Data-Oriented Programming and Job System⚓︎
约 2731 个字 预计阅读时间 14 分钟
代码的执行并没有我们看上去那么简单。由于代码是执行在操作系统和硬件之上的,所以要想编写一份高性能的程序,必须要考虑到硬件和 OS。
Basics of Parallel Programming⚓︎
在学计算机系统时,我们认识了摩尔定律(Moore's Law):集成电路(IC)中的晶体管数量大约每两年翻一番。但是从最近十几年开始,这条定律逐渐失效,晶体管数量增长放缓,即将触碰到物理极限了。因而多核处理器(multi-core processors) 成为了新的工业发展趋势。
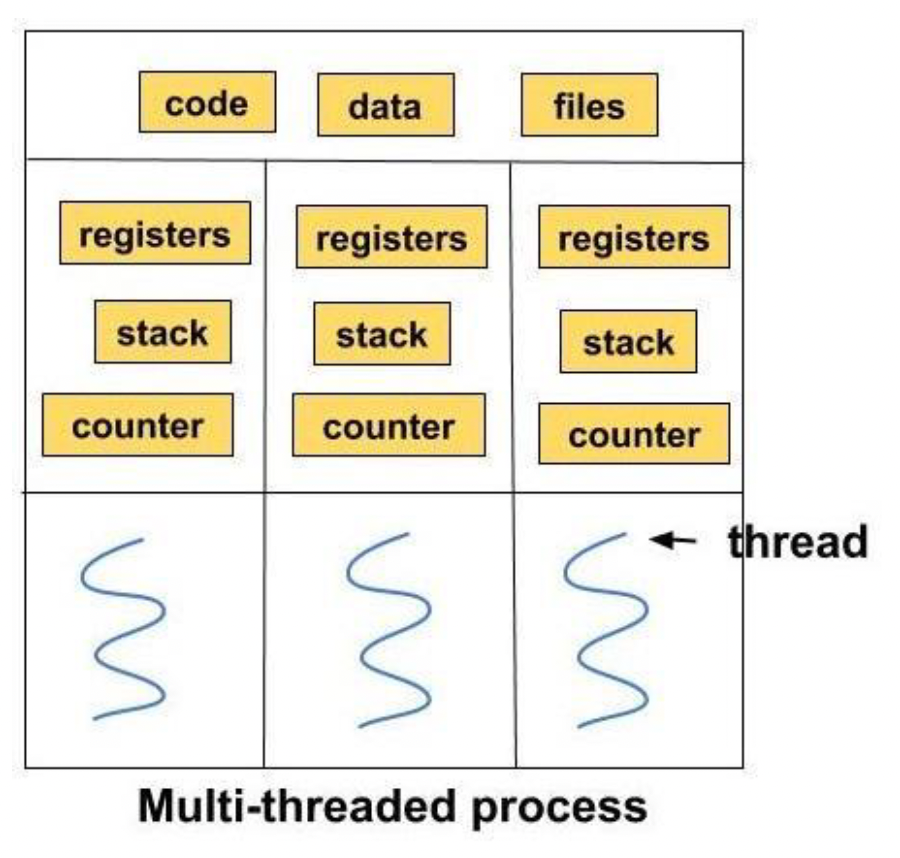
进程与线程
-
进程(process):
- 应用(或程序)的实例
- 有自己的内存区域
-
线程(thread):
- 抢占式多任务
- OS 任务调度的最小单位
- 必须位于进程中
- 相同进程中的线程共享内存
多任务的类型
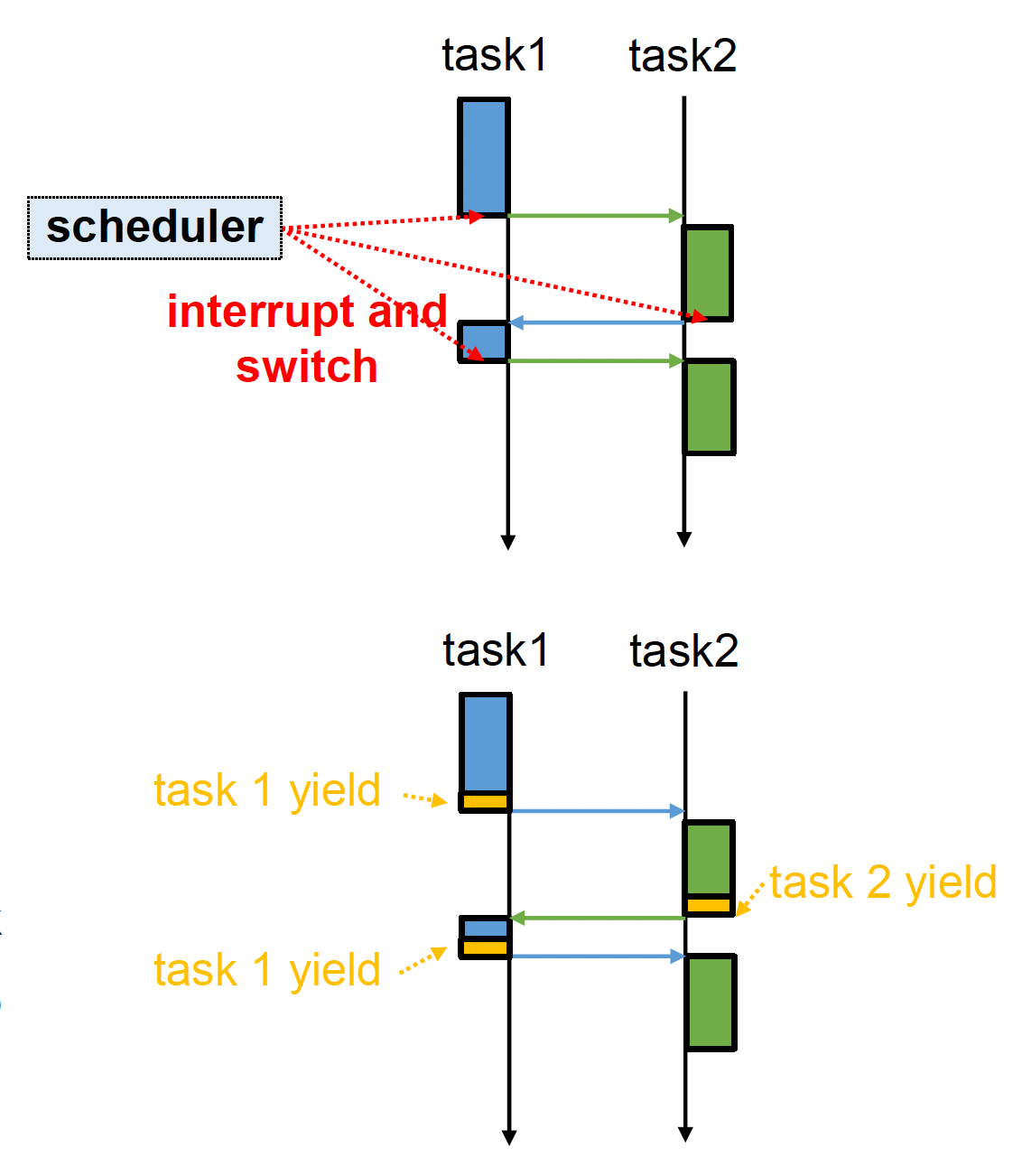
-
抢占式多任务(preemptive multitasking)
- 当前执行的任务可在调度器指定的时间后被中断 **
- 调度器接着决定下一个要执行的任务
- 该策略应用于大多数操作系统中
-
非抢占式多任务(non-preemptive multitasking)
- 任务必须被显式编程以让出控制权
- 任务之间需要协作才能使调度方案生效
