Fundamentals⚓︎
约 9911 个字 490 行代码 预计阅读时间 56 分钟
注
说是 Fundamentals,实际上包含了一些杂七杂八、不知道怎么分类的东西,所以里面也混了一些比较新颖的语法(比如 std::optional
Background⚓︎
在正式进入 C++ 的学习前,不妨先来简单了解一下 C++ 相关的背景知识。
C 语言的优劣
- 优势:
- 高效编程
- 能直接访问机器,适用于 OS 和 ES(end system)
- 灵活
- 劣势:
- 不充分的类型检查
- 缺乏对大规模编程的支持
- 面向过程编程 (procedure-oriented programming)
C++ 发展史
C++ 之父——Bjarne Stroustrup,这是他的个人网站。
具体内容参见 xyx 老师 “C++ 的诞生”。
C++ 的第一个标准是 C++98(ISO/IEC 14882:1998),目前最新的标准为 C++23(ISO/IEC 14882:2024)。
所以 C++ 是什么呢?
摘自 Wikipedia Outline of C++ 的定义:
C++ is a statically typed, free-form, multi-paradigm, compiled, general-purpose programming language.
其中最鲜明的两个特征是:
-
静态类型(statically typed):
-
类型在编译时确定——C++ 是一种编译型语言(compiled language)
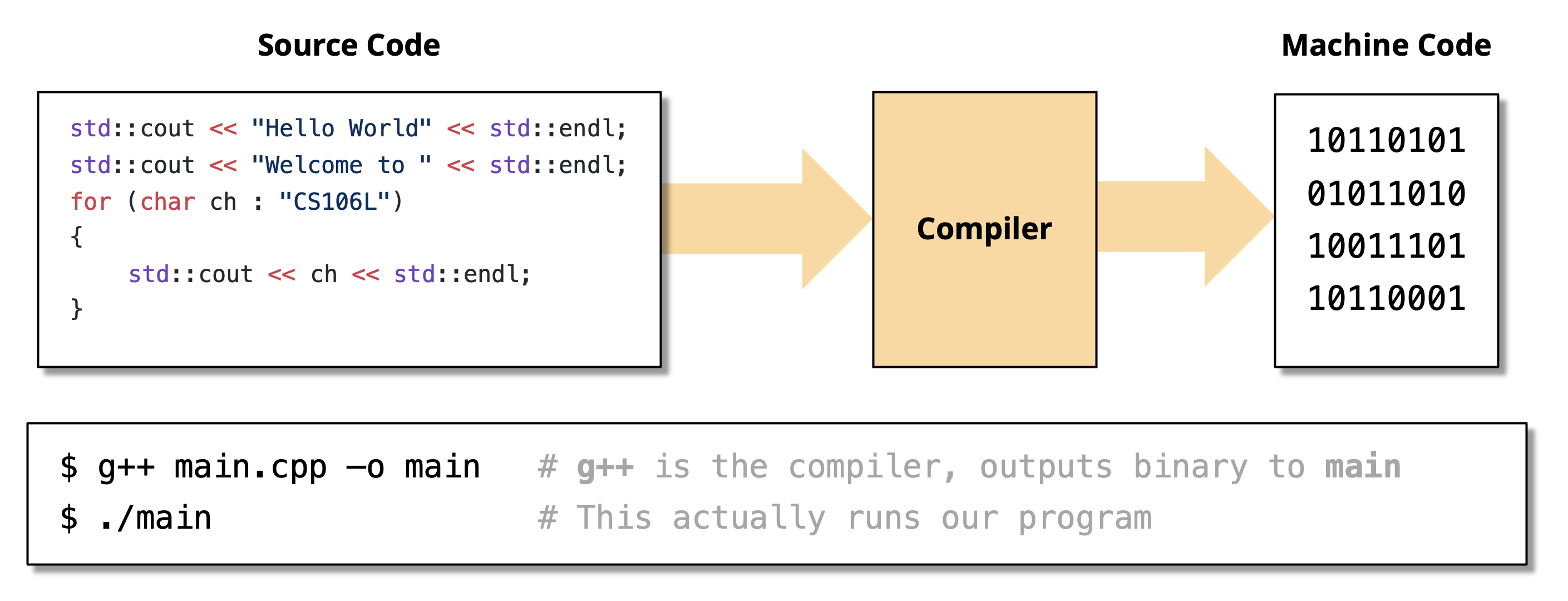
相对应的概念是解释型语言 (interpreted language),代表语言有 Python 等。编译型语言胜过解释型语言之处在于它能够更加高效地生成机器码(编译器能一次看到所有代码,而解释器一次只能看一条语句
) ;但编译需要一定的时间。 -
C++ 有一个强大的类型系统(type system)
-
-
多范式(multi-paradigm):包括以下范式:
C++ 的子语言
关于子语言的介绍。
C++ 的子语言可分为以下几类:
- C 语言
- 面向对象的 C++:类、封装、继承、多态、虚函数 ...
- 模板 C++(泛型编程
) :模板元编程 (TMP) - STL:容器、迭代器、算法、函数对象 (function objects)
C++ 的设计哲学:
- 可读性(readability):直接用代码表达思想和意图
- 安全性(safety):尽可能在编译时强制保证安全性
- 高效性(efficiency):不浪费时间和空间
- 抽象性(abstraction):将杂乱的构造分好类
- 多范式(multi-paradigm):赋予程序员完全的控制权、责任和选择权
实际上,C++ 还有助于我们培养良好的编码习惯——在用 C++ 写代码时,我们会很自然地考虑到以下问题:
- 我是否在以对象本应被使用的方式使用它们?——类型检查、类型安全
- 我是否正在高效使用内存?——引用 / 拷贝语义、移动语义
- 我是否在修改我不应该修改的东西?——
const和 const 正确性
而其他语言则放宽了上述限制。
The First C++ Program⚓︎
#include <iostream>
using namespace std;
int main() {
int number;
cout << "Enter a decimal number: ";
cin >> number;
cout << "The number you entered is " << number << endl;
return 0;
}
解释
- C++ 的头文件不用
.h后缀,且头文件的名称由小写字母构成 cin和cout分别表示标准输入流和标准输出流- 它们都支持连续输入 / 输出多个值
- 注意:
cin无法读取空白字符(包括空格、换行、制表符等)
-
方便起见,源程序开头加一句
using namespace std;,表示使用标准命名空间。如果没有这句的话,后面的cin、cout和endl都要加上std::前缀,否则无法编译注意
实际编程时,请尽可能避免使用这种语句,因为这被认为是一种不良的设计,破坏了 C++ 命名空间的设计本意。
-
<<和>>分别表示插入符(insertor) 和提取符(extractor),并分别适用于cout和cin endl:换行,意为 end of line
在 C++ 中,任何类型的变量存放的都是一个对象(object)。
Interesting Things
以下三段代码是等价的 C++ 代码:
注:这段代码只能在 x86 架构的 CPU 上被编译。
#include "stdio.h"
#include "stdlib.h"
int main(int argc, char **argv) {
asm(".LC0:\n\t"
".string \"Hello, world!\"\n\t"
"main:\n\t"
"push rbp\n\t"
"mov rbp, rsp\n\t"
"sub rsp, 16\n\t"
"mov DWORD PTR [rbp-4], edi\n\t"
"mov QWORD PTR [rbp-16], rsi\n\t"
"mov edi, OFFSET FLAT:.LC0\n\t"
"call puts\n\t");
return EXIT_SUCCESS;
}
可以看到,C++ 既能向后兼容 C,也能执行汇编代码。Intersting!
