Chap 2: Memory Hierarchy Design⚓︎
约 16708 个字 44 行代码 预计阅读时间 84 分钟
核心知识
-
关于存储器层级的 4 个问题:
- 块置放:直接映射、全相联、组相联
- 块识别:块地址各个位的作用(标签、索引、偏移量、有效位、脏位 ...)
- 块替换:随机,LRU,FIFO
- 写策略:写穿 or 写回,写分配 or 非写分配
-
高速缓存的优化策略(重中之重
! ) :- 减少命中时间:小而简的高速缓存、路预测、避免地址转换
- 增加高速缓存带宽:流水线化高速缓存、多分区高速缓存
- 减少失效损失:多级高速缓存、读失效优于写、关键字优先、早启动、合并写缓冲区
- 减少失效率:增大数据块、增大高速缓存容量、增大相联程度、编译器优化
- 并行:预取(硬件 or 编译器)
-
虚拟内存的原理
- 存储器层级设计(仅作了解)
注
虽然本章的绝大多数内容在计组笔记中都讲过,而且某些地方讲得会比体系课程更细,但即便读者在计组课程中已经完全掌握了这块内容,我还是不建议跳过,因为体系课程还介绍了一些更高级的内容,包括针对高速缓存性能的 10 个高级优化方法等等。
不同于计组笔记,我会跳过那些 PPT 完全没有涉及到的内容,比如虚拟机等(这学期笔者实在太忙了
本笔记同时包含教材 Appendix B 和 Chap 2 的内容。
Introduction⚓︎
术语表
看看你还记得多少?

简单回顾与存储器相关的一些基本概念:
- 高速缓存(cache):位于存储器层级中最高层的存储器,直接与处理器连接。
- 也有类似缓冲区 (buffer) 的引申义
- 高速缓存命中 / 失效(hit/miss):处理器在告诉缓存中找到 / 没有找到所需的数据
- 局部性原则(principle of locality) 分为