- 目前许多实时操作系统(RTOS)也支持这种调度方式
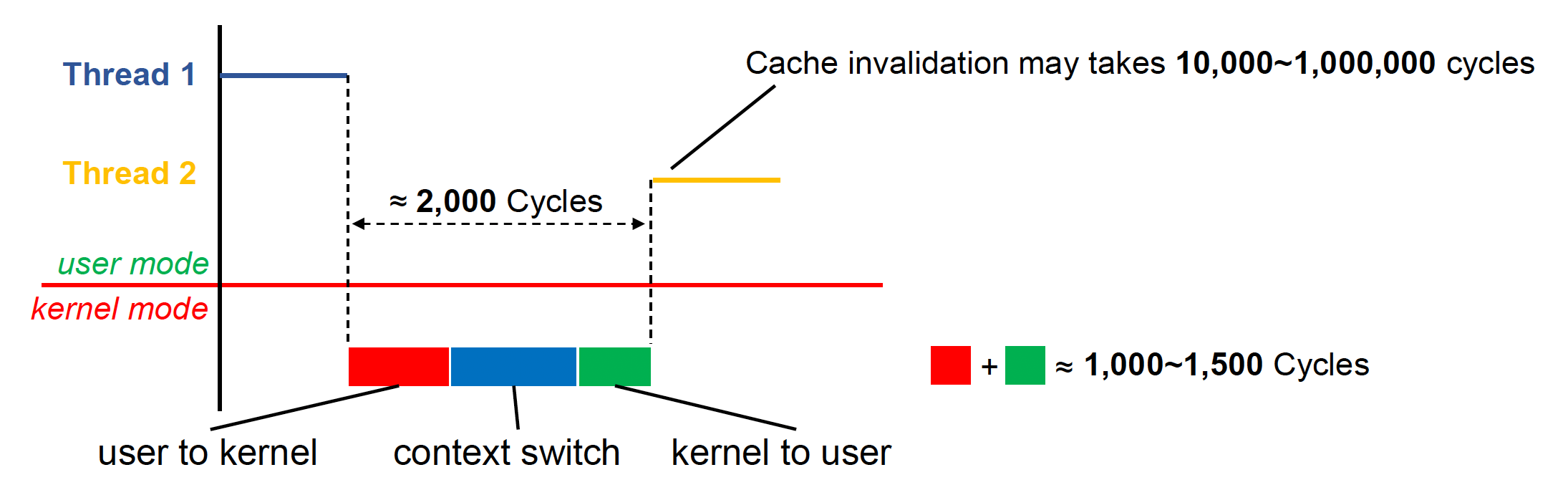
对于一个多线程程序,线程间的上下文切换(context switch) 自然是无法避免的事情。它是指保存当前线程状态,以便下次继续从此处开始执行的行为。更具体地,
- 状态包括寄存器、栈以及其他 OS 需要的数据
- 线程的上下文切换包含额外的用户 - 内核模式切换
- 上下文切换后的缓存失效 (cache invalidation) 成本更高(因为原来缓存里的数据很多时候对新线程而言毫无意义,所以一开始会有很多的缓存失效)
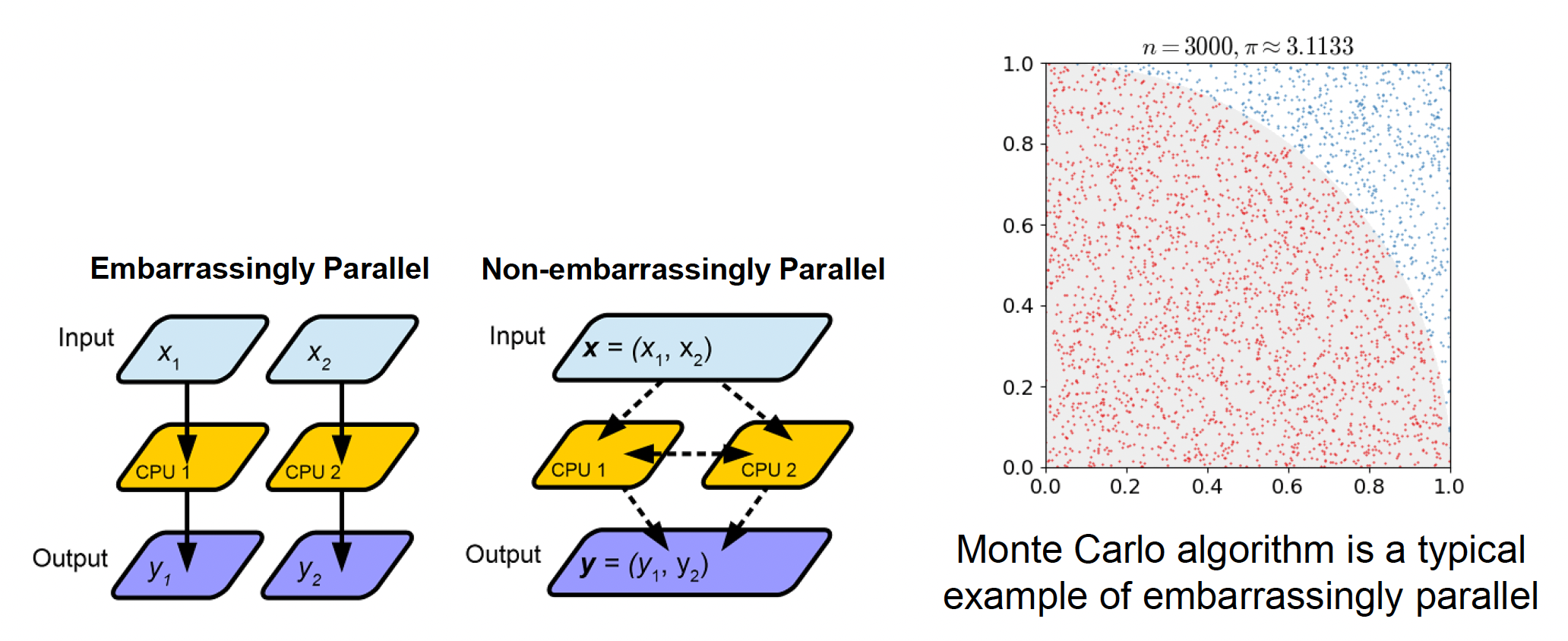
在并行计算中,我们经常会遇到以下并行问题:
- 令人尴尬的并行(embarrassingly parallel problem)(或完美并行 (perfect parallel)
) :并行任务之间几乎没有依赖关系或通信需求 - 不令人尴尬的并行(non-embarrassingly parallel problem):并行任务之间需要通信
常遇到的另一个问题是数据竞争(data racing),即多个线程同时访问相同的内存位置,并且其中至少有一个线程是在对其进行写操作。

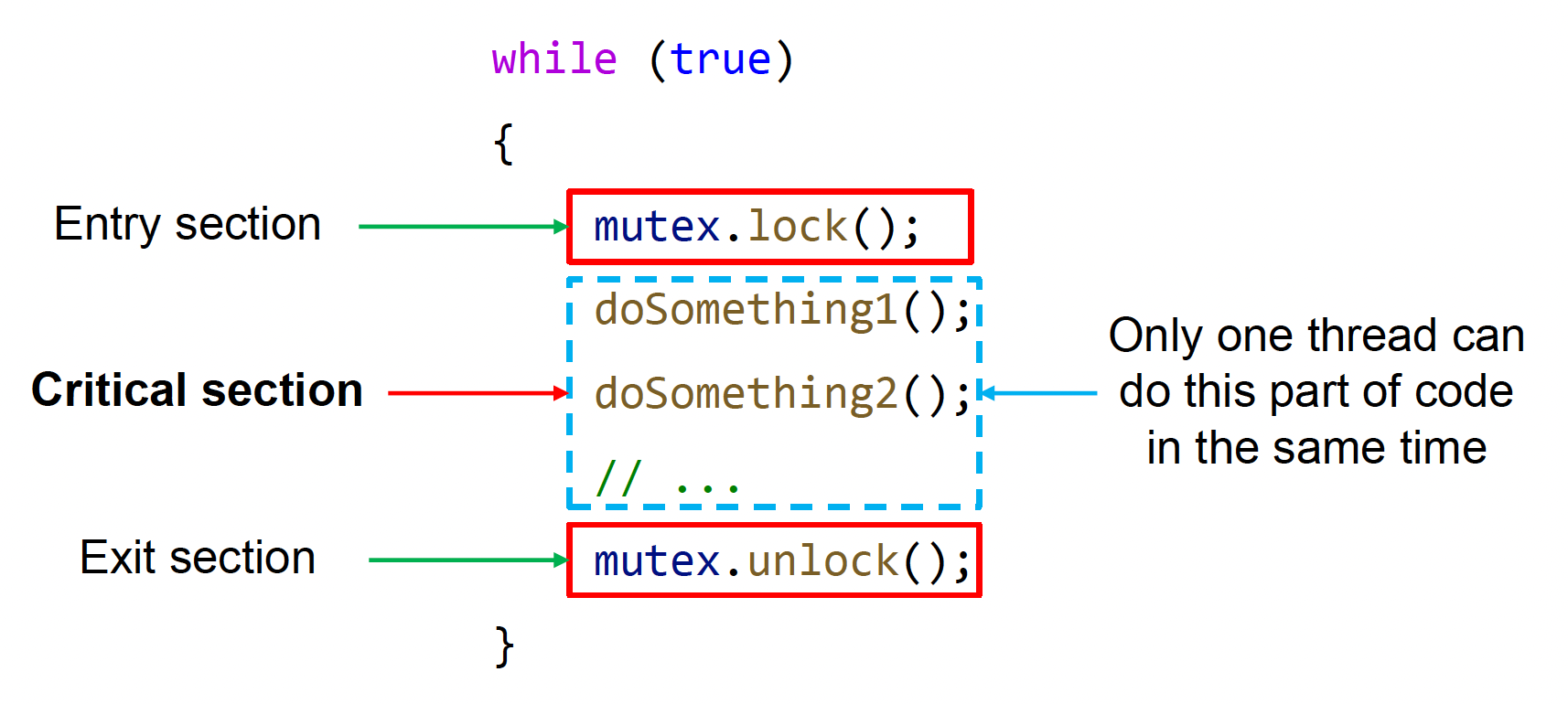
为避免这一问题,一种方法是采用叫做锁(lock) 的阻塞算法 (blocking algorithm)。