Type System⚓︎
- 我们可以把类型(types) 看作变量的“种类 (category)”。
- C++ 提供了诸如
int,double,string,bool,size_t等多种内建类型 (built-in types)。 - C++ 的一个鲜明特征是它是一种静态类型(statically typed) 语言:每个变量都有一个类型,且一旦声明类型后,之后就不得再修改类型了(而动态类型语言允许这种操作
) 。 - 这种语言的优点是
- 更加高效:
- 为编译器提供额外的变量信息,这样它能为变量更加高效地分配内存
- 根据内存中值的特殊结构,编译器还可能对性能进行优化,消除了运行时检查类型的需求
- 易于理解
- 提供了更方便的错误检查
- 更加高效:
Type Alias with using⚓︎
有时,代码中可能会出现像这样冗长的类型:
可以看到,这个函数的返回值类型特别“长”,不仅对敲代码的程序员而言不方便,也不方便其他人阅读代码。这时,我们可以使用 using 关键字,为类型创建别名:
using Zeros = std::pair<double, double>;
using Solution = std::pair<bool, Zeros>;
Solution solveQuadratic(double a, double b, double c);
现在的函数签名就清爽了很多——不仅类型名缩短了,还能提高可读性!
typedef
typedef 是 C 语言就有的一种用于为类型取别名的方法。虽然它的功能和 using 几乎一致,但是从可读性和实用性角度而言不如 using,且模板别名只能使用 using 而不得使用 typedef。所以建议平时写代码的时候就用 using 好了。
更多内容:using
Type Deduction with auto⚓︎
对于上述问题,还有一种“偷懒”的方法是使用 auto 关键字——我们不指明类型,让编译器自行推断具体的类型,这样我们写代码时就无需操心类型的问题了:
auto result = solveQuadratic(a, b, c);
// This is exactly the same as the above!
// result still has type std::pair<bool, std::pair<double, double>>
// We just told the compiler to figure this out for us!
很显然,result 的返回结果类型就是 Solution,所以编译器在编译时会自动帮我们推断出这一类型,在编译成机器码前将类型替换为具体的类型。但如果存在歧义的话,编译就有可能会失败,比如:
此时函数的返回值既可能是 std::pair<double, double> 类型,也可能是 std::vector<double> 类型,也就是说存在歧义。此时 auto 就没用了,还得要我们明确指出返回值的类型。
虽然这种方法相当省事,但是也降低了代码的可读性,所以在代码编写时我们需要权衡好其中的利弊。
更多内容:auto
Type Safety⚓︎
类型安全(type safety) 是编程语言的一个重要特性,它指的是阻止或限制不同类型之间不兼容的混合操作,从而提高代码的健壮性和可靠性。在 C++ 中,实现类型安全的主要方式有以下几种:
- 编译时类型检查:这是 C++ 类型安全的核心。编译器会检查函数调用时的参数类型、赋值操作的左右两侧类型是否匹配或兼容等。
- 显式类型转换(explicit casts):C++ 不鼓励隐式的、可能导致信息丢失或不安全行为的类型转换。对于需要进行的类型转换,推荐使用明确的类型转换操作符,如
static_cast、dynamic_cast、reinterpret_cast和const_cast。这使得代码的意图更加明确,也更容易被审查。 - RAII(Resource Acquisition Is Initialization,资源获取即初始化
) :虽然 RAII 主要用于资源管理,但它通过将资源的生命周期与对象的生命周期绑定,也间接增强了类型安全。例如,智能指针通过类型系统确保了内存的安全管理,防止了悬空指针等问题。 - 模板(templates):模板允许编写泛型代码,这些代码可以操作多种类型,但仍然保持类型安全。编译器会为每个使用的具体类型实例化模板,并进行相应的类型检查。
- 枚举类(enum classes)(C++11 引入
) :与传统的 C 风格枚举不同,枚举类的值不会隐式转换为整数,也无法与其他枚举类的值进行比较,除非显式转换。
尽管 C++ 提供了很多机制来保证类型安全,但它并非绝对安全。例如:
- C 风格数组和指针: C 风格数组容易发生越界访问,指针也可能指向无效内存(空指针、悬空指针、野指针
) 。这些问题通常在运行时才会暴露,甚至潜伏很深。 - 联合(union):
union允许在同一内存位置存储不同类型的数据,但编译器通常无法判断当前存储的是哪种类型,需要程序员自行管理。
std::optional⚓︎
引入
在 C++ 中,我们经常会遇到一种情况:一个函数可能返回一个有效的值,也可能因为某些原因无法返回有效值。
以前,处理这种情况的常见方式有:
- 返回特殊值(哨兵值):例如,一个返回整数的函数在失败时可能返回 -1 或 0。但这种方式的问题是,这些特殊值本身可能是合法的计算结果,从而导致混淆。
- 返回指针:如果函数返回一个对象,它可以返回一个指向该对象的指针。如果操作失败,则返回
nullptr。这种方式比特殊值要好一些,但引入了指针管理的复杂性(谁拥有这个指针?何时释放它? ) 。而且,对于基本类型(如int,double) ,返回指针会带来额外的开销和间接性。 - 通过输出参数返回:函数通过一个引用或指针参数来“返回”结果,并使用函数的布尔返回值来表示操作是否成功。这种方式略显笨拙,并且使得函数签名不够清晰。
- 抛出异常:在某些情况下,操作失败可以被视为一种异常情况,可以通过抛出异常来处理。但这对于“预期中可能不存在”的情况来说,可能过于重量级,并且会影响性能和控制流。
C++17 标准中,std::optional<T> 的出现优雅地解决上述问题。
std::optional<T> 是一个模板类,它可以包装一个可能存在也可能不存在的 T 类型的值。
- 包含值:
std::optional对象持有一个有效的T类型的值 - 不包含值:
std::optional对象不持有任何值,表示值缺失,此时用std::nullopt来表示
我们借助 std::optional 以下特点来增强 C++ 的类型安全:
- 明确的“缺失”状态:它明确地表达了一个值可能不存在的语义。使用者必须检查
std::optional是否包含值,然后才能安全地访问它,从而避免了运行时错误。 - 避免特殊值 / 哨兵值:不再需要依赖魔数或特殊值来表示失败或缺失,使得代码更清晰,并减少了潜在的逻辑错误。
- 避免不必要的指针和动态分配:对于可以栈上分配的对象,
std::optional可以直接在内部存储该对象,而不需要在堆上分配内存。这比返回指针更高效,也避免了指针管理的复杂性。 - 改善函数签名:函数签名能更清晰地表达其可能的返回结果。例如,
std::optional<User> findUser(UserId id);清晰地表明这个函数要么返回一个User对象,要么什么也不返回。 - 编译时提示:如果尝试直接访问一个可能为空的
std::optional中的值(例如,不加检查地使用operator*或operator->) ,并且它确实为空,通常会导致运行时异常(std::bad_optional_access) ,这比未定义行为要好得多。
std::optional 主要有以下成员函数和操作:
- 构造函数:
- 默认构造函数:创建一个不包含值的
std::optional std::optional(std::nullopt_t):显式创建一个不包含值的std::optionalstd::optional(const T& value)或std::optional(T&& value):创建一个包含给定值的std::optional- 拷贝 / 移动构造函数
- 默认构造函数:创建一个不包含值的
- 赋值操作符:
- 可以赋值
std::nullopt使其变为空 - 可以赋值一个
T类型的值使其包含该值
- 可以赋值
has_value()(或operator bool()) :检查是否包含值value():返回所包含的值;如果为空,则抛出std::bad_optional_access异常operator*()和operator->():解引用操作符,返回所含值的引用或指针;如果为空,行为是未定义的value_or(U&& default_value):如果包含值,则返回该值;否则返回提供的默认值emplace(...):在std::optional对象内部直接构造值,避免了拷贝或移动reset():使std::optional对象变为空swap():与另一个std::optional对象交换内容- 单一操作(支持链式操作