- 时间局部性 (temporal locality):最近被访问过的数据可能在不久之后会被再次访问
- 空间局部性 (spatial locality):被访问过的数据的邻近数据在不久之后很可能被访问
- 时延(latency):决定数据块中第一个字数据被检索的时间
- 带宽(bandwidth):决定数据块中其余内容被访问的时间
- 虚拟内存(virtual memory)
- 地址空间(address space)
- 页(page)
- 页错误(page fault, palt)
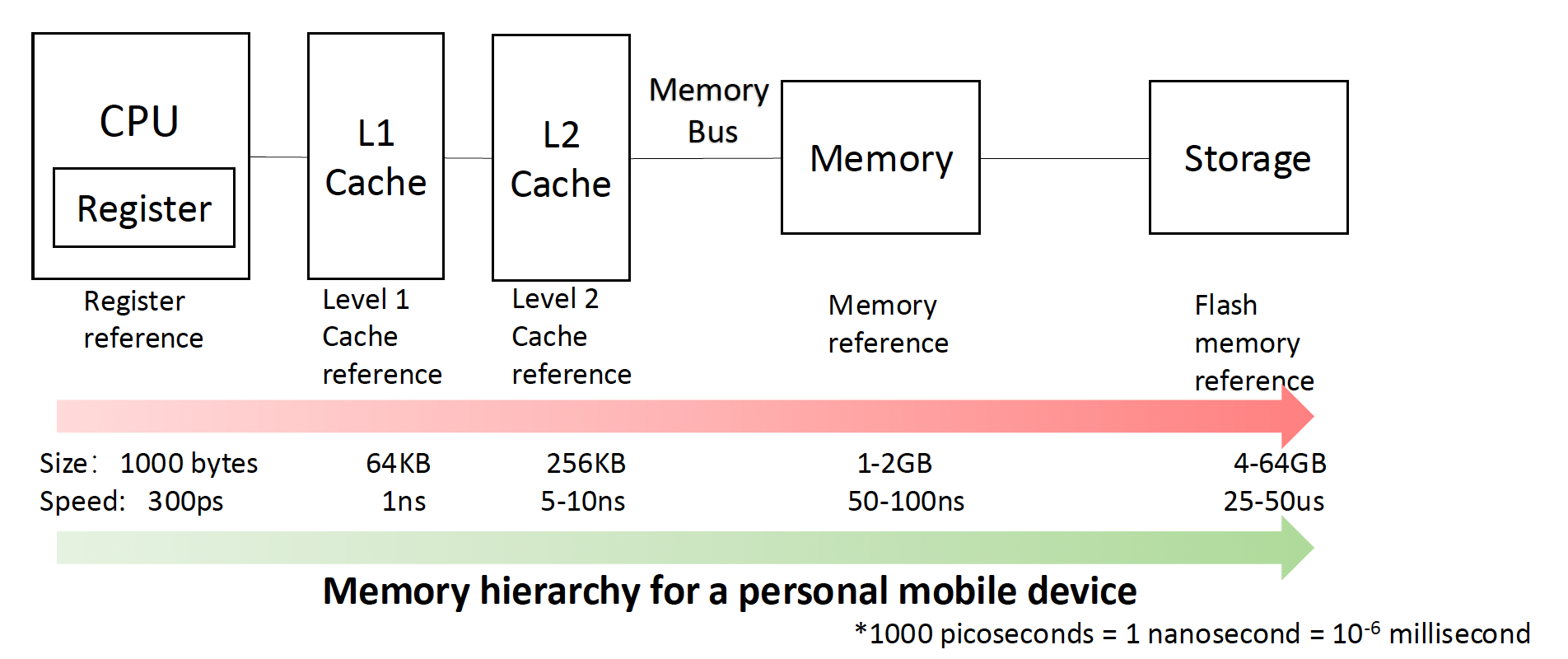
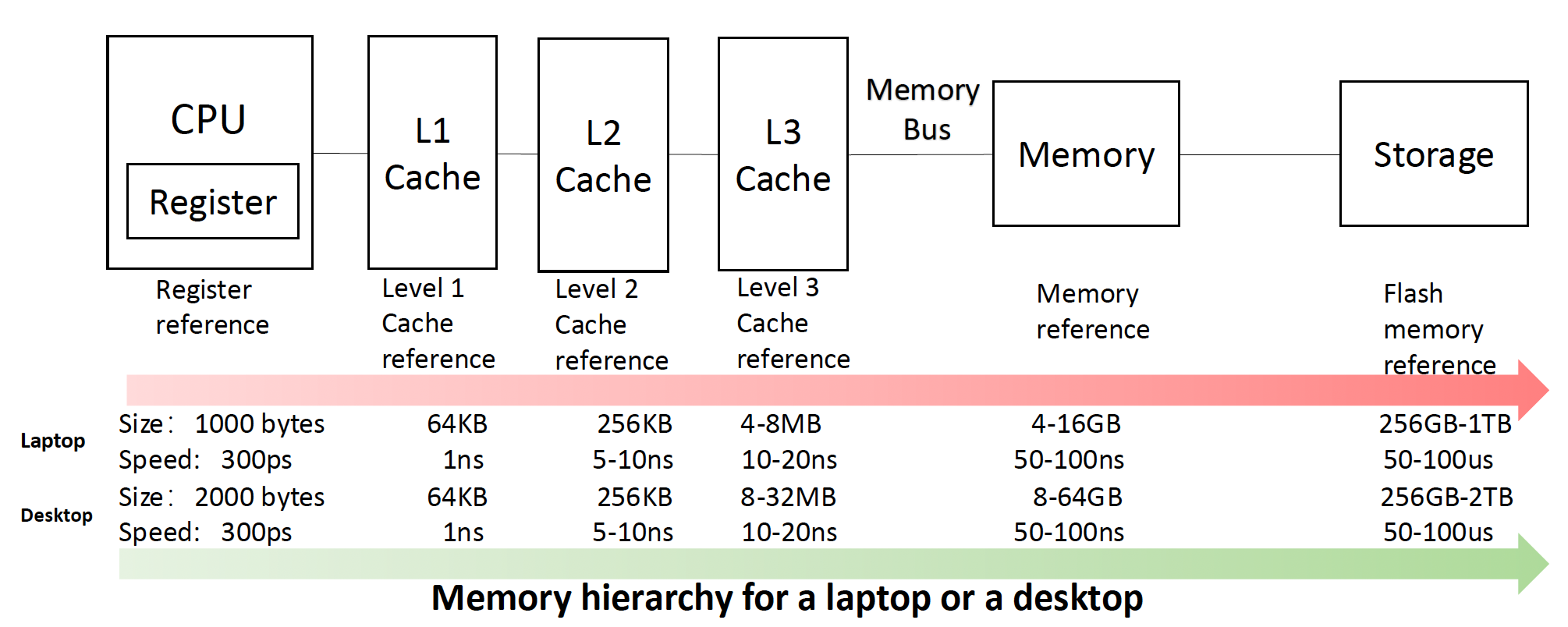
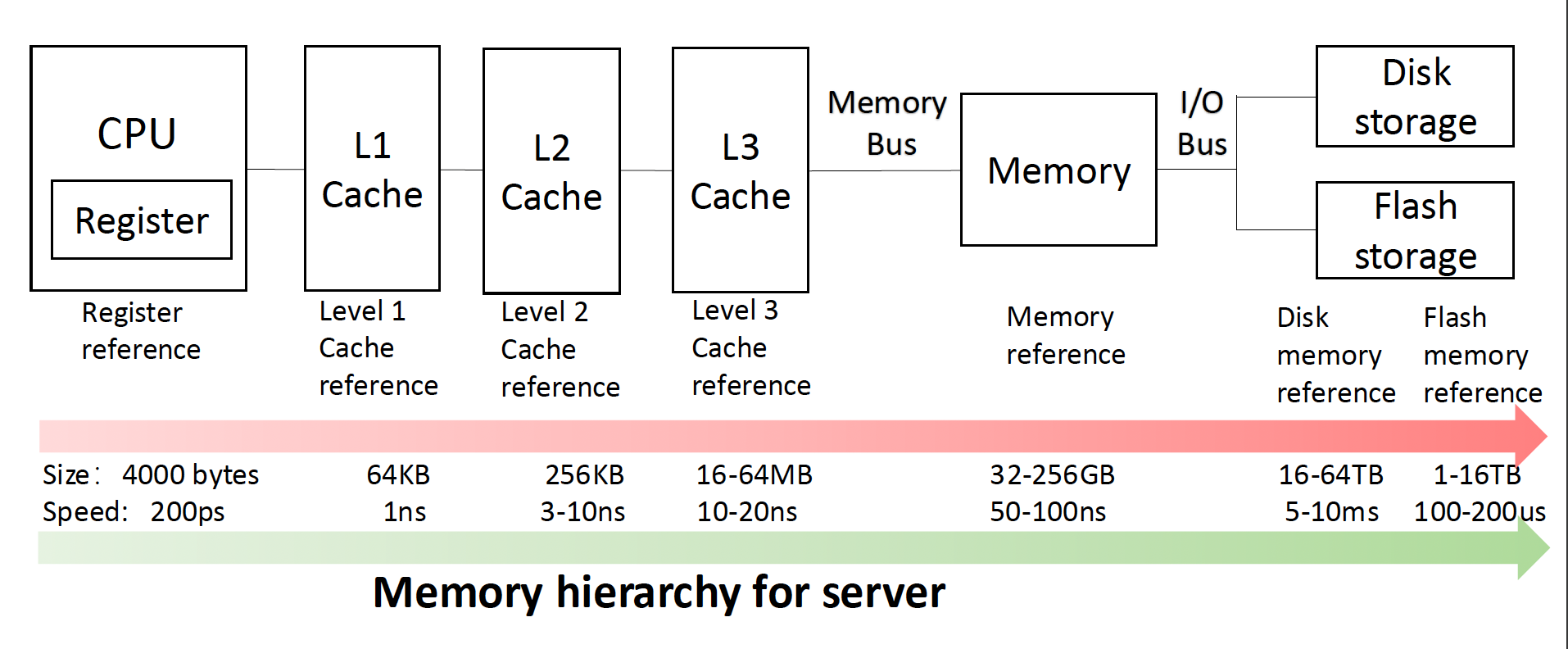
不同计算机类型的存储器层级
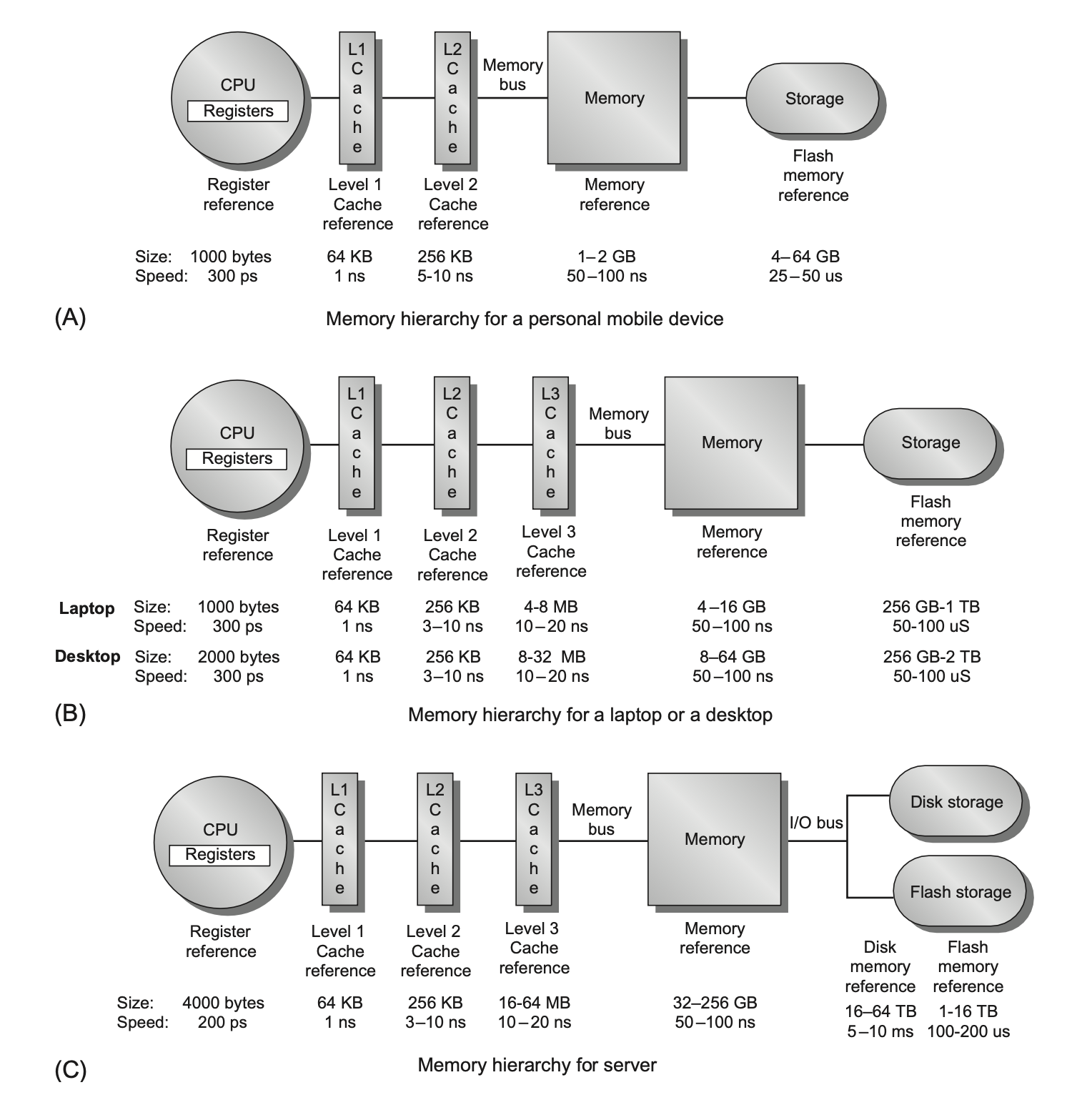
Memory Hierarchy⚓︎
Memory Technologies⚓︎
-
SRAM
- 特性:静态存储,无需刷新,速度快,但成本高、功耗大(待机功耗
) 。 - 应用:主要用于构建高速缓存(L1、L2、L3
) 。 - 挑战:随着高速缓存容量的增加,SRAM 的访问时间、功耗和芯片面积都会增加。
- 优化:组相联高速缓存通过增加块数和动态功耗来减少访问时间。
- 特性:静态存储,无需刷新,速度快,但成本高、功耗大(待机功耗
-
DRAM
- 特性:动态存储,需要周期性刷新,成本低、密度高。
-
内部组织:DRAM 被组织成多个分区(bank),每个分区包含行和列。访问数据需要激活行(ACT 命令
) ,然后通过列地址选通(CAS)读取数据。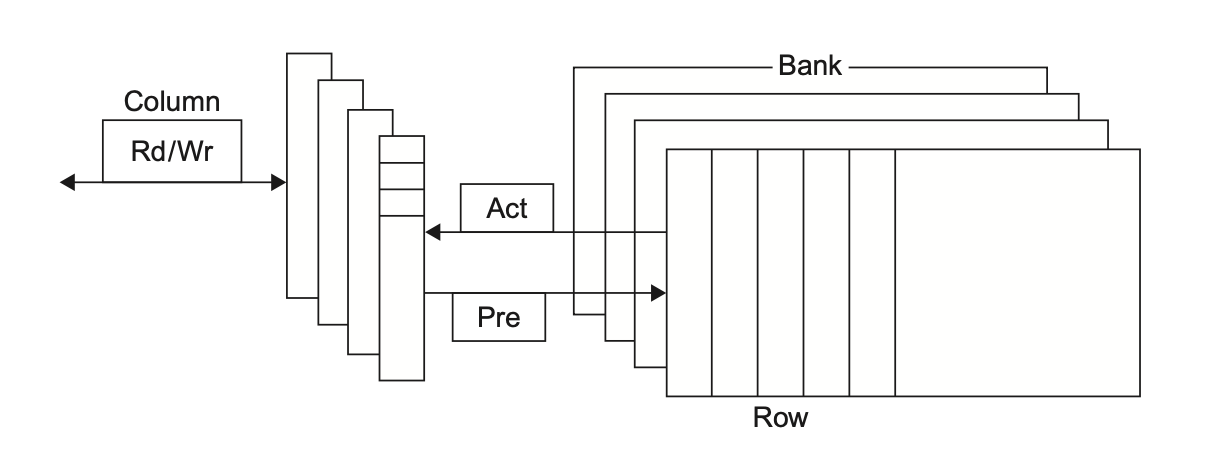
-
性能提升:
- 同步 DRAM(SDRAM):引入时钟信号,支持突发传输(burst transfer),允许在一次行激活后连续传输多个数据。
- DDR(double data rate) SDRAM:在时钟的上升沿和下降沿都传输数据,有效倍增了数据传输速率。DDR1、DDR2、DDR3、DDR4 等版本不断提高时钟频率、降低电压、增加分区数量和预取位数,从而提升带宽和降低功耗。
- 多分区并行访问:允许同时访问不同分区中的数据,进一步提高带宽。
- 功耗:动态内存的功耗包括读写、激活和背景功耗。DDR4 通过降低电压和增加分区数量来降低功耗。
- 图形数据 RAM(GDRAMs):专门为 GPU 设计,具有更宽的接口、更高的最大时钟频率和直接连接 GPU 的特性,提供比 DDR DRAM 高 2 到 5 倍的带宽。
-
堆叠或嵌入式 DRAM(stacked or embedded DRAMs)
- 高带宽内存 (HBM):2017 年出现的新型封装技术,通过 3D 堆叠多个 DRAM 芯片并与处理器(或中介层)紧密连接,大大缩短了 DRAM 与处理器之间的延迟,并提供极高的带宽。
-
2.5D 和 3D 堆叠:2.5D(通过中介层连接)已商用,3D(直接垂直堆叠)仍在开发中,面临散热挑战。
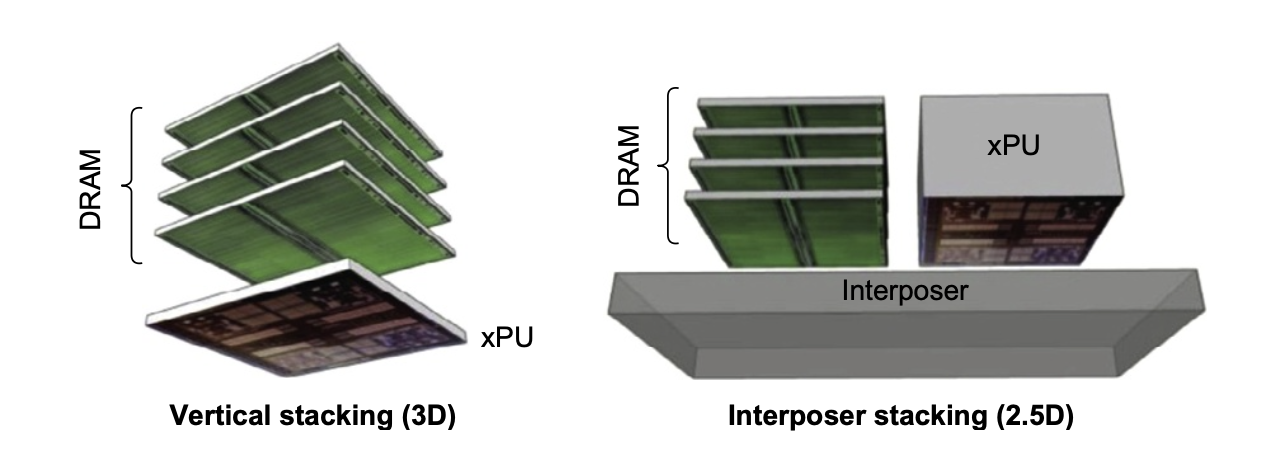
-
应用:HBM 主要用于高端应用,如 GPU 和高性能计算,也可作为服务器的 L4 缓存。
-
闪存(flash memory)
- 特性:EEPROM 的一种,非易失性,断电后数据不丢失。
- 类型:
- NOR 闪存:随机读写快,但写入慢,成本高
- NAND 闪存:密度高,成本低,适合大容量存储,但读写速度慢,需要擦除块
- 与 DRAM 对比:闪存的随机访问延迟远高于 DRAM,但密度高、成本低。
- 挑战:
- 写入速度慢,需要先擦除再写入