- 保证同一时间只有一个线程能获取锁
- 为共享资源访问部分设置一个临界区(critical section),只有拿到锁的线程才能进入这段代码
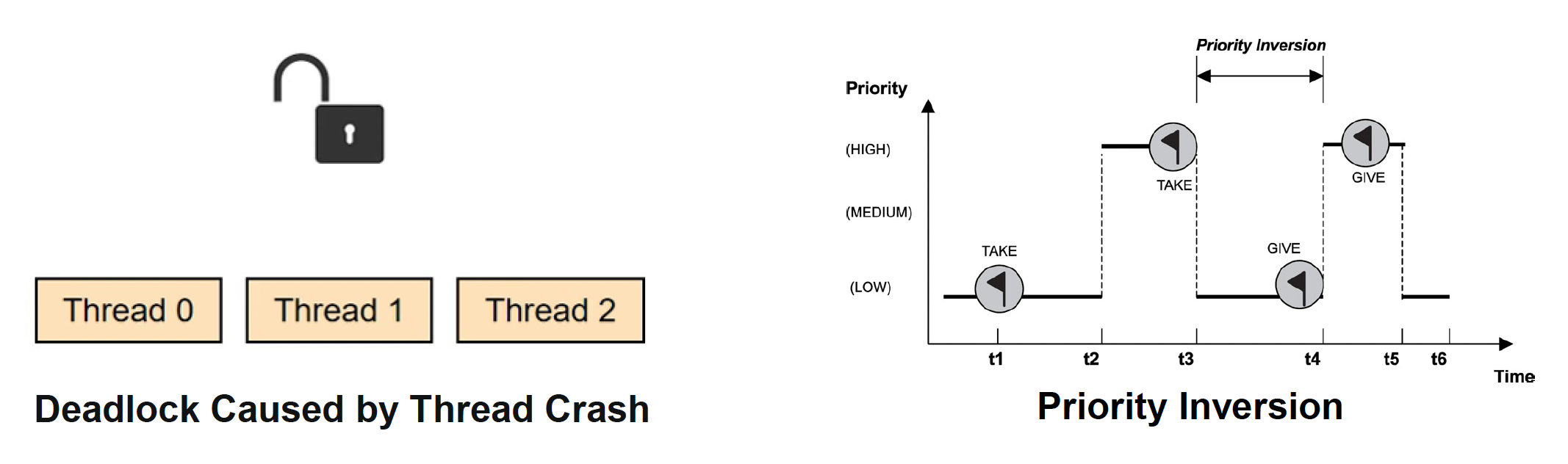
锁的问题
- 线程的挂起和恢复会带来额外的性能开销
- 若持有锁的线程异常退出,被挂起的线程将无法恢复
- 优先级反转问题:高优先级的任务可能会尝试获取已被低优先级的任务持有的锁
于是我们引入一种叫做原子操作(atomic operations) 的无锁(lock-free) 编程。常见的原子操作有:
-
原子加载和存储
- 加载(load):将数据从共享内存加载到寄存器或线程的特定内存中
- 存储(store):将数据移动至共享内存中
-
原子读 - 改 - 写 (read-modify-write, RMW)
- 测试并设置(test and set):将 1 设置到共享内存,并返回之前的值
- 比较并交换(compare and swap):若共享内存中的数据等于预期值,则更新该数据
- 获取并增加(fetch and add):将共享内存中的数据加上一个值,并返回之前的值
除了无锁编程外,还有无等待(wait-free) 编程。理论上它能保证所有线程尽可能占据所有的 CPU 资源。但实际上在一个复杂系统中,这是很难做到的,因此仅在部分对性能有极高要求的场合中用到,在这里我们不必深究。
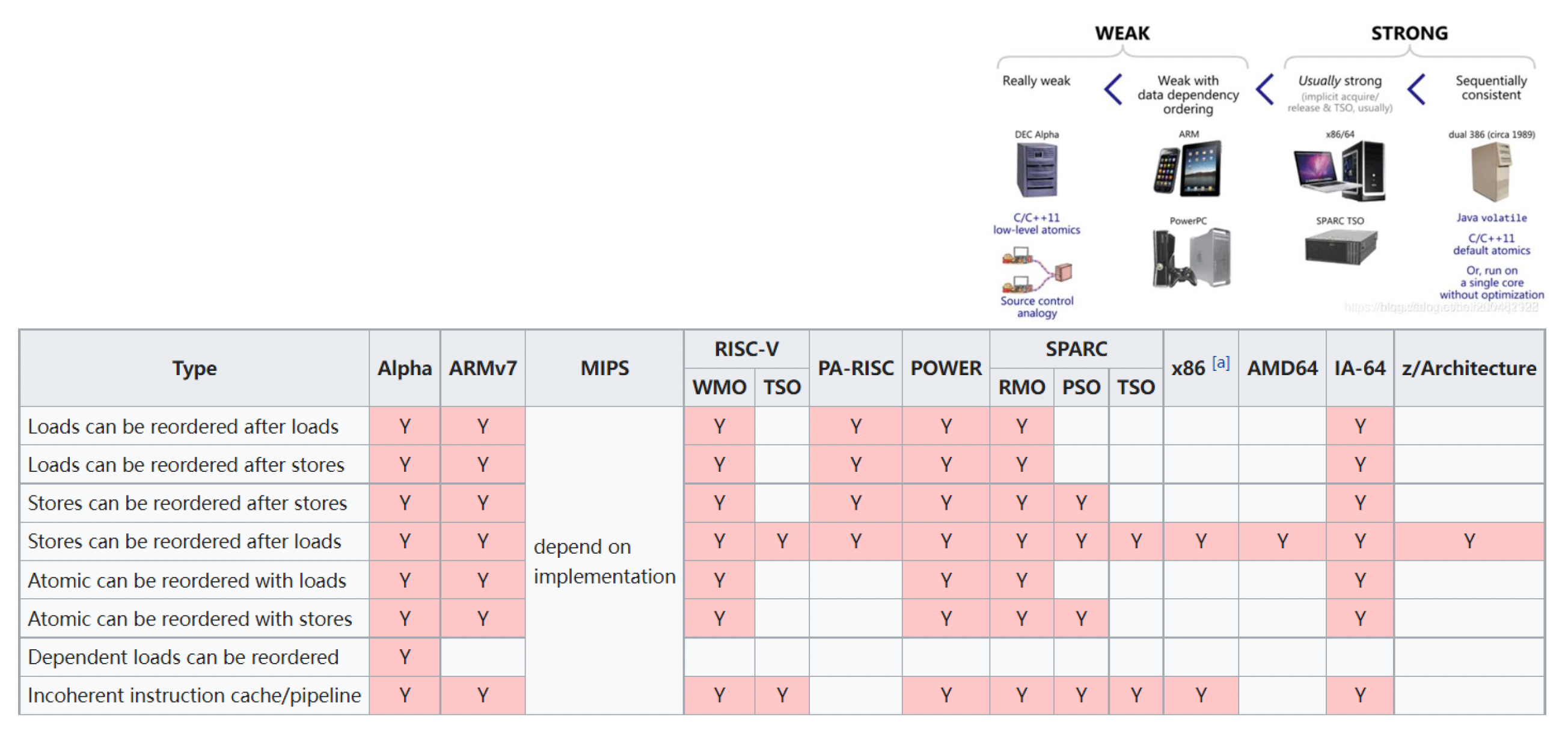