) :and_then():若存在包含值,则返回给定函数作用于该值的结果;否则返回一个空的std::optionaltransform():返回一个包含转换后的std::optional类型的值(如果存在) ,否则返回空的std::optionalor_else():如果std::optional类型对象本身包含值,则返回其本身,否则返回给定函数的结果
例子
#include <iostream>
#include <optional>
#include <string>
// 一个可能返回字符串的函数
std::optional<std::string> getName(bool giveName) {
if (giveName) {
return "Alice"; // 隐式转换为 std::optional<std::string>
} else {
return std::nullopt; // 表示没有值
}
}
int main() {
std::optional<std::string> name1 = getName(true);
std::optional<std::string> name2 = getName(false);
// 检查是否有值
if (name1.has_value()) { // 或者直接 if (name1)
std::cout << "Name 1: " << name1.value() << std::endl; // 安全访问
// 也可以使用 *name1 或 name1-> (如果 T 是类/结构体)
std::cout << "Name 1 (using *): " << *name1 << std::endl;
} else {
std::cout << "Name 1 is not available." << std::endl;
}
if (name2) { // 更简洁的检查方式
// 这段代码不会执行
std::cout << "Name 2: " << *name2 << std::endl;
} else {
std::cout << "Name 2 is not available." << std::endl;
}
// 使用 value_or 提供默认值
std::cout << "Name 1 (or default): " << name1.value_or("Default Name") << std::endl;
std::cout << "Name 2 (or default): " << name2.value_or("Default Name") << std::endl;
// 尝试访问空 optional 的 value() 会抛出异常
try {
std::cout << "Trying to access name2.value(): " << name2.value() << std::endl;
} catch (const std::bad_optional_access& e) {
std::cerr << "Exception: " << e.what() << std::endl;
}
// std::optional 也可以包含非类类型
std::optional<int> maybeInt;
if (!maybeInt) {
std::cout << "maybeInt is empty." << std::endl;
}
maybeInt = 42;
if (maybeInt) {
std::cout << "maybeInt has value: " << *maybeInt << std::endl;
}
return 0;
}
#include <iostream>
#include <optional>
#include <string>
#include <algorithm>
std::optional<std::string> to_upper_opt(const std::string& s) {
if (s.empty()) return std::nullopt;
std::string upper_s = s;
std::transform(upper_s.begin(), upper_s.end(), upper_s.begin(), ::toupper);
return upper_s;
}
int main() {
std::optional<std::string> input_opt = "hello";
auto result = input_opt
.and_then(to_upper_opt) // 1. 如果有值且非空,转大写(返回 optional<string>)
.transform([](const std::string& s) { // 2. 如果有值,获取其长度(返回 optional<size_t>)
std::cout << " transform: Getting length of '" << s << "'" << std::endl;
return s.length(); // lambda 表达式返回 size_t, transform 包装为 optional<size_t>
})
.or_else([]() -> std::optional<size_t> { // 3. 如果前面任一步骤导致空,则执行此步骤
std::cout << " or_else: Input was empty or processing failed, providing default length 0" << std::endl;
return 0; // or_else 的 lambda 表达式必须返回 optional
});
if (result) {
std::cout << "Final result (length or default): " << *result << std::endl;
} else {
// 理论上,由于 or_else 总会提供一个值(除非 or_else 本身返回 nullopt),这里不太会执行
std::cout << "Final result is unexpectedly empty." << std::endl;
}
std::cout << "---" << std::endl;
return 0;
}
使用 std::optional 有以下好处:
- 语义清晰:明确表达了“可能有,也可能没有”的语义
- 类型安全:强制使用者处理值不存在的情况,减少了因忘记检查而导致的错误
- 避免了空指针的许多问题:虽然
operator*对空optional是未定义行为,但value()提供了安全的访问方式,并且has_value()鼓励检查 - 值语义:
std::optional本身是值类型,易于拷贝和传递 - 效率:通常比使用指针和动态分配更高效,特别是当
T是小对象时
但使用时还要关注这些注意事项:
- 大小开销:
std::optional<T>的大小通常是sizeof(T)加上一个用于表示是否有值的布尔标记(可能还有对齐的填充字节,不过这个开销很小,可以忽略不计) - 未定义行为:如果在不检查
has_value()的情况下直接使用operator*或operator->访问一个空的std::optional,其行为是未定义的- 推荐使用
value()(会抛异常)或先检查再访问。
- 推荐使用
- 不适用于所有“可选”场景: 如果“没有值”是一种程序错误,应该抛出异常,而不是返回一个空的
std::optional;std::optional更适合表示“预期中的缺失” - 嵌套
std::optional:std::optional<std::optional<T>>是合法的,但可能表示过于复杂的逻辑,需要仔细考虑其语义 - 与 C 风格 API 的交互:当与期望指针或特殊返回值的旧 API 交互时,可能需要一些转换代码
Structs⚓︎
结构体(struct) 本质上就是将多个具名变量绑定在一起,构成一个新类型。
结构体初始化的两种方式:
在 C++ 中,我们还能为结构体定义成员函数(方法)
struct zjuIDCard {
string name;
string type;
int idNumber;
void display() {
cout << "Name: " << name << "\nType: " << type
<< "\nID: " << idNumber << endl;
}
};
成员函数还可以在结构体外定义,但是要用到解析符 :: 指明对应的结构体:
struct zjuIDCard {
string name;
string type;
int idNumber;
void display();
};
void zjuIDCard::display() {
cout << "Name: " << name << "\nType: " << type
<< "\nID: " << idNumber << endl;
}
到这里为止,我们得到的结构体已经具备了一个类该有的特征。由于这涉及到后面的知识,我们之后再来介绍。
更多内容:struct 声明
std::pair⚓︎
对于只有两个字段的结构体,我们可以用 C++ 自带的 std::pair 类型来替代,使用起来更加方便!