- 写入次数有限(寿命问题,通过“磨损均衡”(wear leverage) 解决
) 。
- 应用:广泛用于 PMD(个人移动设备)和笔记本电脑,作为 SSD 替代传统硬盘。
-
相变内存(phase-change memory, PCM)
- 特性:一种新兴的非易失性内存技术,通过改变材料的电阻状态来存储数据。
- 优点:读写耐久性优于 NAND 闪存,读延迟也低于 NAND 闪存,有望降低成本和提高密度。
存储器层级在各类计算机中的表现
Techniques for Higher Bandwidth⚓︎
下面介绍一些提高内存带宽的技术:
-
更宽的主存:增加高速缓存和内存的宽度,一次传输更多数据。
- 效果:将内存宽度加倍或四倍,可使内存带宽加倍或四倍。
- 缺点:
- 需要在关键路径上使用 MUX,这会增加延迟
- 增加客户购买的最小内存增量
- 使错误纠正复杂化
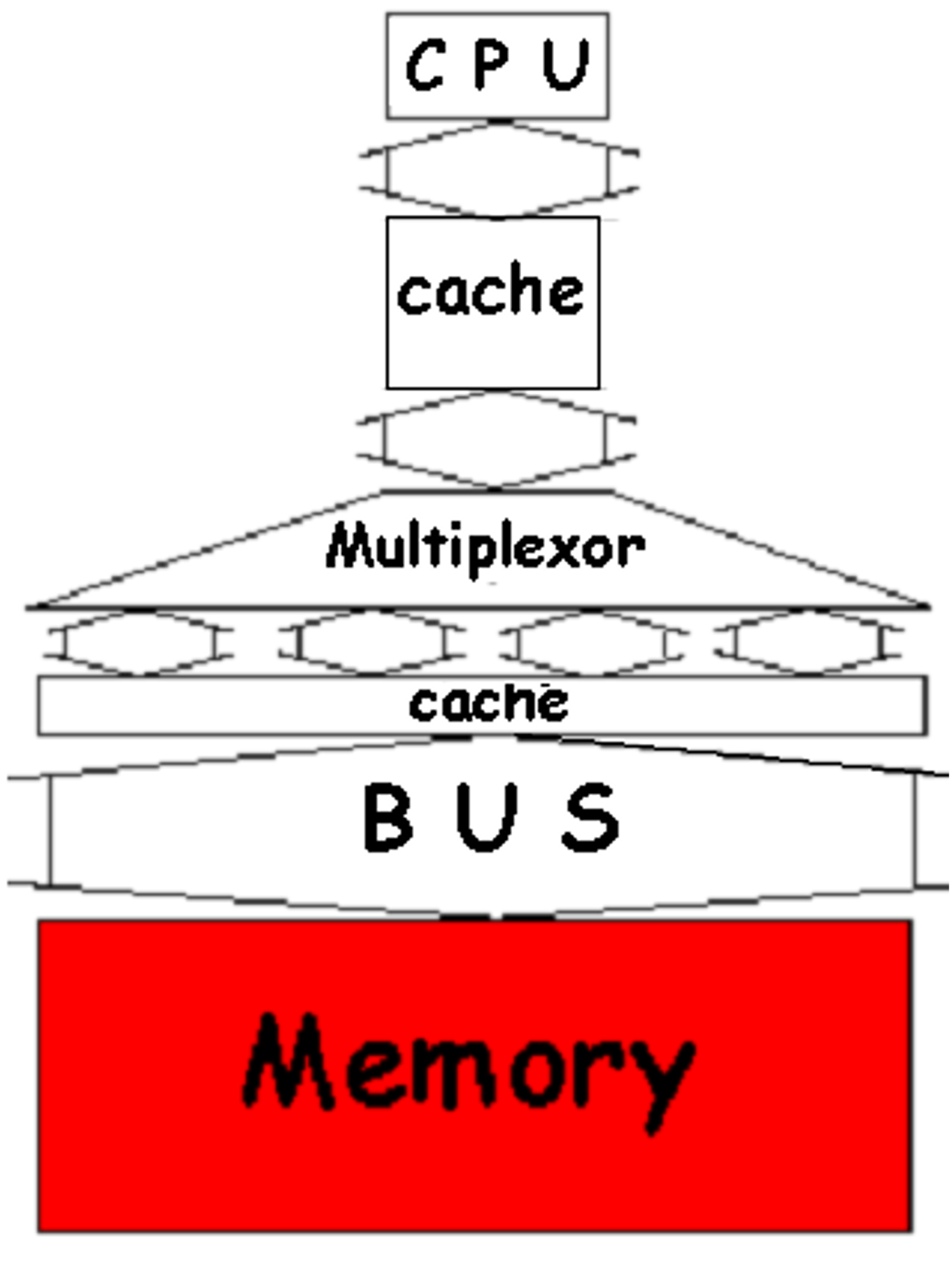
-
简单的交错内存:将内存组织成多个分区,可以同时读写多个字。
- 优点:利用内存系统中多个芯片的并行性,优化顺序内存访问,与缓存读失效理想匹配。
- 访问模式:通过共享地址线和数据总线,实现多路交错访问,可以同时访问不同分区,从而提高吞吐量。
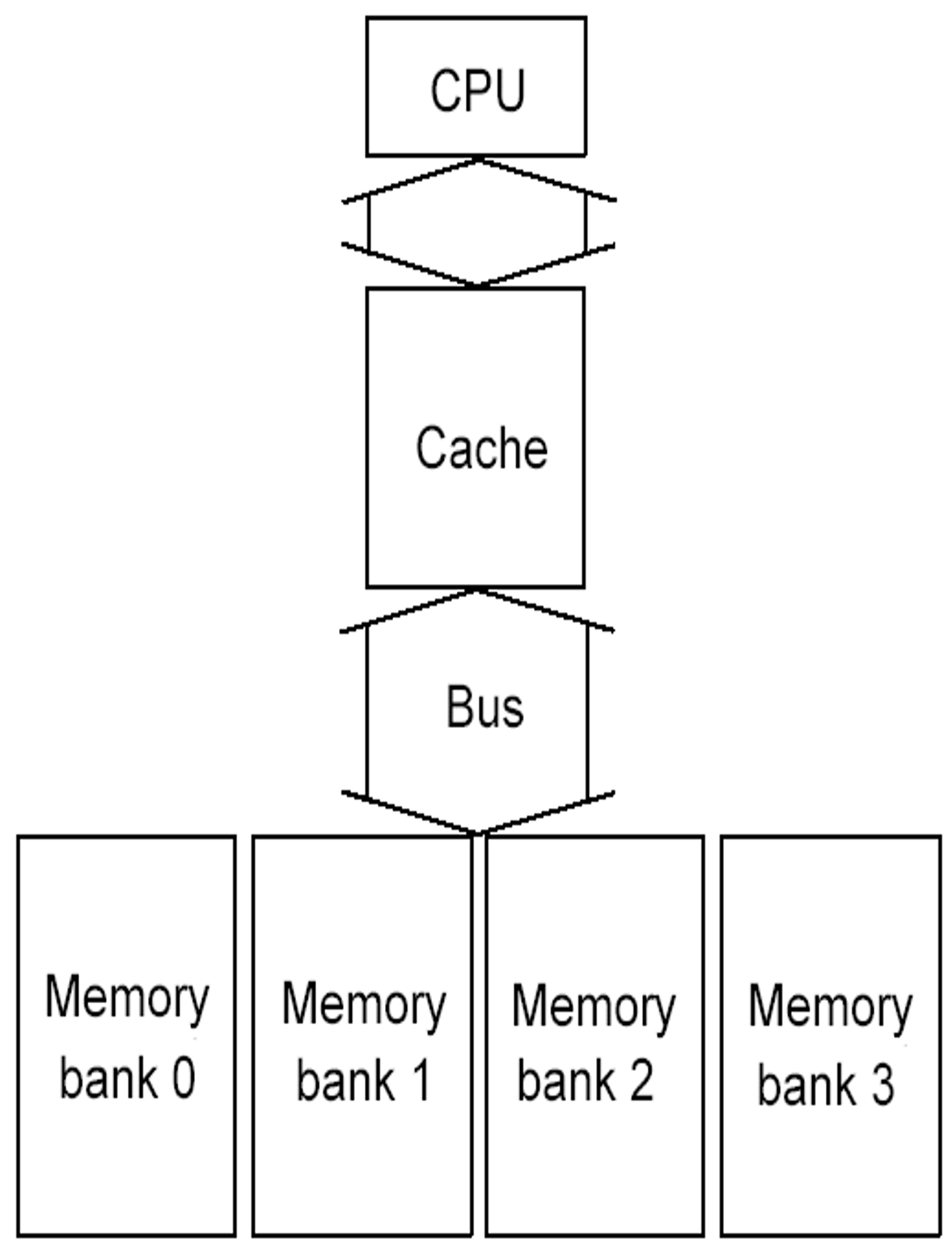
-
关于分区的访问:
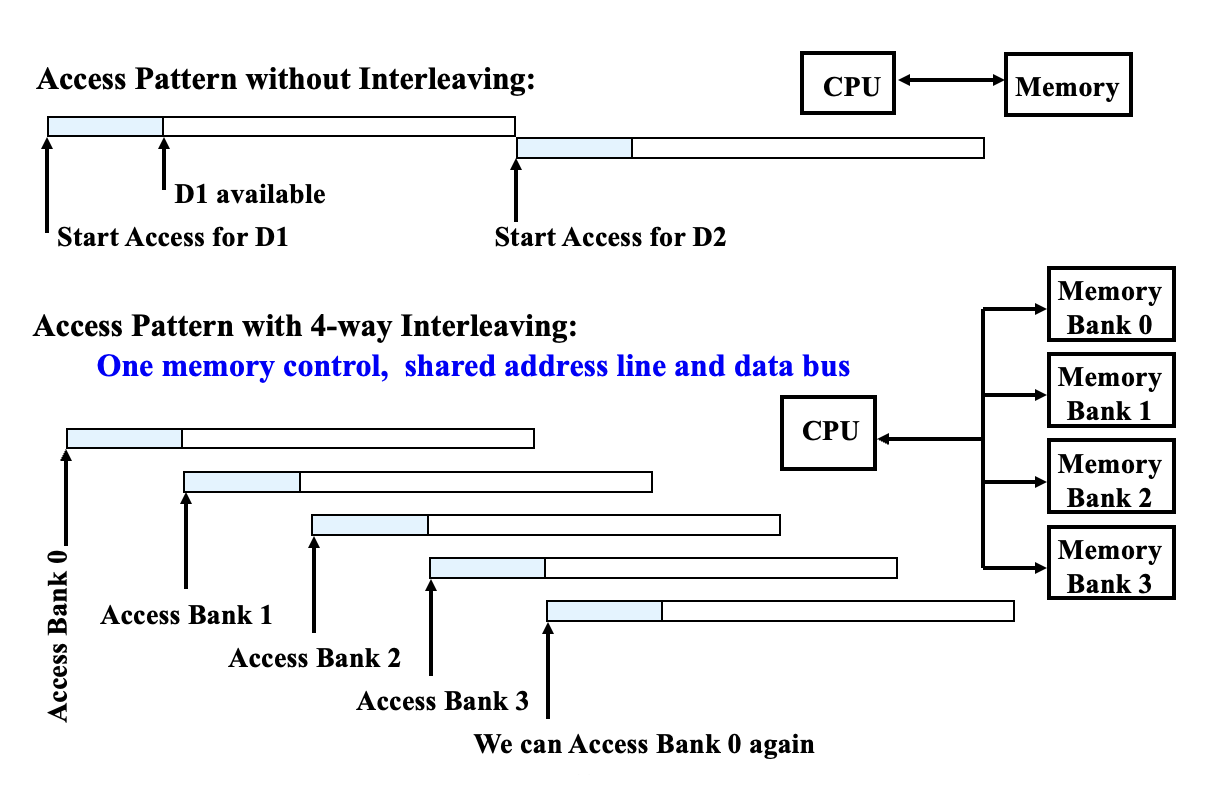
例子
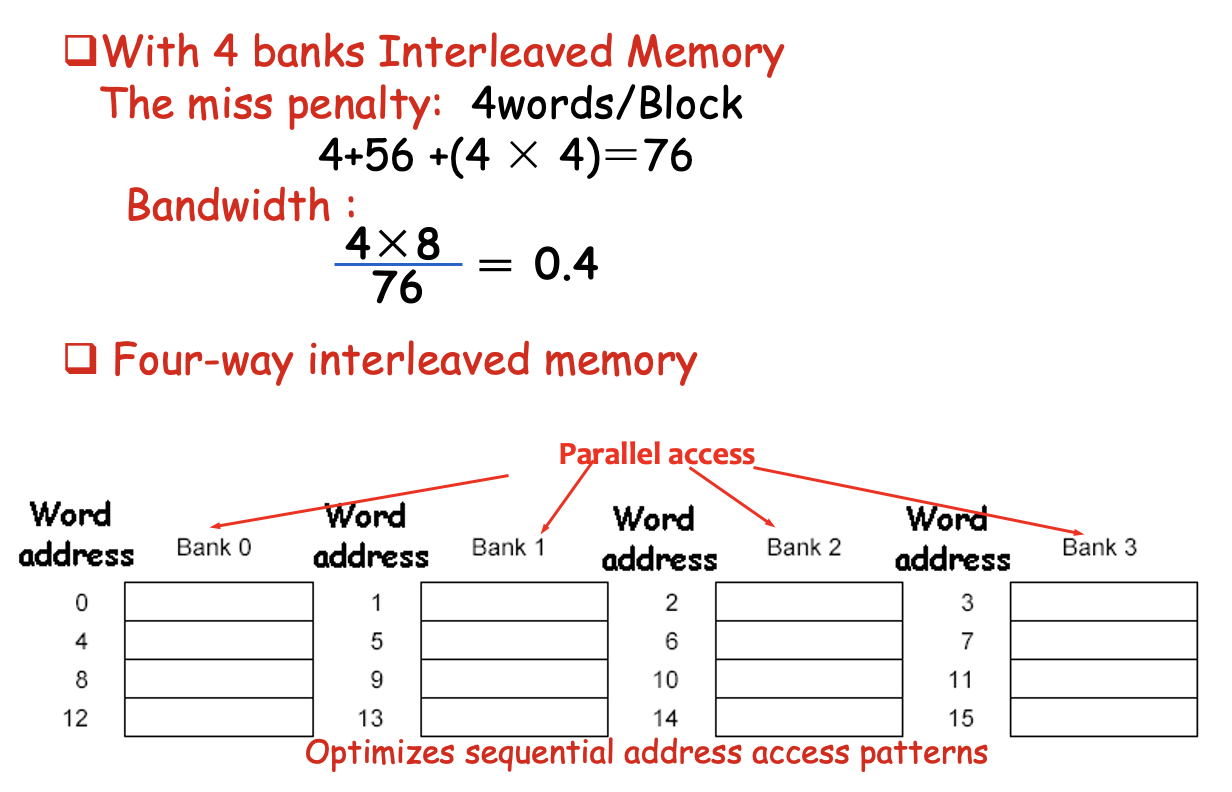
-
独立内存分区:扩展交错内存概念,为每个分区提供独立的内存控制器、地址线和数据总线,消除内存访问的所有限制。
- 优点:允许顺序访问模式的交错,进一步提高并行性。
- 分区数量:向量计算机中,分区数量应大于访问分区中字所需的时钟周期数,以避免等待。