出于性能需求,编译器和 CPU 在优化过程中往往会对指令进行重排(reordering)。但有时候这样会给多线程编程带来困扰。如下图所示,如果按正常顺序执行,线程 2 就会触发断言的(除非还有别的线程修改 b 的值a = b + 1; 和 b = 0; 两条语句可能会颠倒,此时断言就不再触发。

更麻烦的是,像这种乱序执行在各种 CPUs 中都会发生,而且它们:
- 会采用截然不同的优化策略
- 提供不同类型的内存顺序
- 因此并行程序需要不同的处理
游戏开发中会分 release 版和 debug 版。后者的执行顺序基本上认为是对的,但前者由于采取了更激进的优化策略,执行逻辑可能往往和程序员想的不一样,因而产生一些意想不到的 bug,而且这种 bug 很难排查。
Parallel Framework of Game Engine⚓︎
下面来看游戏引擎中是如何实现并行编程的。
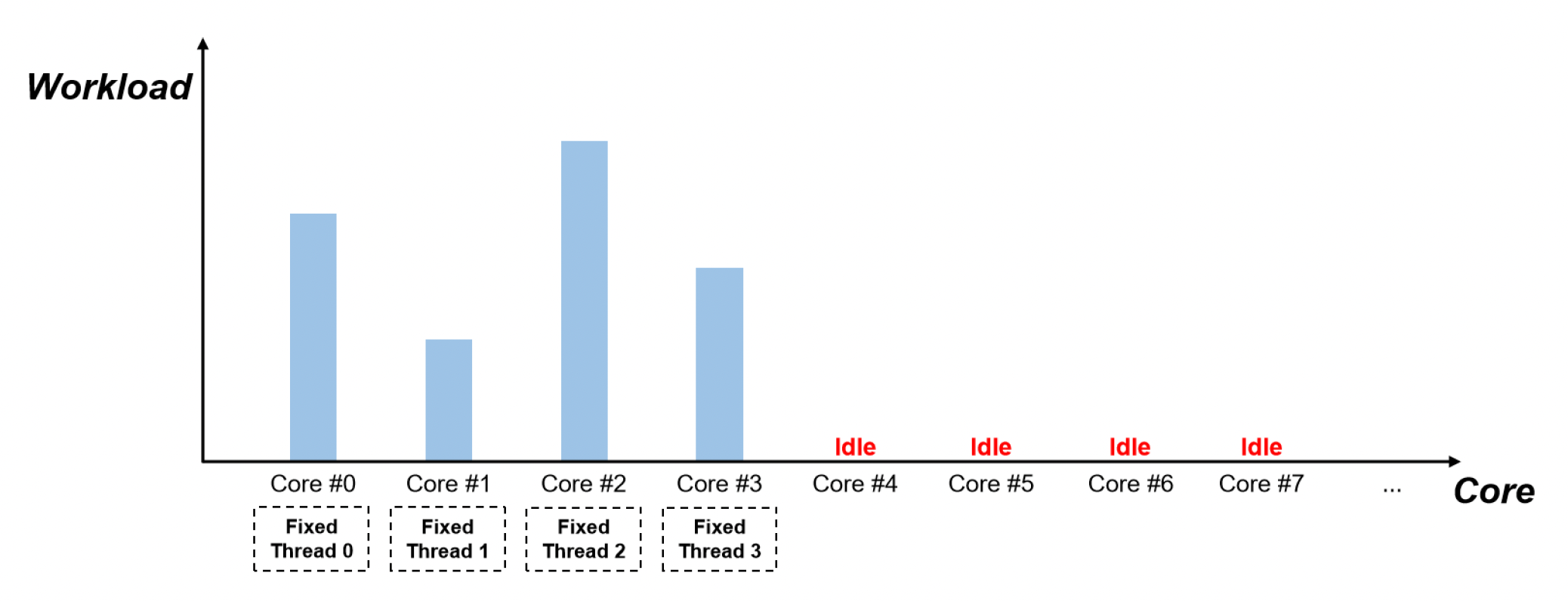
Fixed Multi-thread⚓︎
最简单的做法,也是大多数现代游戏引擎的做法是为每一类任务(游戏逻辑的一部分)分配一个固定的线程。比如一个专门负责渲染,一个专门负责模拟等。
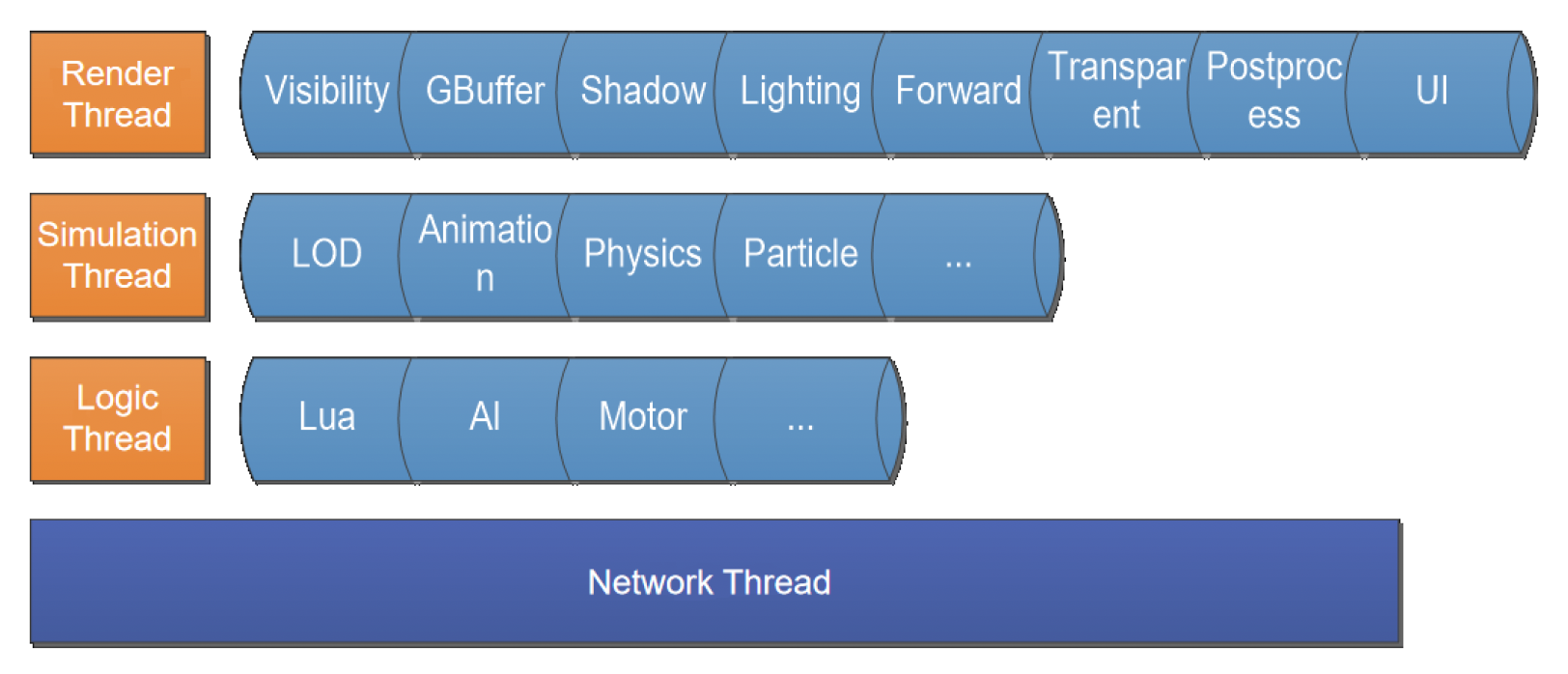
优点:易于实现
缺点
-
线程(核心)的工作量不均衡
- 短板效应,整个任务的完成得等那个工作量很大的线程执行完毕
- 不能直接将某个线程的任务分出一点给另一个空闲线程完成,因为这破坏了局部性;也不能让它们共享内存,否则会出现数据竞争问题