严格地说,std::pair 不是一种类型,而是一种模板(template)(这一概念在之后会详细讲解
template <typename T1, typename T2>
struct pair {
T1 first;
T2 second;
};
std::pair<std::string, int>
不要忘记在使用 std::pair 前在程序开头加一句 #include <utility>
更多内容:std::pair
Namespace⚓︎
在大型程序中,不同模块可能会定义相同名字的变量或函数,比如 print()、data、init() 等。C++ 引入了命名空间(namespace) 的概念,将这些名称划分为多个组(即名称空间::,用于指明具体的命名空间。
例子
namespace A {
void print() {
std::cout << "A's print" << std::endl;
}
}
namespace B {
void print() {
std::cout << "B's print" << std::endl;
}
}
int main() {
A::print(); // 调用 A 的 print
B::print(); // 调用 B 的 print
return 0;
}
运行结果:
- 命名空间的定义一般放在头文件内
- 命名空间可以嵌套。使用嵌套命名空间的成员时要按嵌套顺序指明命名空间,中间用
::间隔 - 若想使用命名空间的单个成员,可以用
using语句引入,之后使用该成员时就无需加命名空间的前缀了 - 而想引入整个命名空间的话,那就用
using namespace xxx;语句,该命名空间的所有成员在使用时都无绪添加前缀- 虽然很方便,但正如前面所说的,不推荐这样做;推荐的做法是使用
using语句引入必要的成员
- 虽然很方便,但正如前面所说的,不推荐这样做;推荐的做法是使用
- 匿名命名空间:没有名称的命名空间,只能在定义该命名空间的文件内被使用
更多内容:Namespaces
std⚓︎
std 是我们最常用的命名空间,它为我们提供了 C++ 标准库内的东西,包括一些内建类型、函数等等。
- 除去一些基本类型外,在使用内建类型前,需要用
#include导入相关的头文件,比如:#include <string>->std::string#include <utility>->std::pair#include <iostream>->std::cout,std::endl
-
std里会存在这样的内容: -
可以看到,在使用这些内建类型的时候,我们必须加上前缀
std::。 - 如果在程序开头使用语句
using namespace std;的话,我们就没有加前缀的必要了。但这样做被认为是一种不良的程序设计,因为这会带来歧义,尤其是在有多个命名空间的情况。 - 更多内容:standard_library
Initialization⚓︎
初始化(initialization):在构造对象时为对象提供初始值的过程。
由于读取未初始化的值会产生未定义的行为,因此无论知不知道 C++ 在什么情况下会为自动初始化,还是强烈建议手动初始化。
C++ 提供了以下几种初始化方式:
- 直接初始化(direct initialization)
- 统一初始化(uniform initialization)
- 结构化绑定(structured binding)
注
这里的初始化方式主要针对的是内置类型。至于自定义类,请移步至“类和对象”一节对应部分。
更多内容:Initialization
Direct Initialization⚓︎
#include <iostream>
int main() {
int numOne = 12;
int numTwo(12);
std::cout << "numOne is: " << numOne << std::endl;
std::cout << "numTwo is: " << numTwo << std::endl;
return 0;
}
高亮的两行就是直接初始化的两种方式:
- 使用赋值号
=:和 C 语言一样 - 使用圆括号
():看起来像函数调用,也类似创建自定义类对象的构造函数(但实际上内建类型并没有构造函数)
这种初始化方法有一种特性,叫做缩窄转换(narrowing conversion)——C++ 不会进行类型检查,而是尝试将初始化值隐式转换为指定的类型(比如:int num(42.5); -> num == 42
Uniform Initialization⚓︎
统一初始化是 C++11 标准引入的特性。
#include <iostream>
int main() {
// Notice the brackets
int numOne{12};
std::cout << "numOne is: " << numOne << std::endl;
return 0;
}
可以看到,统一初始化需要用到花括号 {},此时 C++ 会进行类型检查且不支持类型转换。所以像 int num(42.5); 这句话就无法通过编译,报错信息类似:
test.cpp:5:13: error: type 'double' cannot be narrowed to 'int' in initializer list [-Wc++11-narrowing]
5 | int num{42.0};
| ^~~~
test.cpp:5:13: note: insert an explicit cast to silence this issue
5 | int num{42.0};
| ^~~~
| static_cast<int>( )
所以,统一初始化有以下优点:
- 安全(safe):不允许缩窄转换,从而避免意外行为或致命系统错误的发生
- 泛用(ubiquitous):作用于所有类型,包括
vector、map,以及自定义类等