-
避免内存分区冲突:
- 问题:当数组大小或访问模式导致多个元素映射到同一个内存分区时,会发生分区冲突,导致 CPU 停顿。
- 解决方案:
- 软件(编译器)层面:
- 循环交换:改变嵌套循环的顺序,以避免访问同一个分区。
- 扩展数组大小:改变数组维度,使其不是 2 的幂次,从而强制地址映射到不同的分区。
- 硬件层面:使用质数数量的内存分区,有助于分散访问,减小冲突。
- 软件(编译器)层面:
Four Memory Hierarchy Questions⚓︎
在讨论“存储器层级”概念的时候,我们常常需要回答以下四个问题:
- 如何放置数据块
? (数据块放置(block placement)) - 怎么找到数据块
? (数据块识别(block identification)) - 当失效发生时,哪个数据块需要被替代
? (数据块替换(block replacement)) - 写入时会发生什么
? (写入策略(write strategy))
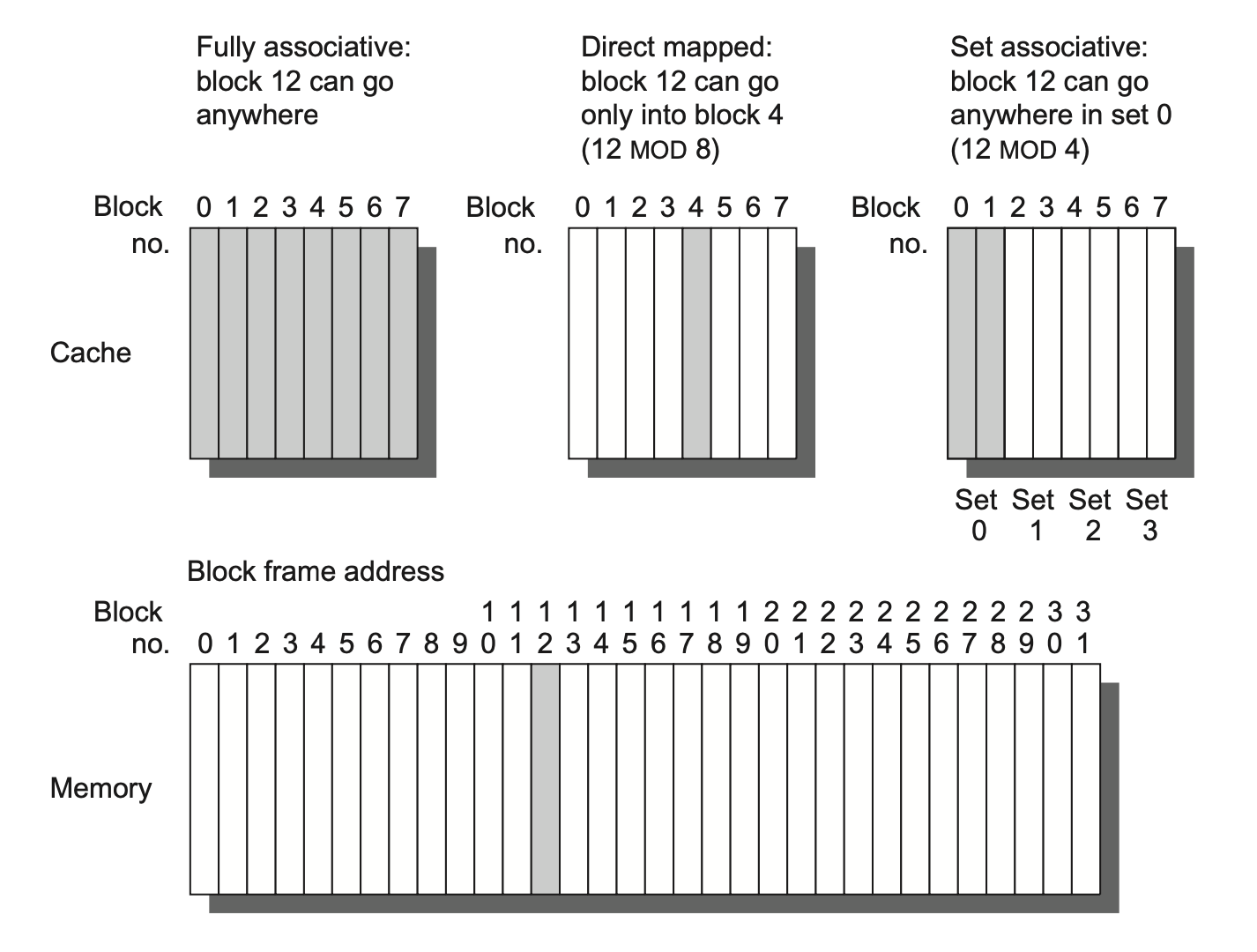
Block Placement⚓︎
有以下几种存储器的组织方式:
-
直接映射(direct mapped):每个数据块在存储器中只有一块确定的位置,计算公式为:
\[ (Block\ address) \text{ MOD } (Numbers\ of\ blocks\ in\ memory) \]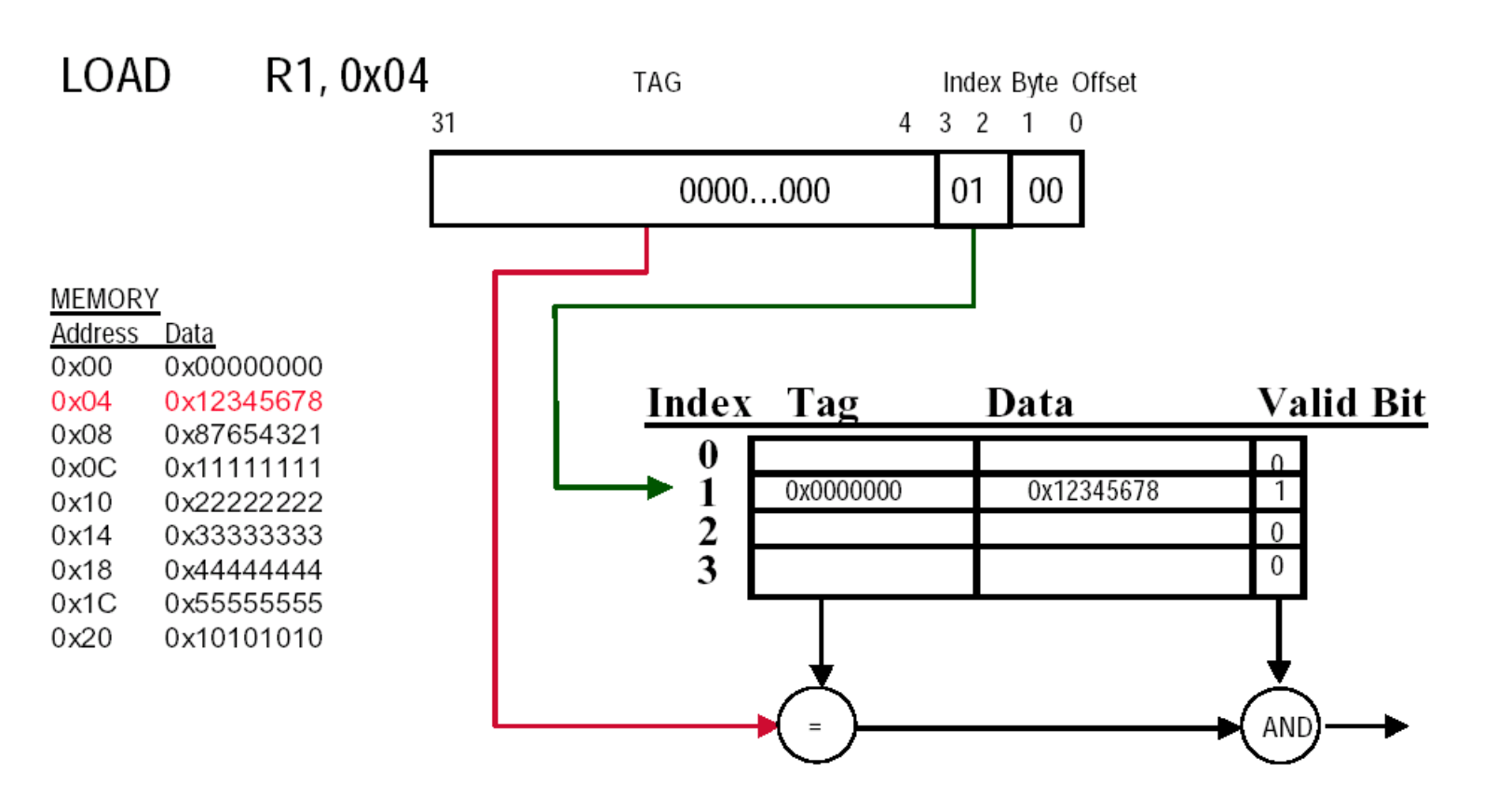
-
全相联(fully associative):数据块可以放在存储器中的任意位置上

-
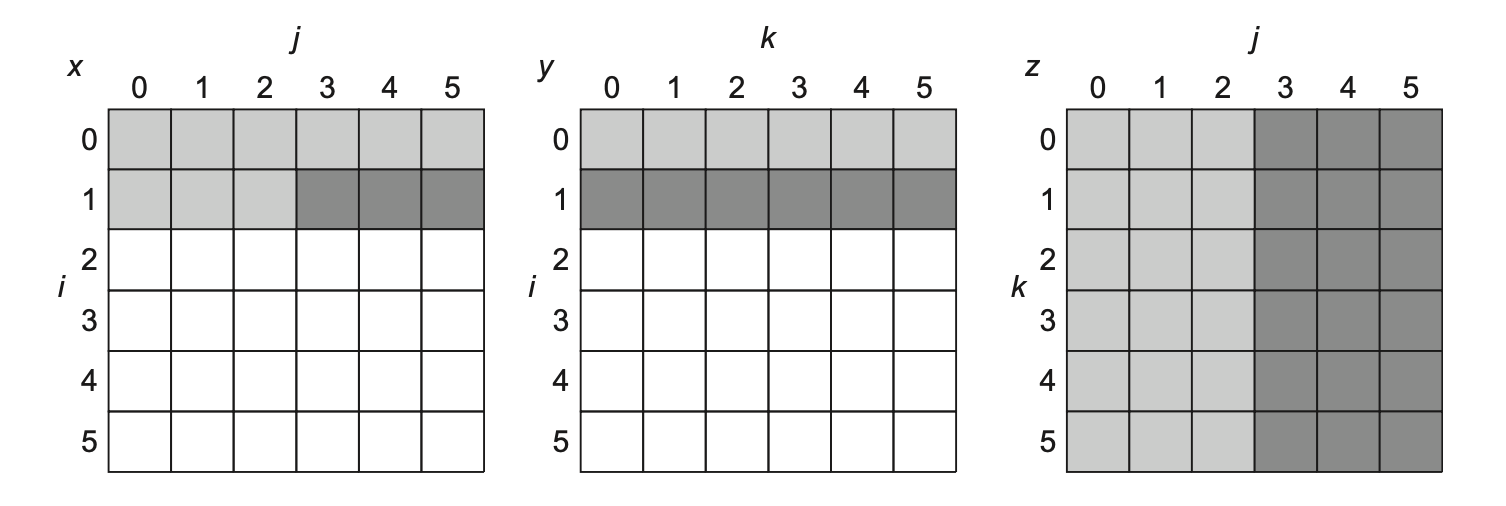