-
当处理器核心增多时无法扩展
Thread Fork-Join⚓︎
第二种方法叫做分叉 - 合并(fork-join)。它仍然基于第一种方法,但特别适合用来解决数据可并行的任务。
- 比如模拟线程的动画计算非常复杂,那它会创建一些子线程进行并行计算,最后合并子线程的结果
- 使用线程池(thread pool) 来组织频繁的线程创建和销毁
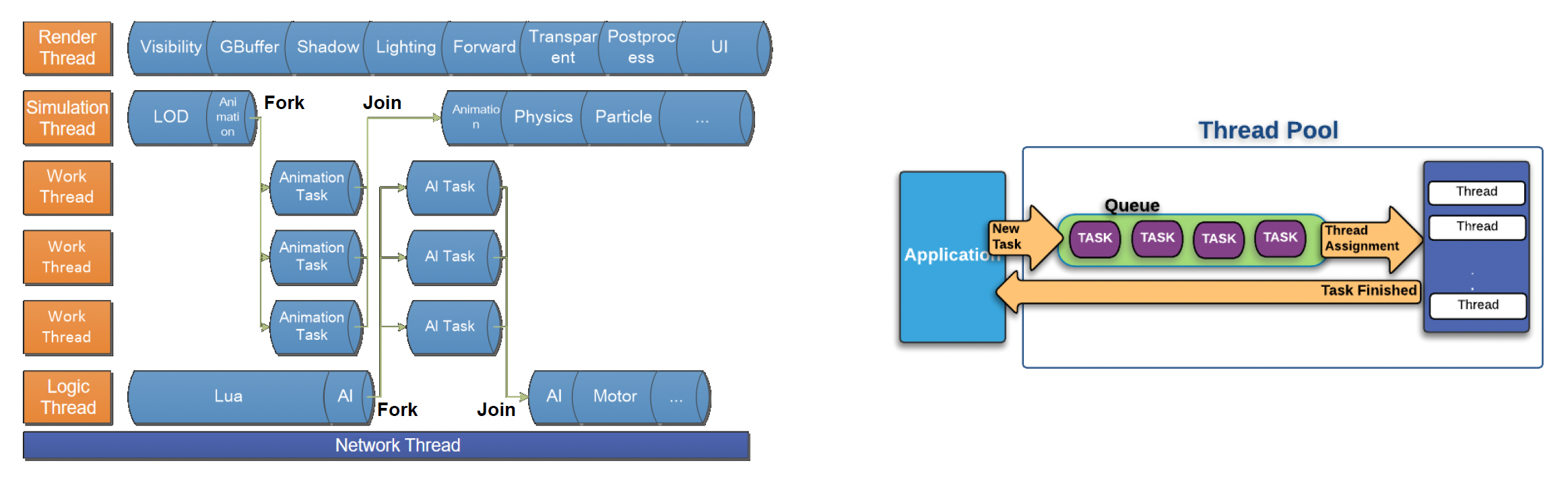
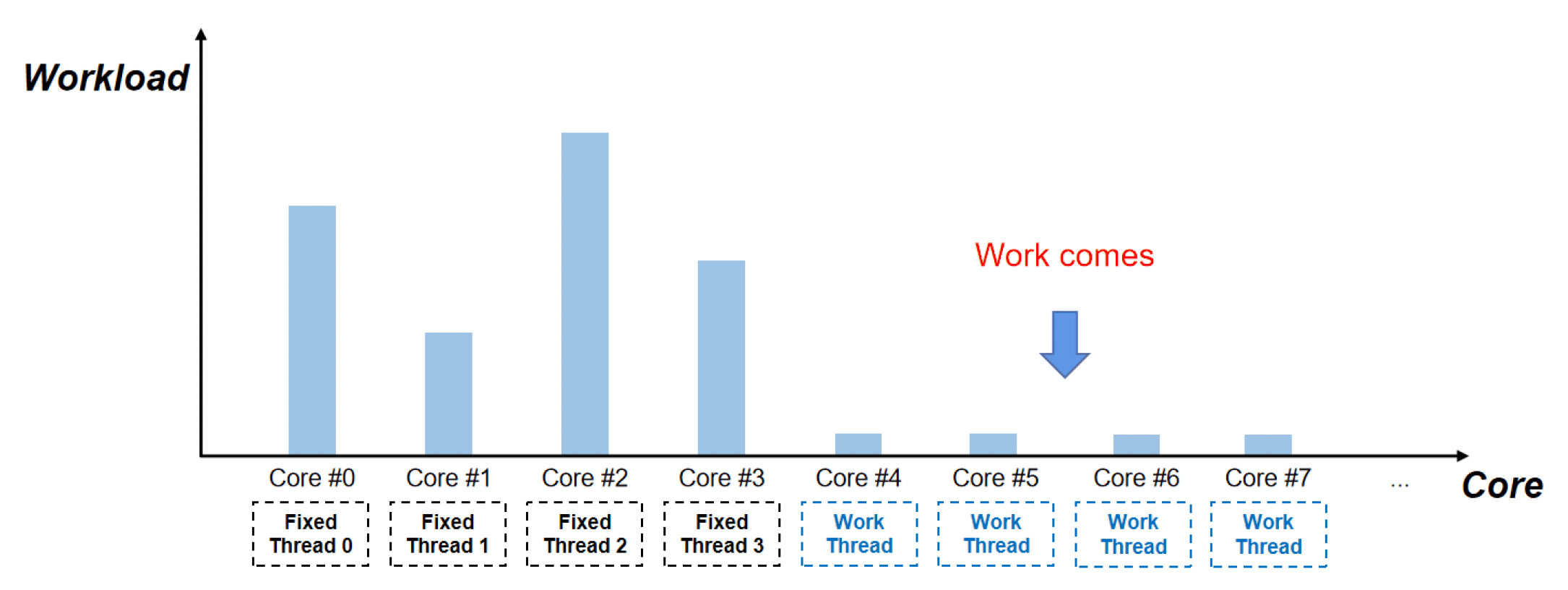
问题
- 对负责撰写逻辑的程序员而言不容易实现(需要手动分割工作、确定工作线程数量等)
- 线程过多可能导致额外的上下文切换的性能开销
- 各线程(核心)间的工作负载仍然不均衡
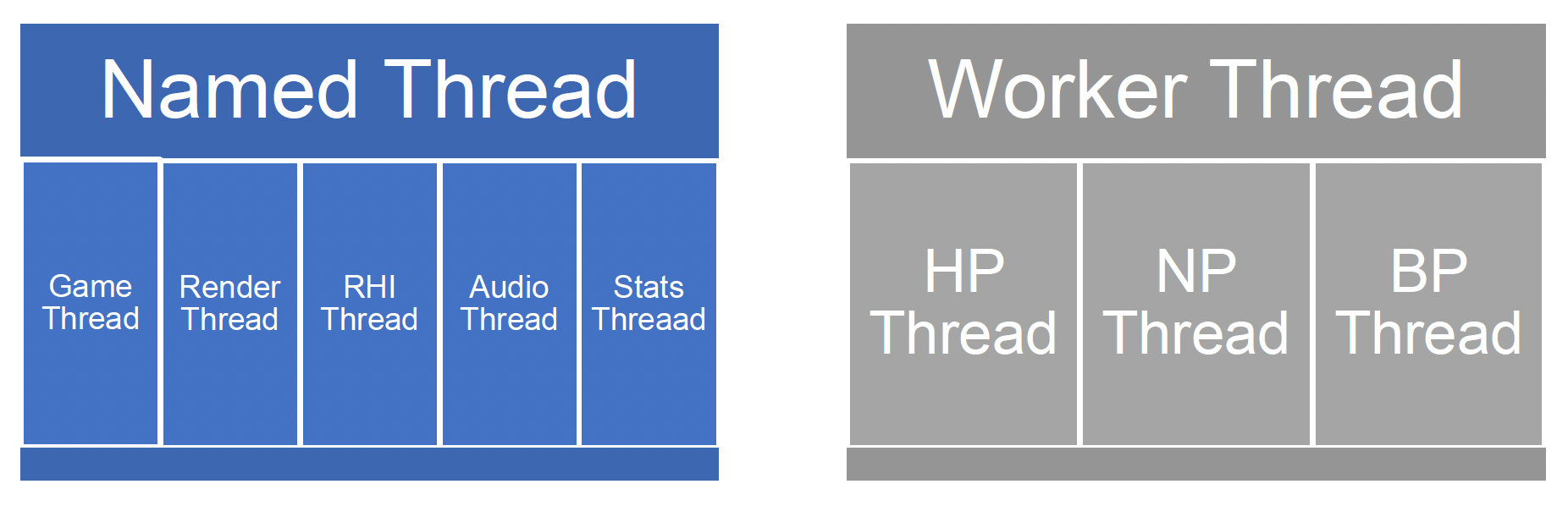
Unreal Parallel Framework⚓︎
Unreal 的并行架构中有两类线程,分别是:
- 命名线程(named thread):由其他系统创建,并附加到并行框架中
- 工作线程(worker thread)
- 三种优先级:高、中、低
- 数量根据 CPU 核心数确定
- 和分叉 - 合并方法类似
Task Graph⚓︎
任务图(task graph) 是一种更复杂的方法。它是一个有向无环图(DAG
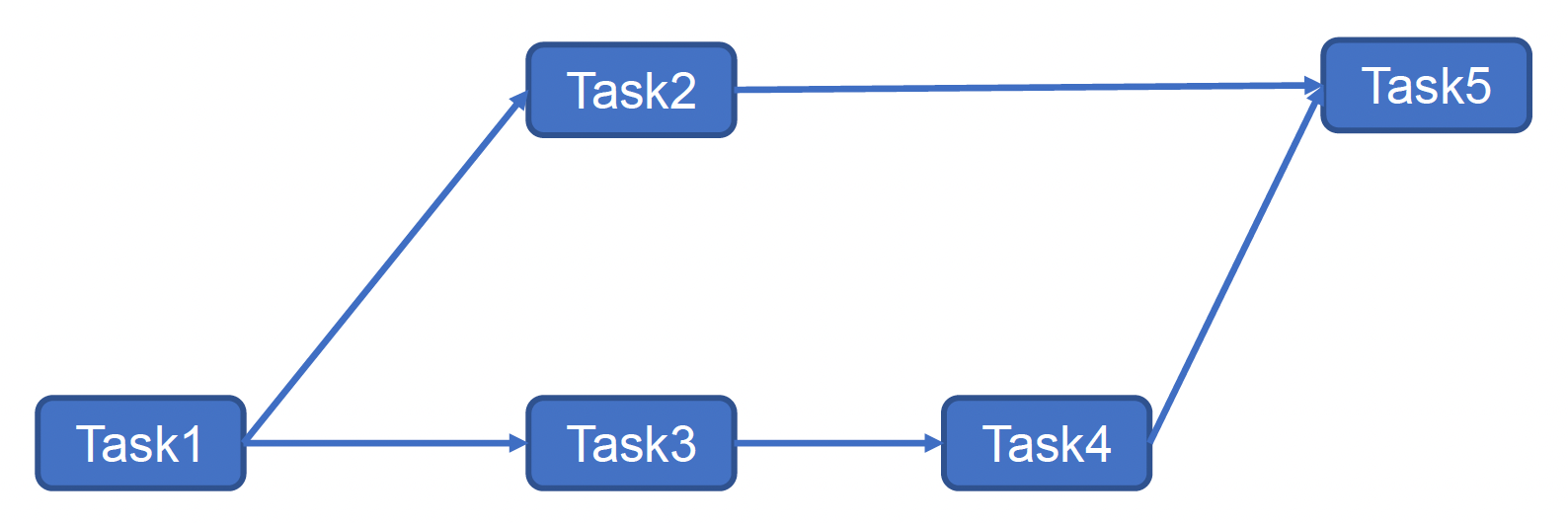
通过链接 (links) 来构建任务图。

问题