例子
Structured Binding⚓︎
结构化绑定是 C++17 引入的新特性:
- 它提供了一种在编译时从具有固定大小的数据结构中初始化一些变量的有用方法
- 具备同时访问函数返回的多个值的能力
- 能作用在编译时大小已知的对象上
结构化绑定的语法为:
例子
std::tuple<std::string, std::string, std::string> getClassInfo() {
std::string className = "CS106L";
std::string buildingName = "Thornton 110";
std::string language = "C++";
return {className, buildingName, language};
}
int main() {
auto [className, buildingName, language] = getClassInfo();
std::cout << "Come to " << buildingName << " and join us for " << className
<< " to learn " << language << "!" << std::endl;
return 0;
}
高亮所示语句用到了结构化绑定的特性,可以看到三个在方括号内的变量可以依次接收函数的返回值(包含三个 string 的元组
结构化绑定和 Python 的拆包(unpacking) 十分相似。
区分初始化和赋值
| 特征 | 初始化 (initialization) | 赋值 (assignment) |
|---|---|---|
| 时机 | 对象创建时 | 对象已存在后 |
| 目的 | 赋予初始值,使对象进入有效状态 | 赋予新值,改变对象现有状态 |
| 次数 | 一次 | 多次 |
| 调用 | 构造函数(对于类类型) | 赋值运算符(对于类类型) |
| 资源 | 获取资源(如果需要) | 释放旧资源,获取新资源(对于管理资源的类) |
| 语法 | T obj(args); T obj = val; T obj{args}; new T(); |
obj = val; obj += val; |
| 语义 | 创建并设置初始状态 | 修改已存在对象的状态 |
建议:尽量延后变量定义的出现时机
试想一下:假如你先声明了一个变量,但没有立马对它做点什么(初始化 / 赋值等等,此时可能调用了这个变量对应的默认构造函数
为了避免这种情况,最佳实践是尽可能延后变量的定义,直到能够立马给它一个初始值时为止。这样不仅可以避免多余的构造,还避免了无意义的默认构造行为。
然而,如果将循环考虑进来,事情就变得更复杂了:
比较一下两种写法的成本:
- 法 A:1 个构造函数 + 1 个析构函数 + n 个赋值操作
- 法 B:n 个构造函数 + n 个析构函数
总的建议是:除非知道赋值成本 < “构造 + 析构”的成本,或者知道哪部分代码对性能要求较高,否则建议采用法 B
Strings⚓︎
- C++ 中,字符串有专门的类,叫作
string- 在 C++ 中,强烈建议使用
string类表示字符串,因为它是真正的字符串类型。而在 C 语言中实际上没有字符串类型,只是用字符数组和字符指针来模拟字符串,而且后者不太安全 - C++ 字符串末尾没有
\0字符。事实上,除了 C 语言外,其他语言都是将字符串本身及其长度存在内存中,因此不用\0标记结尾
- 在 C++ 中,强烈建议使用
- 使用
string类时,必须在代码开头加上#include <string> - 定义字符串变量:
string str;- 这样声明后,字符串
str已经有确定的值了
- 这样声明后,字符串
-
使用字符串字面量初始化的三种方式:
其中前两种方式是等价的,且这两种方式适用于其他类型(比如
int等) -
赋值:
-
输入和输出
-
可以直接用
cin/cout读写 -
读取一整行字符串:
getline(cin, line_var)
注意
如果
cin之后用到getline,由于cin遇到空白字符时就停止往后读,输入流里可能还有未被读取的换行符,而getline将会读取一行字符串,直到遇到换行符。所以在使用getline前,应当先用cin.get()读取换行符(这个函数的功能是读取单个字符) ,然后再用getline。 -
-
获取字符串的单个字符:可以像字符数组一样访问字符串
-
字符串拼接 (concatenation)
-
获取长度:
s.length();- 在 C 中,
.运算符用于检索结构体内的成员 - 而在 C++ 中,它又是作为一个检索对象成员的运算符
小技巧
如果 vscode 中下载了 C/C++ 插件,那么编写代码时在对象后敲个
.后,vscode 就会显示该对象可用的所有成员。 - 在 C 中,
-
创建字符串(使用构造函数)
-
获取子字符串:
substr(int pos, int len); -
改变字符串:
-
寻找字符串
- 该函数会返回找到的指定字符串首字符在原字符串中的索引,如果未找到,则返回 -1
注
从子字符串开始的所有函数(更确切的说法是“方法”)都是字符串对象的成员,因此实际使用时要用 . 运算符访问:
更多内容:std::basic_string
Pointers⚓︎
-
指向对象的指针
-
指针运算符
&:获取地址(ps = &s;)*:获取对象((*ps).length())->:调用函数(ps->length())
-
对象和指针在声明时的区别
string s;:此时对象s被创建并被初始化- 但是像
int i;这样的声明的变量不会被初始化
- 但是像
string *ps;:此时对象ps还不清楚指向何处
-
赋值
-
nullptr(C++11 引入) :空指针常量,相比原有的空指针NULL更加安全且语义清晰。写 C++ 代码的时候强烈建议用这个表示空指针。
更多内容:pointer