组相联(set associative):每个数据块被限制在存储器的某个组(set) 中,而每个组包含了 n 个可放数据块的地方,数据块可以在组内的 n 个地方任意挑选(这样的组相联称为 n 路组相联(n-way set associative)
) 。组的位置的计算公式为:\[ (Block\ address) \text{ MOD } (Numbers\ of\ sets\ in\ memory) \]- 直接映射 = 1 路组相联,全相联 = m 路组相联(假设存储器容量为 m 个块)
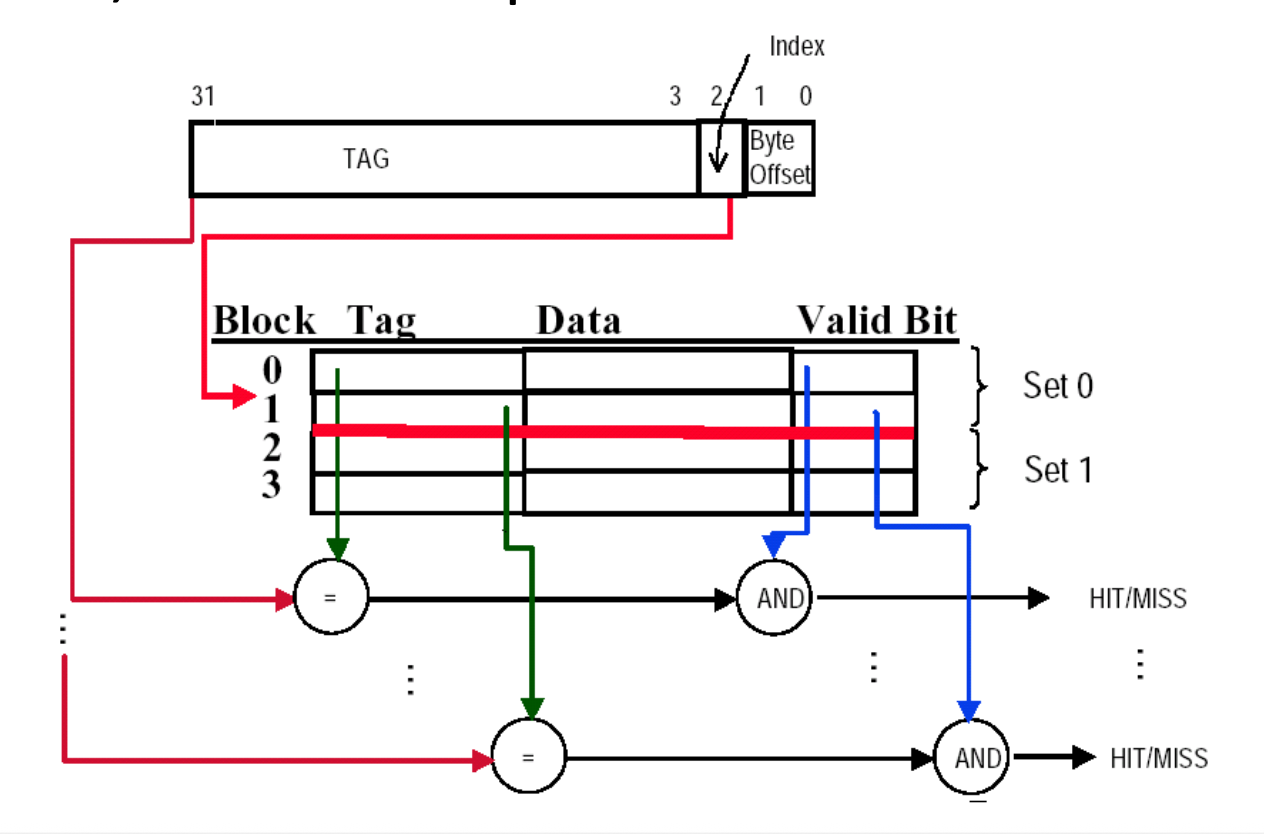
下图以高速缓存为例,展示了不同相联程度的高速缓存:
注
大多数的处理器高速缓存采用的是直接映射、二路组相联和四路组相联。
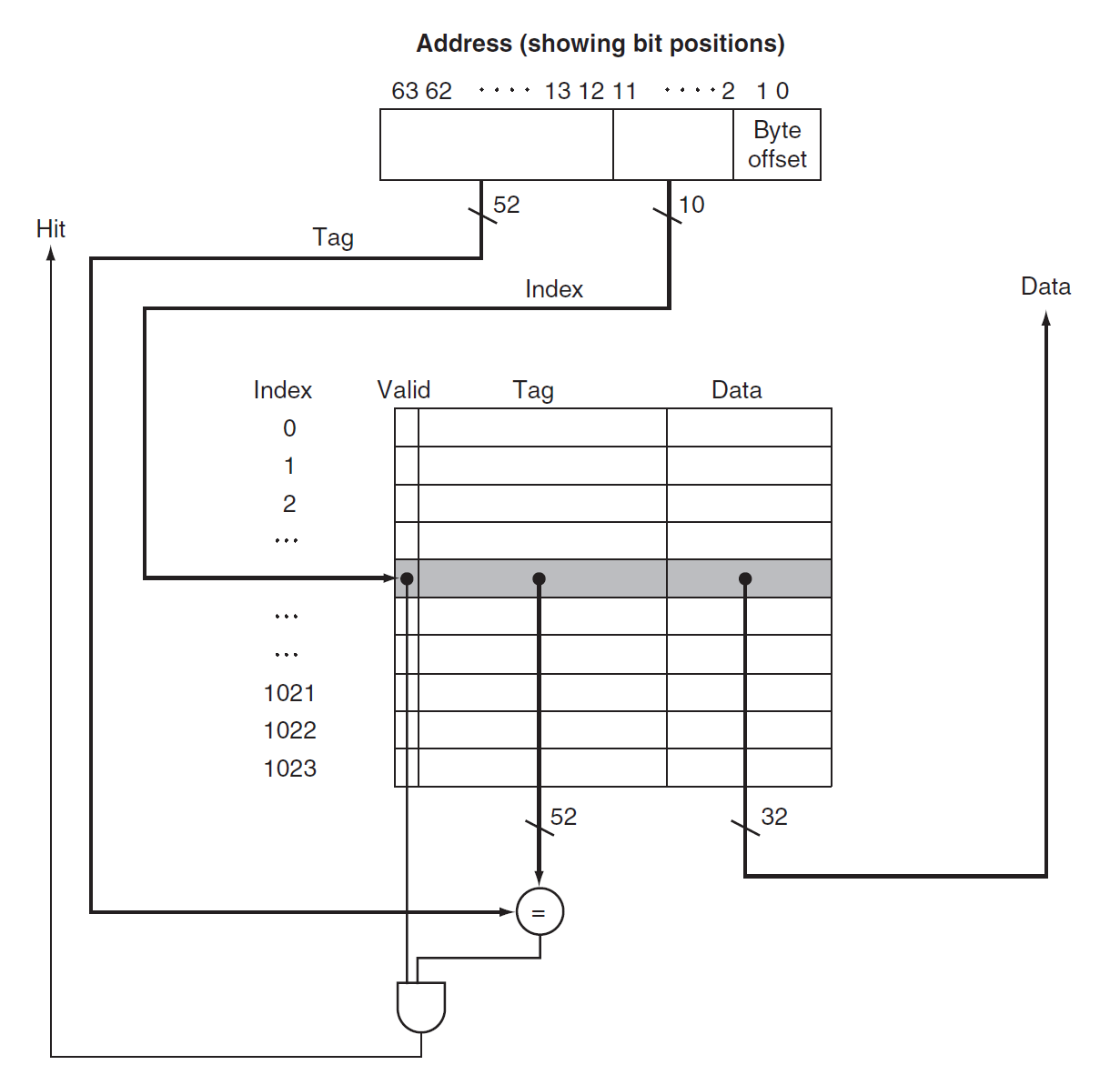
Block Identification⚓︎
每个高速缓存块都有一个唯一的地址,而这个地址被分为多个字段,用于实现数据块的识别,具体可以分为:

- 块地址(block address)
- 标签(tag):检查某个高速缓存块是否为处理器所需要的数据块(比对一下标签是否匹配
) ,这个搜索过程一般是并行执行的 - 索引(index):在组相联中用于选择具体的组
- 位数 = \(\log_2(\#\text{sets})\)
- 如果是全相联的话,就没有索引位,因为没有组
- 相联程度越高,标签位越多,而索引位越少
- 标签(tag):检查某个高速缓存块是否为处理器所需要的数据块(比对一下标签是否匹配
- 块偏移(block offset):
- 位数 = \(\log_2(\text{size of block})\)
- 此外还有一位有效位(valid bit):用于表示某个高速缓存块是否持有有效地址。如果该位为 0 的话,表明地址无效,因此不能参与比较
下图展示了某个高速缓存的逻辑结构(从计组笔记那偷来的图