- 它是一种静态方法,难以应对动态环境
- 它要求任务必须完整做好才能继续下一个任务,但在游戏中有时会出现执行了一半就要转头做另一项任务的情况
Job System⚓︎
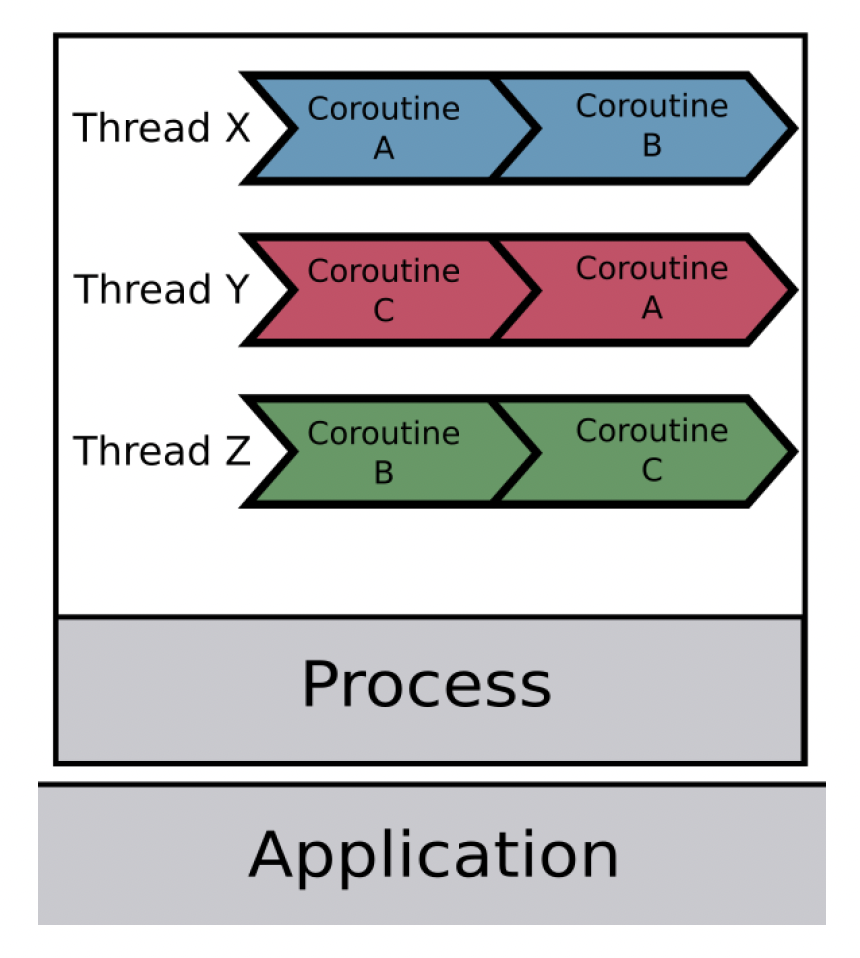
Coroutine⚓︎
协程(coroutine) 是一种轻量级的执行上下文。每个协程也都有自己的用户栈、寄存器等。它的一大特点是协作式的执行,这意味着它可以(随时)交互式地切换到另一个协程中,切换开销会很小。因而作业(jobs) 的创建正是在协程中完成的。
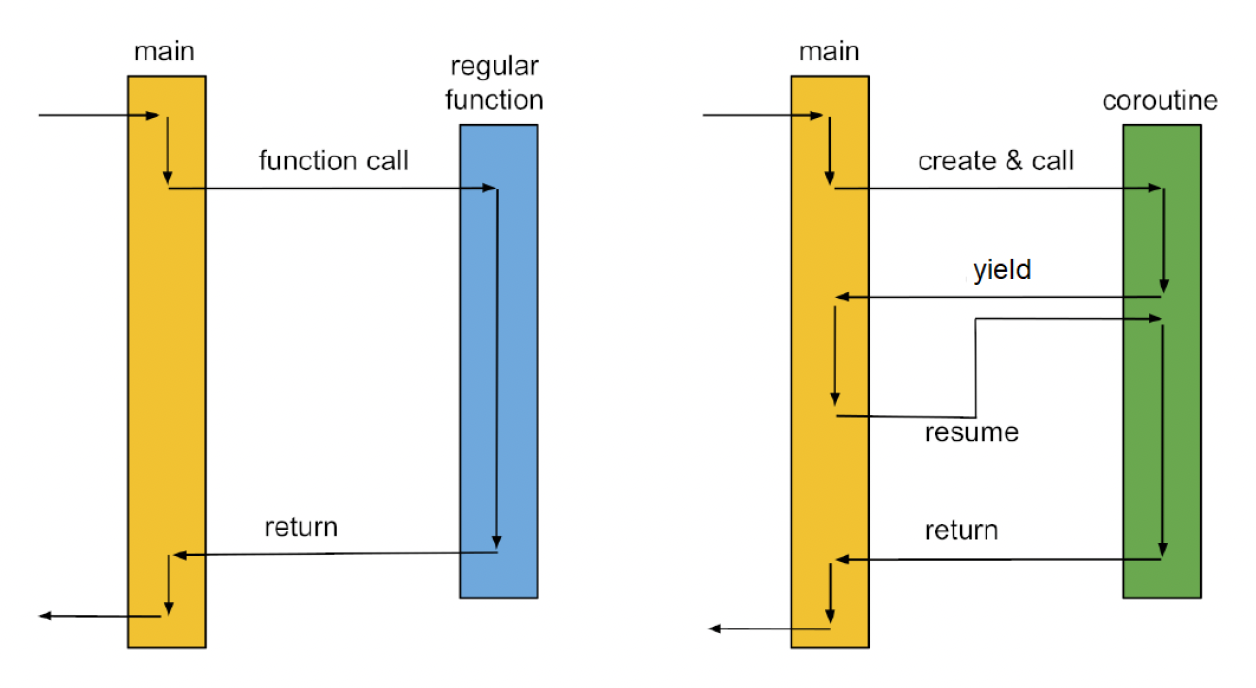
协程 vs 线程
-
协程
- 由程序员调度
- 在线程中执行
- 上下文切换更快,无需切换到内核模式
-
线程
- 由操作系统调度
- 位于进程内
- 上下文切换成本高,需切换到内核模式
协程分为两类:
-
有栈协程(stackful coroutine):协程拥有一个独立的运行时栈,该栈在协程
yield(挂起)之后被保留- 功能更强大,允许在嵌套栈帧内进行
yield操作 - 可以像普通函数一样使用局部变量
- 需要更多内存,来为每个协程预留栈空间
- 协程的上下文切换耗时更长

- 功能更强大,允许在嵌套栈帧内进行
-
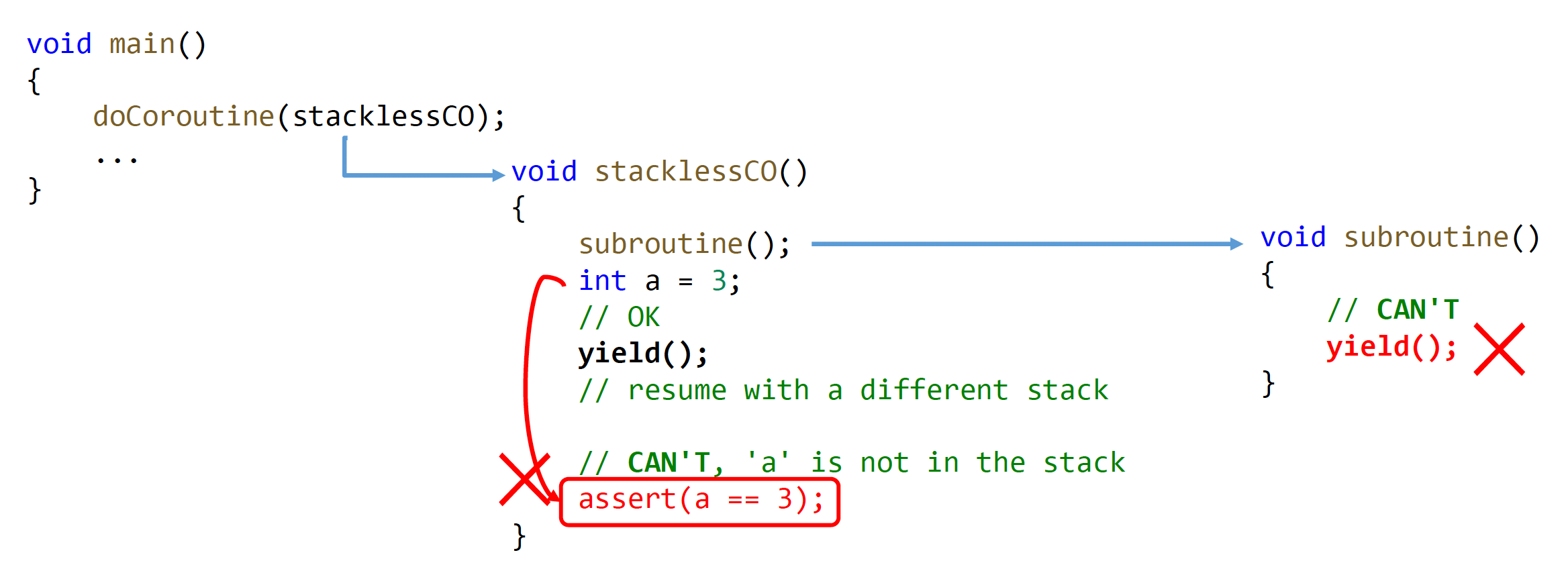
无栈协程(stackless coroutine):协程在 yield 时没有独立的运行时栈需要保留