Reference⚓︎
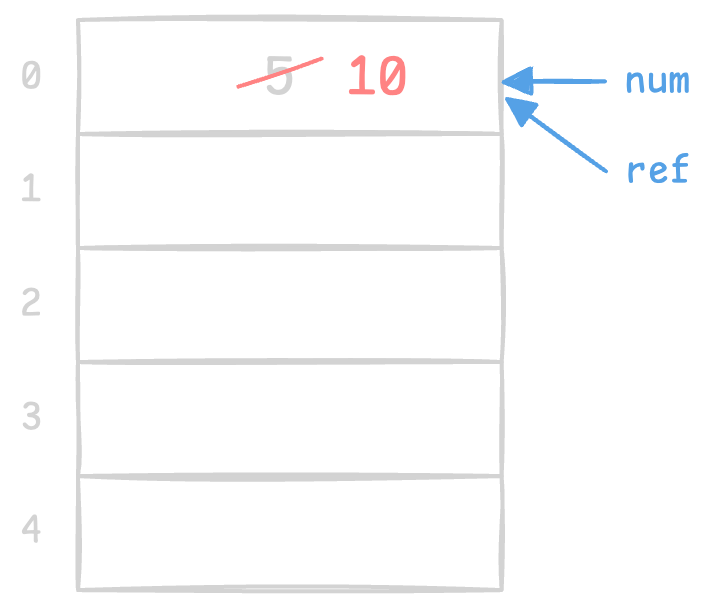
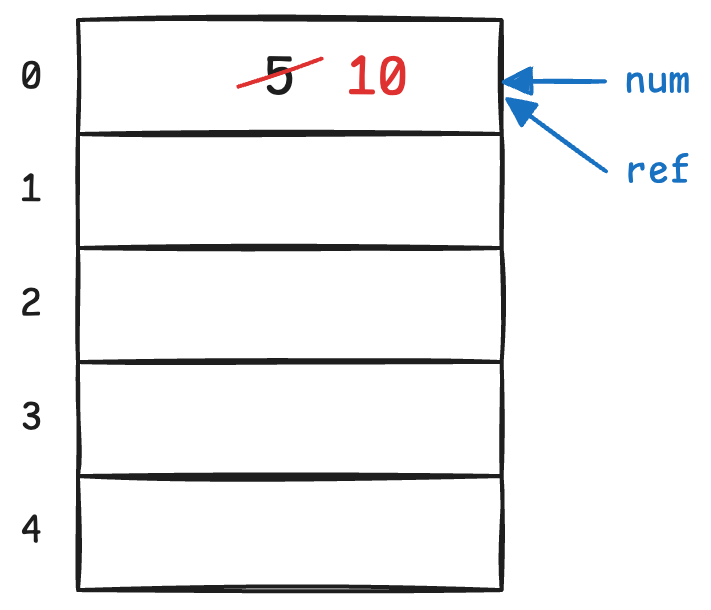
我们可以将引用(reference) 理解为:为一个已经存在的内存对象所创建的另一个名字,即别名(alias)。定义引用时,我们使用 & 符号。一旦一个引用被初始化并绑定到某个对象,它就和那个对象“绑定”了:对引用的任何操作,实际上都是直接作用于它所引用的原始对象。
int num = 5;
int& ref = num; // ref is an "alias" of num
ref = 10; // Assigning a new value through the reference
std::cout << num << std::endl; // Output: 10
用图形化的方式表述上述语句:
Pass by Reference⚓︎
引用最常见的用途之一是在函数参数传递中,实现所谓的“按引用传递(pass by reference)”。这种方式允许函数直接修改传递给它的实参,而不是操作实参的一个副本。
#include <iostream>
#include <math.h>
void squareN(int& n) {
// calculates n to the power of 2
n = std::pow(n, 2);
}
int main() {
int num = 2;
squareN(num);
std::cout << num << std::endl;
return 0;
}
正如示例所示,squareN 函数接收一个 int& 类型的参数。当调用 squareN(num) 时,函数内部的 n 成为了 main 函数中 num 的别名。因此 squareN 对 n 的修改直接作用于 num 上。
虽然通过传递指针也能实现函数内修改实参,但按引用传递通常:
- 更便捷:语法上更接近普通变量的操作,无需显式的解引用操作符(
*) - 更安全:
- 引用在定义时必须被初始化,且不能绑定到
nullptr,减少了空指针异常的风险 - 引用一旦绑定,就不能再重新绑定到其他对象,避免了指针可能被意外重指向的问题
- 引用在定义时必须被初始化,且不能绑定到
注意
按指针传递本质上仍是按值传递(pass by value)——传递的是指针这个地址值的副本。
Structured Binding and Reference⚓︎
当在 for 循环中使用结构化绑定来解包类似 std::pair 或 std::tuple 的元素时,需要考虑:我们是否希望修改原容器中的元素。考虑以下情况:
#include <iostream>
#include <vector>
#include <utility>
// 初始版本,尝试修改元素
void shift_buggy(std::vector<std::pair<int, int>>& nums) {
// 这里的 auto [num1, num2] 默认创建的是 pair 中元素的副本
for (auto [num1, num2] : nums) {
num1++; // 修改的是副本 num1
num2++; // 修改的是副本 num2
}
// nums 容器中的原始 pair 元素并未改变
}
调用该函数后,我们发现实参内的元素并没有像预期那样被修改,因为结构化绑定会绑定元素的副本,而不是元素本身,所以里面的内容没有任何改动。正确的做法是在 for 语句内部也要做一次引用,让 [num1, num2] 绑定的是 pair 的引用,这样对 num1 和 num2 的修改也能作用在传入的元素上了。
void shift_correct(std::vector<std::pair<int, int>>& nums) {
// 使用 auto& 确保 [num1, num2] 绑定到原始 pair 内部成员的引用(间接)
// 或者更准确地说,是 pair 的引用,然后 num1, num2 成为其成员的别名
for (auto& pair_ref : nums) { // 首先获取对 vector 中每个 pair 元素的引用
pair_ref.first++;
pair_ref.second++;
}
}
// 或者,如果编译器支持直接在结构化绑定中使用引用(C++17及之后更常见于此场景):
void shift_structured_binding_ref(std::vector<std::pair<int, int>>& nums) {
for (auto& [num1, num2] : nums) { // num1 和 num2 现在是原始 pair 成员的别名/引用
num1++;
num2++;
}
}
另一种等价的修改方式
L-Value and R-Value⚓︎
- 左值(lvalue):
- 指代那些在表达式求值后依然存在、拥有可识别的内存位置的对象
- 可以出现在赋值操作符(
=)的左侧(作为赋值目标)或右侧(作为值来源) - 例子:变量名、返回左值引用的函数调用、数组元素、解引用的指针、对象成员
- 右值(rvalue):
- 通常指代那些在表达式求值后不再持久存在的临时值或字面常量
- 通常只能出现在赋值操作符的右侧
- 例子:字面常量、算术表达式的结果、返回非引用类型的函数调用(其返回值是临时的)
关于字符字面量
像 "abc" 这样的字符字面量比较特殊:虽然它们属于右值,但是它们被存储在一块(只读的)静态内存区,而其他字面量则不具备这一特性。这是因为:
- 字符字面量具备多字符序列的特性,需要一块独立的、连续的内存来存储,并且为了效率和资源优化,这块内存被放在静态区并标记为只读。
- 而其他字面量是单一的值,可以在编译时直接处理或编码到指令中,无需在运行时占用额外的静态内存空间来“存储自身”(也就是说编译器不会为它们分配内存
) 。
Pop Quiz!