Block Replacement⚓︎
当失效发生时,控制器必须决定将哪个数据块作为被替换的块,用以存放处理器所需的数据。有以下几种可选的替换策略:
- 对于直接映射,由于每个数据块的位置是唯一的,所以无需选择,直接替换某个确定的数据块
- 对于组相联和全相联:
- 随机(random):在某个组中随机挑选一个块
- 最大的优点是实现简单,只需一个随机数生成器就能实现
- 生成的随机数应均匀覆盖到高速缓存中每一个数据块
- 缺点是可能会驱逐那些最近被访问的块
- 最近最少使用(least recently used, LRU):替换最久没使用过的数据块(借助了时间局部性的特征)
- 缺点是实现复杂,所以可以使用某种 LRU 的近似实现,比如用一组 bit 来记录某个组内的数据块的访问情况 ß
- 先进先出(first in, first out):也是一种 LRU 的近似实现(因为 LRU 的实现较为复杂
) ,替换最早存在的数据块
- 随机(random):在某个组中随机挑选一个块
Write Strategy⚓︎
大部分的处理器 - 高速缓存访问操作都是读取操作,而且处理器需要等待读取完毕才能继续执行,而无需等待写入操作,所以为了遵循 "Make common case fast" 这一思想,我们需要着重优化读取高速缓存的表现。然而,根据阿姆达尔定律,仅仅考虑读取的优化是不够的,我们还必须考虑写入操作的速度。
如果写入命中的话,通常会采取以下两种策略之一:
-
写穿(write through):写入的信息除了写入高速缓存的数据块外,还会写入下一级内存的数据块里。
- 优点:实现简单,简化数据一致性(data coherency) 的实现
