含 5 个线程 \(T_0\) 到 \(T_4\) 和 3 种资源类型 \(A, B, C\) 的系统。资源类型 \(A\) 有 10 个实例,资源类型 \(B\) 有 5 个实例,资源类型 \(C\) 有 7 个实例。假设以下快照代表了系统的当前状态:
\(Need\) 矩阵的内容定义为 \(Max - Allocation\),如下所示:
我们声称系统目前处于安全状态。序列 \(<T_1, T_3, T_4, T_2, T_0>\) 满足安全标准。假设现在线程 \(T_1\) 请求 1 个额外的资源类型 \(A\) 的实例和 2 个资源类型 \(C\) 的实例,因此 \(Request_1 = (1, 0, 2)\)。为了决定该请求是否可以被立即满足,我们首先检查 \(Request_1 \leq Available\)——即 \((1, 0, 2) \leq (3, 3, 2)\),结果为真。然后假装该请求已经满足,于是进入了以下新状态:
我们必须确定这个新的系统状态是否安全。为此,我们执行安全算法,发现序列 \(<T_1, T_3, T_4, T_0, T_2>\) 满足安全要求。因此,我们可以立即满足线程 \(T_1\) 的请求。
可以发现:
- 当系统处于此状态时,因为资源不足,\(T_4\) 发出的 \((3, 3, 0)\) 请求无法被满足
- 此外,\(T_0\) 发出的 \((0, 2, 0)\) 请求也无法被满足,因为尽管资源充足,但会导致结果状态是不安全的
注:现代主流 OS 很少会采用银行家算法来实现死锁避免
Deadlock Detection⚓︎
如果既不阻止也不避免,那么死锁就有可能发生。此时系统可能会提供对应的检测和恢复机制,下面就从检测死锁开始讲起。
Single Instance of Each Resource Type⚓︎
还是先来考虑所有资源类型只有一个实例的情况。我们可以用一个叫做等待图(wait-for graph) 的变体来实现死锁检测算法,该图可通过在资源分配图的基础上,移除资源节点并合并适当的边得到。
更准确地说,等待图中的边 \(T_i \rightarrow T_j\) 表明 \(T_i\) 等待 \(T_j\) 释放 \(T_i\) 所需的资源,即 \(T_i \rightarrow R_q, R_q \rightarrow T_j\)。如下图所示,右边的等待图就是从左边的资源分配图中得到的。

类似地,当且仅当等待图中出现环时,死锁存在。为检测死锁,系统必须维护这样一张等待图,并周期性地调用算法在图中查找环。该算法需要 \(O(n^2)\) 次运算。
Several Instances of a Resource Type⚓︎
而对于多实例的资源类型,我们需要另一种算法。和前面的银行家算法类似,同样需要准备一些数据结构:
Available:长为m的向量,表示每个资源类型的空闲实例数Allocation:n * m的矩阵,定义每个资源类型当前分配给线程的实例数Request:n * m的矩阵,表示每个线程的当前请求;若Request[i][j] == k,那么 \(T_i\) 需要 \(k\) 个 \(R_j\) 的实例
算法如下:
- 令
Work和Finish分别为长为m,n的向量;- 初始化
Work = Available,且 - 若
Allocation[i] != 0,Finish[i] = false,否则Finish[i] = true(i = 0, ..., n - 1)
- 初始化
-
寻找索引
i,需同时满足:Finish[i] == falseRequest[i] <= Work
若不存在这样的
i,直接来到步骤 4 -
Work = Work + Allocation[i],Finish[i] = true,跳转到步骤 2 - 若对一些
i,Finish[i] == false,那么系统处于死锁状态,且死锁的是 \(T_i\)
该算法需要 \(m \times n^2\) 次运算。
例子
考虑一个包含 5 个线程 \(T_0\) 到 \(T_4\) 和 3 种资源类型 \(A, B, C\) 的系统。资源类型 \(A\) 有 7 个实例,资源类型 \(B\) 有 2 个实例,资源类型 \(C\) 有 6 个实例。假设以下快照代表了系统的当前状态:
系统目前不处于死锁状态,因为执行算法就会发现序列 \(<T_0, T_2, T_3, T_1, T_4>\) 能够使得所有 \(i\) 的 \(Finish[i] == true\)。
假设现在线程 \(T_2\) 对资源类型 \(C\) 的实例又提出了一个额外的请求。\(Request\) 矩阵修改如下:
现在系统处于死锁状态。虽然可以回收由线程 \(T_0\) 持有的资源,但可用资源的数量不足以满足其他线程的请求。因此,存在一个由线程 \(T_1, T_2, T_3, T_4\) 组成的死锁。
Detection-Algorithm Usage⚓︎
何时调用死锁检测算法取决于以下因素:
- 死锁发生的频率
- 受死锁影响的线程数
算法调用太多,可能会带来相当大的计算开销,因此可以选择固定时间间隔调用一次算法。
Recovery from Deadlock⚓︎
发现死锁后,系统可能从死锁中自动恢复。下面将介绍一些恢复方法:
Process and Thread Termination⚓︎
一种方法是中止(abort) 线程或进程,可采取的策略有:
- 中止所有死锁进程:显然能直接打破死锁,但开销很大
- 一次中止一个进程,直到死锁消除:开销也挺大,因为每中止一个进程就要重新调用一次死锁检测算法
- 通常会选取开销最小的那个进程中止,而所谓的“最小开销”涉及到很多因素,包括:
- 进程的优先级
- 进程的计算时长和完成任务前还需多少时间
- 进程需要用多少以及什么类型的资源
- 进程为完成任务还需的资源数
- 需要终止的进程数
- 通常会选取开销最小的那个进程中止,而所谓的“最小开销”涉及到很多因素,包括:
况且中止一个进程并不容易——万一某个进程正在更新文件的过程中,直接中止会导致不一致的状态。
Resource Preemption⚓︎
另一种恢复方法是连续抢占进程的一些资源,把这些资源给别的进程,直到消除死锁。但使用该方法时需解决以下问题:
- 选择一名受害者(victim):需要确定哪些资源以及哪些进程,一般按最小成本(同样要考虑多种因素)确定抢占顺序
- 回滚(rollback):
- 被抢占进程必须被回滚到安全状态,之后从该状态重新开始
- 由于很难确定安全状态,可以采用最简单的方法——全回滚
- 虽然更高效的方法是只要把进程回滚到不出现死锁的阶段即可,但这样做需要维护额外的信息
- 饥饿(starvation):不要让进程一直被抢占,所以需要设置一个有限的抢占次数
评论区