找出哪些是左值,哪些是右值:
Left Value Reference⚓︎
我们通常所说的“引用”默认是指左值引用,用 T& 表示。
左值引用的核心规则为:非 const 的左值引用通常不能绑定到右值。因为右值是临时的,允许一个非 const 左值引用绑定到它,就可能意味着试图修改一个即将销失的临时对象,而这通常是没有意义的或危险的。
#include <stdio.h>
#include <cmath>
#include <iostream>
int squareN(int& num) {
return std::pow(num, 2);
}
int main() {
int lValue = 2;
auto four = squareN(lValue);
auto fourAgain = squareN(2); // error!
std::cout << four << std::endl;
return 0;
}
高亮行中 squareN(2) 传递了右值 2,但该函数接收的是一个左值引用,因此在编译时会报错:
test.cpp:12:22: error: no matching function for call to 'squareN'
12 | auto fourAgain = squareN(2); // error!
| ^~~~~~~
test.cpp:5:5: note: candidate function not viable: expects an lvalue for 1st argument
5 | int squareN(int& num) {
| ^ ~~~~~~~~
1 error generated.
左值引用的规则为:
-
必须初始化:引用在定义时就必须被初始化,明确它指代哪个对象;一旦初始化,它就和那个对象永久绑定
-
绑定不可更改:一个引用在初始化后,不能再被重新绑定到另一个不同的对象;它始终是其初始对象的别名
-
引用的目标必须有明确的内存位置:这意味着引用通常绑定到左值
指针 vs 引用
| 特性 | 引用(&) |
指针(*) |
|---|---|---|
| 空值 | 不能为 nullptr;必须引用一个实际存在的对象 |
可以为 nullptr,表示不指向任何有效对象 |
| 初始化 | 必须在定义时初始化 | 可以在定义时不被初始化(但通常不推荐,因为这样容易产生野指针) |
| 重新绑定 | 初始化后不得重新绑定到其他对象 | 可以在生命周期内改变,指向不同对象和地址 |
| 内存占用 | 通常不占用额外内存 | 占用与地址大小相当的内存空间 |
| 操作 | 使用时如同原始对象,无需特殊操作符 | 访问所指对象需要使用解引用操作符(*) |
| 算术运算 | 不支持算术运算 | 支持指针算术运算 |
引用的限制
- 不能有“引用的引用”:虽然可以写出类似
typedef int& IntRef; IntRef& anotherRef = someInt;的代码,但anotherRef的类型仍然是int&(引用会“折叠”) 。而且从概念上讲,不存在直接的“引用的引用”类型。 -
不能有指向引用的指针:表达式如
int &*p; 是非法的,因为引用本身不是一个可以获取其地址的对象。- 但是,对指针的引用是完全合法的,并且非常有用,例如在函数中修改指针本身(让它指向另一个地址)
-
不能有引用数组:声明如
int& ref_array[3];是非法的。- 但是,可以有“数组的引用”
归根到底,这些限制的缘由都是“引用本身不是一个可以获取其地址的对象”。
Right Value Reference⚓︎
为了支持移动语义(move semantics) 和完美转发 (perfect forwarding),C++11 引入了右值引用,用 T&& 表示。其核心目的是:右值引用可以绑定到即将销毁的右值(临时对象
基本用法:
int x = 20; // x 是一个左值
// int&& rr_error = x; // 编译错误: 右值引用不能直接绑定到左值
int&& rr1 = 10; // 正确: 10 是一个右值(字面常量)
int&& rr2 = x * 2; // 正确: x * 2 的结果是一个右值(临时表达式结果)
// rr1 和 rr2 现在延长了这些临时右值的生命周期
// std::move 的作用:将左值无条件转换为右值引用类型,常用于“窃取”资源
int&& rr3 = std::move(x); // 正确: std::move(x) 将左值 x 转换为右值引用类型
// 注意:此时 x 的状态可能变得不确定,不应再依赖其原有值
rr1 = 100; // 重要:一旦右值引用被初始化并拥有了名字 (如 rr1, rr2),
// 这个具名的右值引用本身就成了一个左值!因此可以被赋值。
int y = rr1 + 2; // 可以像普通变量一样使用它
右值引用使得我们可以根据参数是左值还是右值来重载函数,这对于实现移动语义至关重要。
例子
#include <iostream>
void func_for_refs(int& lref) { // 版本1: 接受左值引用
std::cout << "调用 func_for_refs(int&): 参数是左值" << std::endl;
}
void func_for_refs(int&& rref) { // 版本2: 接受右值引用
std::cout << "调用 func_for_refs(int&&): 参数是右值" << std::endl;
// 在函数内部,具名参数 rref 本身是一个左值
// 如果要将其作为右值传递给其他函数,需要使用 std::move(rref)
}
int main() {
int var = 10;
func_for_refs(var); // 调用版本1 (参数 var 是左值) -> 输出: 调用 func_for_refs(int&): 参数是左值
func_for_refs(20); // 调用版本2 (参数 20 是右值) -> 输出: 调用 func_for_refs(int&&): 参数是右值
func_for_refs(std::move(var)); // 调用版本2 (std::move(var) 将 var 转为右值引用类型)
// -> 输出: 调用 func_for_refs(int&&): 参数是右值
return 0;
}
Dynamically Allocated Memory⚓︎
-
new:为运行时程序分配内存空间,并且在该内存上调用一个或多个构造函数- 指针是唯一能够访问这种内存空间的途径,因此该操作的返回值便是指向这块内存空间的指针
- 如果是分配的是数组,那么指针指向的是第一个元素的内存地址
-
delete:先在内存空间上调用一个或多个析构函数,然后释放内存 -
{}用于向使用new生成的对象传递初始值
注意 new 和 delete 的搭配:
int *p = new int;
int *a = new int[10];
Student *q = new Student();
Student *r = new Student[10];
delete p;
a++;
delete[] a;
delete q;
delete r;
delete[] r;
使用提示
- 不要用
delete释放不是用new分配的内存 - 不要用
delete连续释放两次相同的内存块 - 如果使用
new []来分配数组的话,就必须用delete [] - 如果使用
new来分配单个实体的话,就必须用delete - 在空指针
nullptr上使用delete是安全的(无事发生) - 理论上
new分配的内存空间在程序结束时不会被自动释放(但实际上操作系统会回收该程序占据的所有内存资源,包括这块没有被释放的空间) 。所以程序中有了new就务必要用对应的delete。
更多内容:
Build Automation Tools⚓︎
注
这是一份关于 GNU Make 和 CMake 的速成介绍(是的,这里仅介绍这两个最常用的自动化构建工具(build automation tools)
另外,这里也不会介绍如何安装 GNU Make 和 CMake,请自行到网上搜索安装方法。
- 对于 macOS,GNU Make 应该是已经装好的(和其他 Linux 发行版一样
) ;CMake 可以用 Homebrew 直接安装。
GNU Make and Makefile⚓︎
为什么要用 make 命令行工具
想象一下,我们的 C++ 项目中包含了多个源文件(.cpp, .hg++ main.cpp utils.cpp helper.cpp -o my_program
make 就是一个帮你自动化这个过程的工具。它读取一个名为 Makefile 的特殊文件,这个文件告诉 make 如何编译 C++ 项目。
而 Makefile 本质上是一系列规则,每条规则包含:
- 目标(target): 通常是我们想要生成的文件,比如可执行程序或对象文件(.o)
- 依赖(dependencies): 生成目标所需要的文件
- 如果任何依赖文件比目标文件新,
make就会执行这条规则
- 如果任何依赖文件比目标文件新,
- 命令(commands): 生成目标的具体指令,通常是编译器命令
- 注意:命令前必须是 Tab 字符,而不是空格!