- 只有顶层例程可以 yield(而子例程在没有栈的情况下不知道返回何处)
- 恢复执行所需的数据应与栈分开存储
- 无需额外内存空间
- 更快的上下文切换
给少部分高手使用的
Fiber-Based Job System⚓︎
基于纤程的作业系统(fiber-based job system) 允许通过创建作业而非线程来实现多任务。
- 纤程(fibers) 类似于协程,不同之处在于纤程由调度器进行调度
- 线程是执行单元,而纤程则是上下文环境;每个处理器核心对应一个线程,以最小化上下文切换的开销
- 任务在纤程的上下文中执行
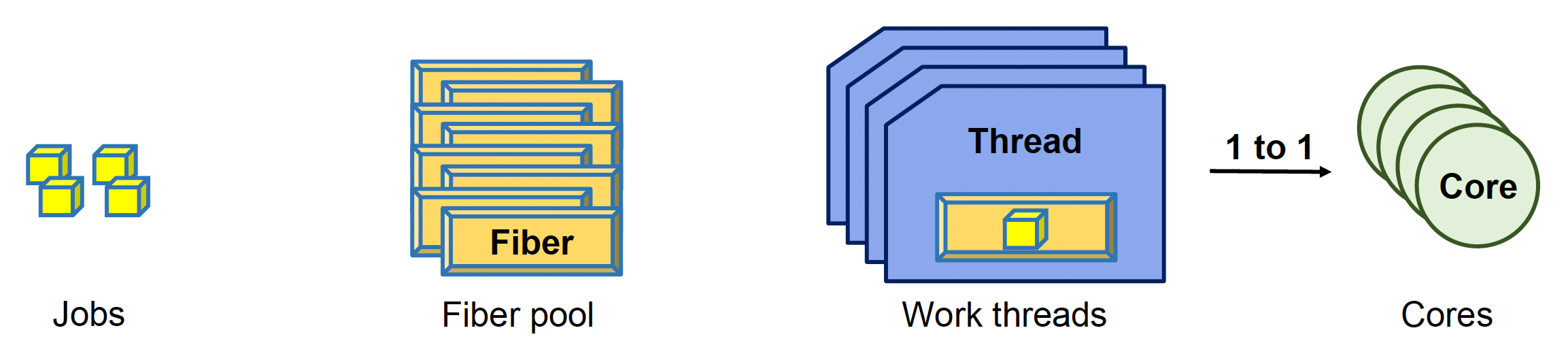
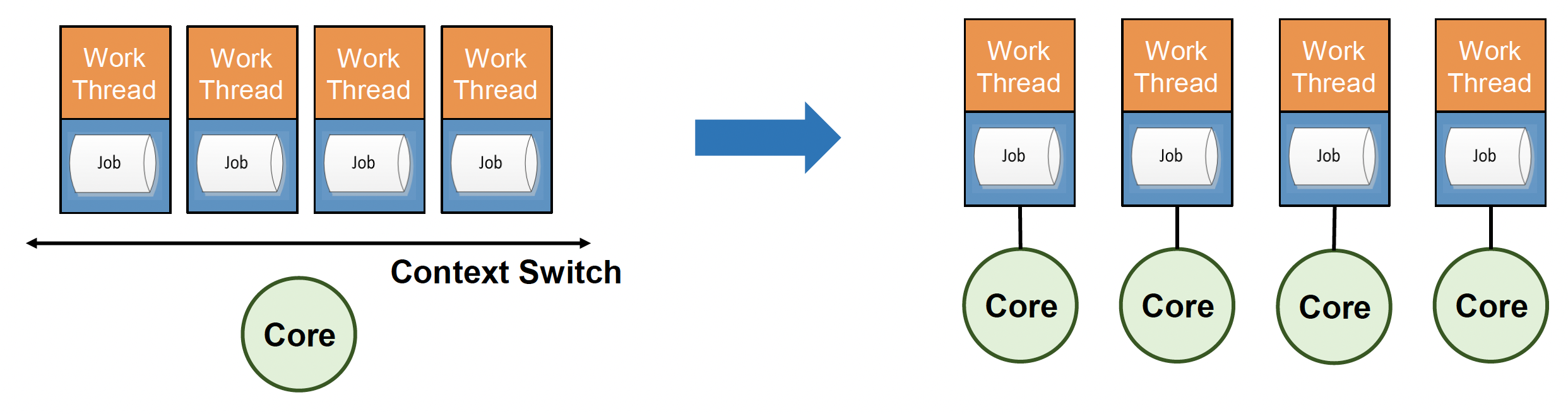
一个原则是尽可能保证一个工作线程对应一个核心,以最小化线程上下文切换的开销(因为单核中的多工作线程仍会遭受上下文切换的影响
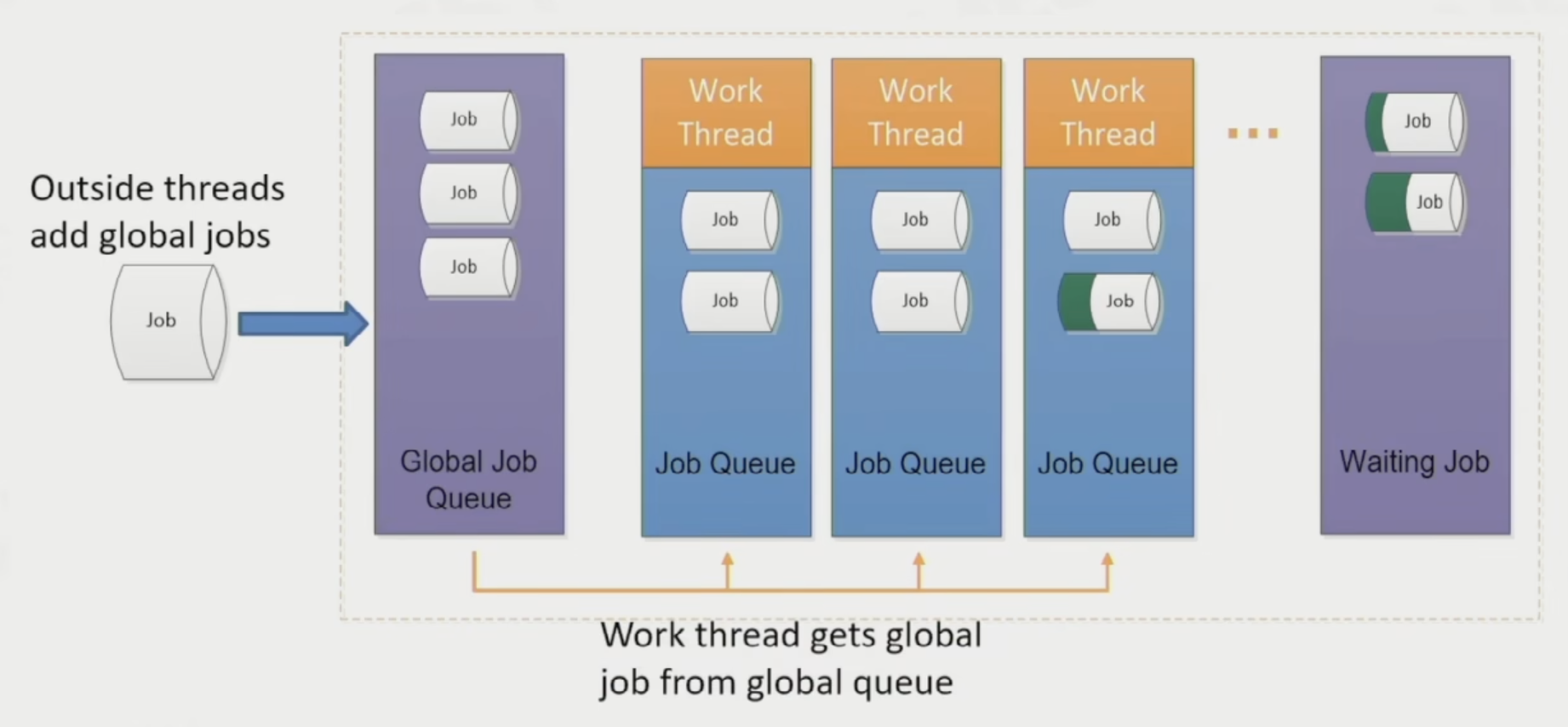
现在来看作业是如何被调度的。
-
全局作业(global job):
- 将作业分配给相对空闲的工作线程,确保各线程负载均衡
- 采取 LIFO 模式(即栈)
-
作业依赖性(job dependency):
- 多数时候作业间的依赖关系形成一棵树
- 有时要先执行优先级更高的作业,但资源有限,所以会把低优先级的作业暂时放到一个等待队列中;这个作业和新进来的高优先级作业之间建立了一个依赖关系,等这个高优先级作业结束后,该作业又回到原来的线程中运行