例子
假设某个 C++ 项目由 main.cpp 和 functions.cpp,以及 functions.h 这些文件构成
# 编译器变量(可选,但推荐使用)
CXX = g++
CXXFLAGS = -Wall -std=c++17 # 编译选项
# 目标:my_program
my_program: main.o functions.o
$(CXX) $(CXXFLAGS) main.o functions.o -o my_program
# 目标:main.o(对象文件)
main.o: main.cpp functions.h
$(CXX) $(CXXFLAGS) -c main.cpp -o main.o
# 目标:functions.o(对象文件)
functions.o: functions.cpp functions.h
$(CXX) $(CXXFLAGS) -c functions.cpp -o functions.o
# clean 规则(可选,用于清理生成的文件)
clean:
rm -f my_program main.o functions.o
使用 make 时可遵循以下步骤:
- 创建 Makefile: 在项目根目录下创建名为 Makefile 的文件,并写入上述规则。
- 执行
make:在终端中,进入项目根目录,然后输入:make或make my_program- (如果
my_program是第一个目标,可以直接用make) make会检查依赖关系,只重新编译必要的部分
- (如果
make clean- 执行
clean规则,删除生成的文件
- 执行
make 有以下优点:
- 增量编译:只重新编译修改过的文件及其依赖项,节省时间
- 自动化:一条命令完成整个编译过程
- 定义规则:清晰地描述项目如何构建
拓展阅读:GNU Autotools: a tutorial
CMake⚓︎
make 的问题
当项目变得更大、更复杂,或者需要在不同操作系统、不同编译器上构建时,手写 Makefile 会变得非常困难和不灵活。
因此,下面将介绍一种更为高效的自动化编译工具——CMake!
CMake 是一个跨平台的构建、测试和打包工具。它并不会直接编译 C++ 代码,而是生成特定构建系统(比如 Makefile,或者 Visual Studio 的项目文件等)所需的配置文件。
CMake 通过读取一个名为 CMakeLists.txt 的文件来了解项目内容。这个文件使用 CMake 特有的命令语言编写,具体可见下面的例子:
例子
同样假设项目里有 main.cpp 和 functions.cpp 文件。其对应 CmakeLists.txt 的内容为:
# 最低 CMake 版本要求
cmake_minimum_required(VERSION 3.10)
# 项目名称
project(MyAwesomeProject)
# 设置 C++ 标准(可选)
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_CXX_STANDARD_REQUIRED True)
# 添加可执行文件目标
# add_executable(<可执行文件名> <源文件1> <源文件2> ...)
add_executable(my_program main.cpp functions.cpp)
# 如果有头文件目录需要指定(虽然这个简单例子不太需要,但在实际项目中可能会经常用到)
# include_directories(include)
# 如果有库需要链接(同样,这个例子也不太需要——
# target_link_libraries(my_program some_library)
使用 CMake 时遵循以下步骤:
- 创建 CMakeLists.txt: 在项目根目录下创建名为 CMakeLists.txt 的文件。
-
创建构建目录:在项目根目录下,创建一个新的目录用来存放构建生成的文件(通常命名为 build
) 。 -
运行
cmake生成构建文件: 在 build 目录中,运行cmake命令,并指向包含 CMakeLists.txt 的上级目录。这会在 build 目录下生成 Makefile(或其他平台的构建文件
) 。 -
运行
可执行文件 my_program 会生成在 build 目录中。make(或其他构建工具) :仍然在 build 目录中,现在可以使用make(或其他由 CMake 生成的构建系统对应的命令)来编译你的项目了。
CMake 的核心优势有:
- 跨平台:同一个 CMakeLists.txt 可以在不同操作系统和编译器上生成相应的构建文件
- 更高级的抽象:相比直接写 Makefile,使用 CMake 能更容易地管理复杂的项目、依赖库和编译选项
- 自动查找依赖:CMake 可以帮助我们查找和配置外部库
- 广泛支持:许多流行的 C++ 库和项目都使用 CMake
Miscellaneous⚓︎
Getting Rid of #define from Your Code⚓︎
我们知道,#define 最主要的作用有 2 个:
- 作为常量(constants)
- 宏(macro) 定义
先考虑第 1 个作用——由于预处理器(preprocessor) 可能在编译前就将 #define 定义的记号名移除掉,用具体值替代,因此该记号在编译时就没有进入到符号表(symbol table) 内。此时,在使用这个常量时发生编译错误的话,报错消息只会提到这个具体值,而不包括记号名,这显然给我们的 debug 带来一些麻烦。当然,这个麻烦甚至可能也会影响到调试器的使用。
在 C++ 中,我们强烈建议使用 const 表示常量。它除了不会出现上面的问题外,还可能在编译时产生更少的目标码,因为预处理器可能会多次替换出现过的记号,不管这种替换是否符合上下文(它不在乎作用域 (scope) 等限制const 不可能会出现这种情况。
再来看第 2 个作用。宏看起来像函数,但使用宏并不是在调用函数,因而能够减小开销。但在书写宏的时候,我们需要谨慎地为所有实参加圆括号(比如#define MAX(a, b) f((a) > (b)) ? (a) : (b)
在 C++ 中,我们可以用模板内联函数(template inlining function) 来替代这种宏。对于上面的例子,我们可以改写成以下等价形式:
通过上述替换(使用 const、enum、inline 替换 define#include 还是不可或缺的,而ifdef / ifndef也还是会经常用到的。
Some Useful Rules⚓︎
- 80-20 经验法则:平均而言,一个程序往往将 80% 的执行时间花费在 20% 的代码上。
评论区