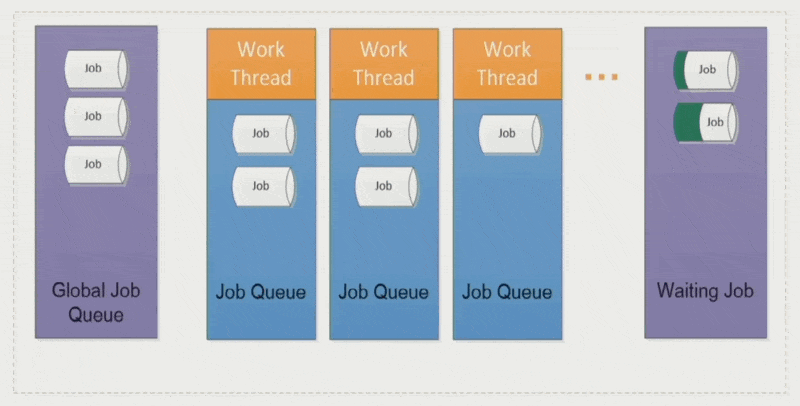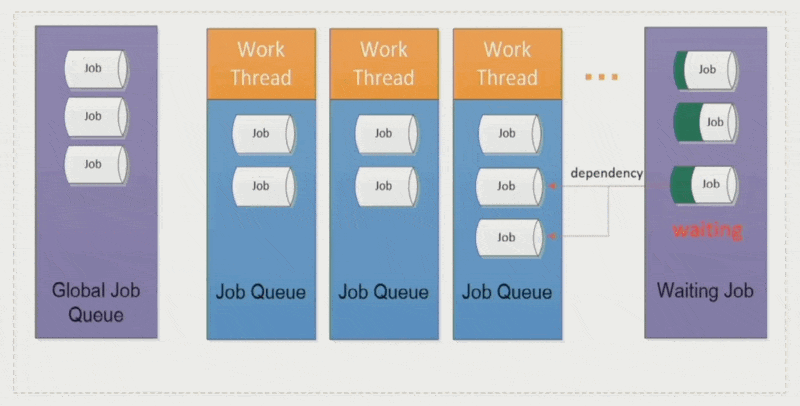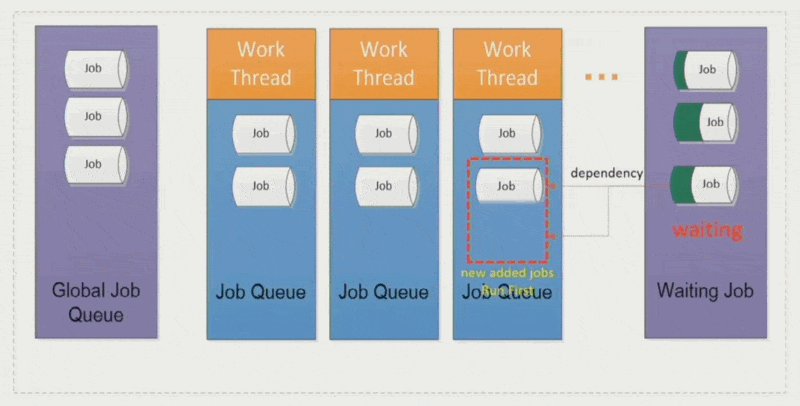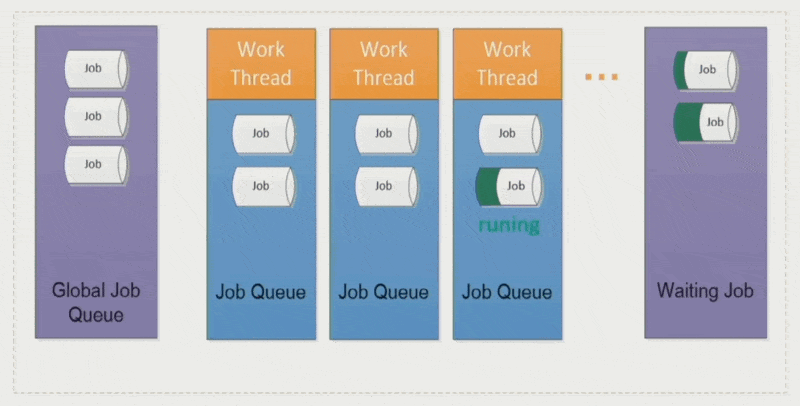
-
作业窃取(job stealing):空闲的工作线程会从其他线程中「偷」些作业过来,避免某些线程执行时间过长而拖累整体表现
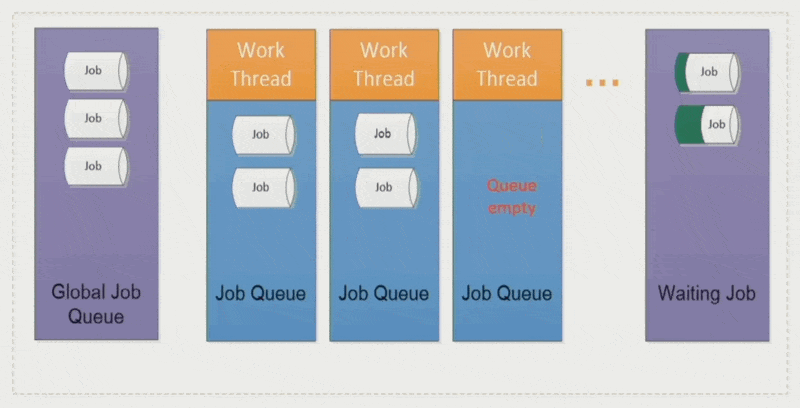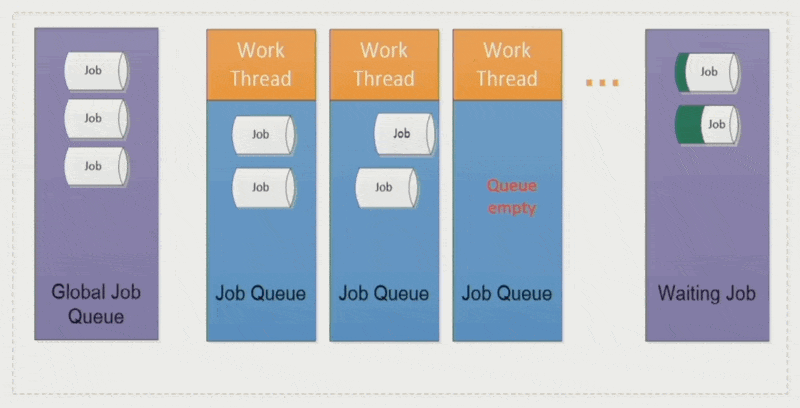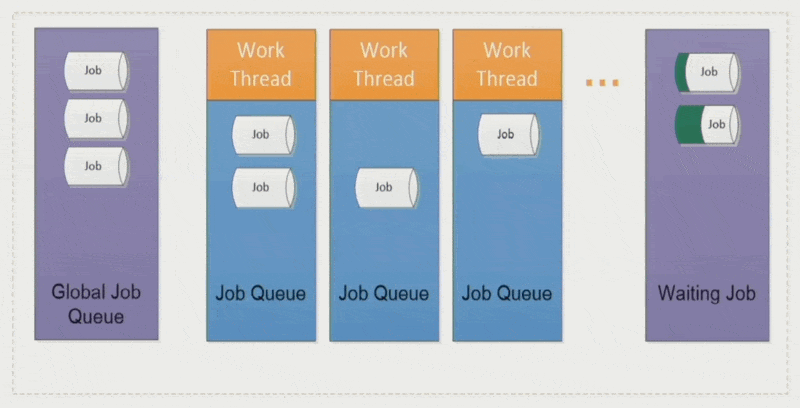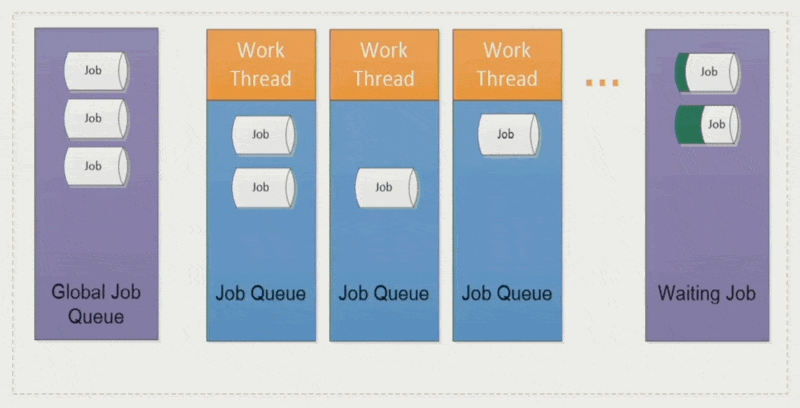
优点
- 任务调度实现容易
- 便于处理任务的依赖关系
- 作业的栈是独立的
- 减少频繁的上下文切换
缺点
- C++ 原生不支持纤程
- 不同操作系统间的实现存在差异
- 存在一些限制(比如
thread_local无效)
Programming Paradigms⚓︎
Data-Oriented Programming (DOP)⚓︎
Performance-Sensitive Programming⚓︎
Performance-Sensitive Data Arrangements⚓︎
Entity Component System (ECS)⚓︎
评论区