- 处理器必须等待写穿完成才能继续执行下一步,这种情况称为写停顿(write stall)。为了减少这种情况的发生,一种常见的优化方法是增加一个写缓冲区(write buffer),允许处理器在数据写入缓冲区的同时继续执行后续任务,实现了处理器执行和内存更新这两项工作的重叠,节省时间。
-
但如果处理器的频率太高,且有很多的存储指令,可能导致写缓冲区的饱和(saturation)。缓解饱和问题的做法是在写缓冲区和主存之间再加一级(L2)高速缓存
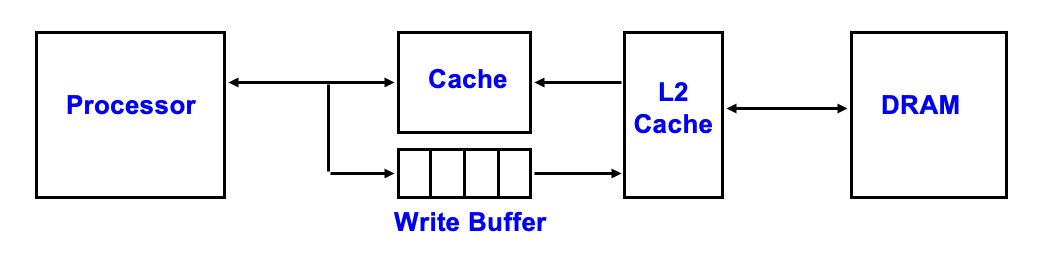
-
-
写回(write back):信息只写入到高速缓存的数据块内。但是一旦高速缓存中被修改过的数据块(脏块)里将要被替代,那么要将这个数据块写入到下一级内存中,确保之前的更新作用于底层内存中。
- 此时高速缓存引入一个脏位(dirty bit),作为记录某个数据块的修改情况的状态位。当脏位置 1 时,表明这个数据块是“脏”的(即被修改过了)
- 优点:速度快(对高速缓存的多次写入的同时,可能只需对主存写入一次
) ,使用更少的内存带宽(更适用于多核处理器) ,省电
对于 I/O 设备和多核处理器而言,它们希望同时有写回策略的速度和写穿策略的数据一致性。
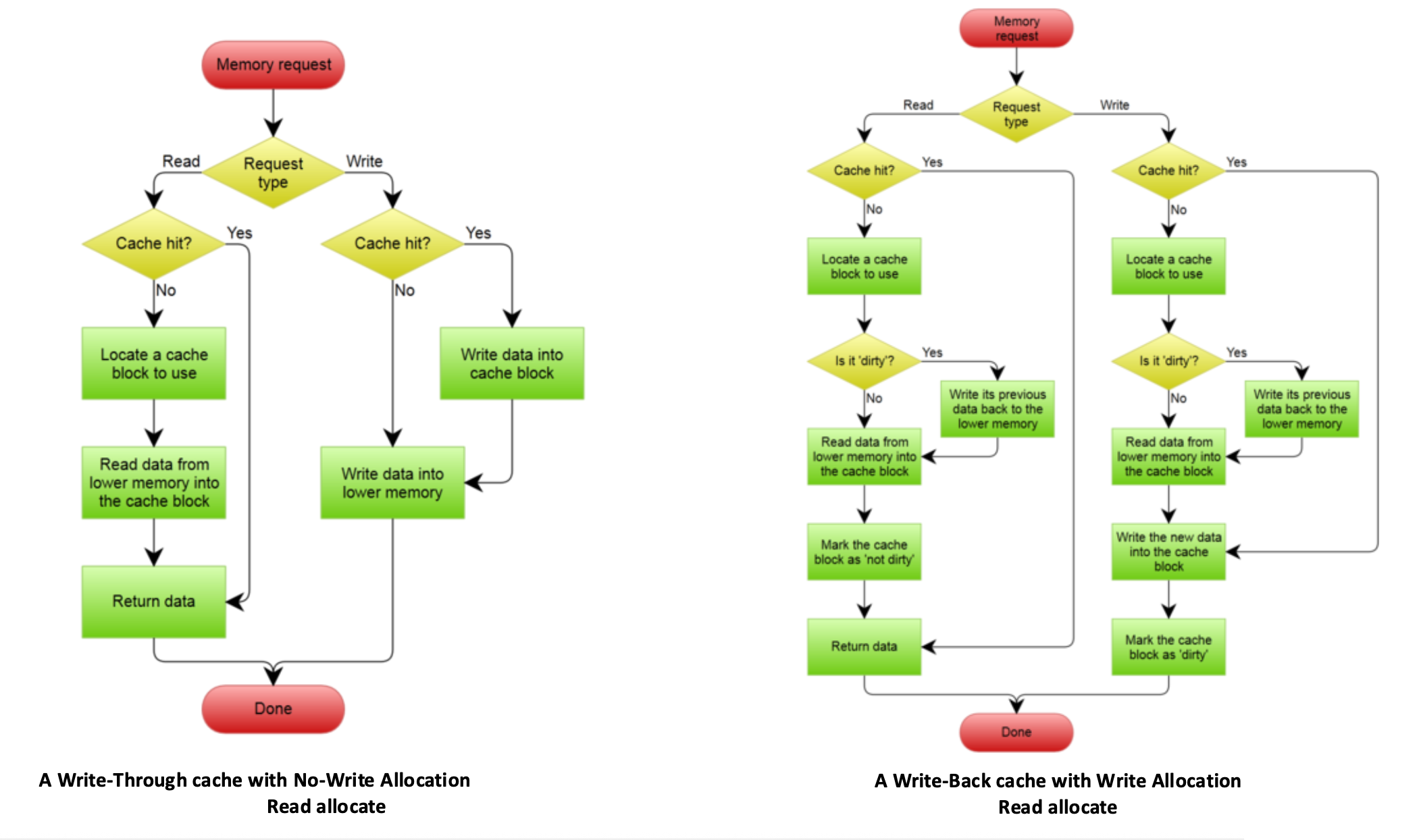
如果写入失效的话,则会采取以下两种策略之一:
- 写分配(write allocate):当写入失效发生时,首先将目标地址所在的整个数据块从主存(或下一级缓存)加载到高速缓存中,然后再对这个新加载的高速缓存块执行写入操作。
- 对应写回策略
- 非写分配(no-write allocate/write around):数据直接写入主内存(或下一级高速缓存
) ,而不将该数据块加载到当前高速缓存中,使写失效不影响高速缓存。- 对应写穿策略
下图展示了执行这两类写策略的流程图:
例子


备考建议(来自 hsb 的 PPT)
Cache⚓︎
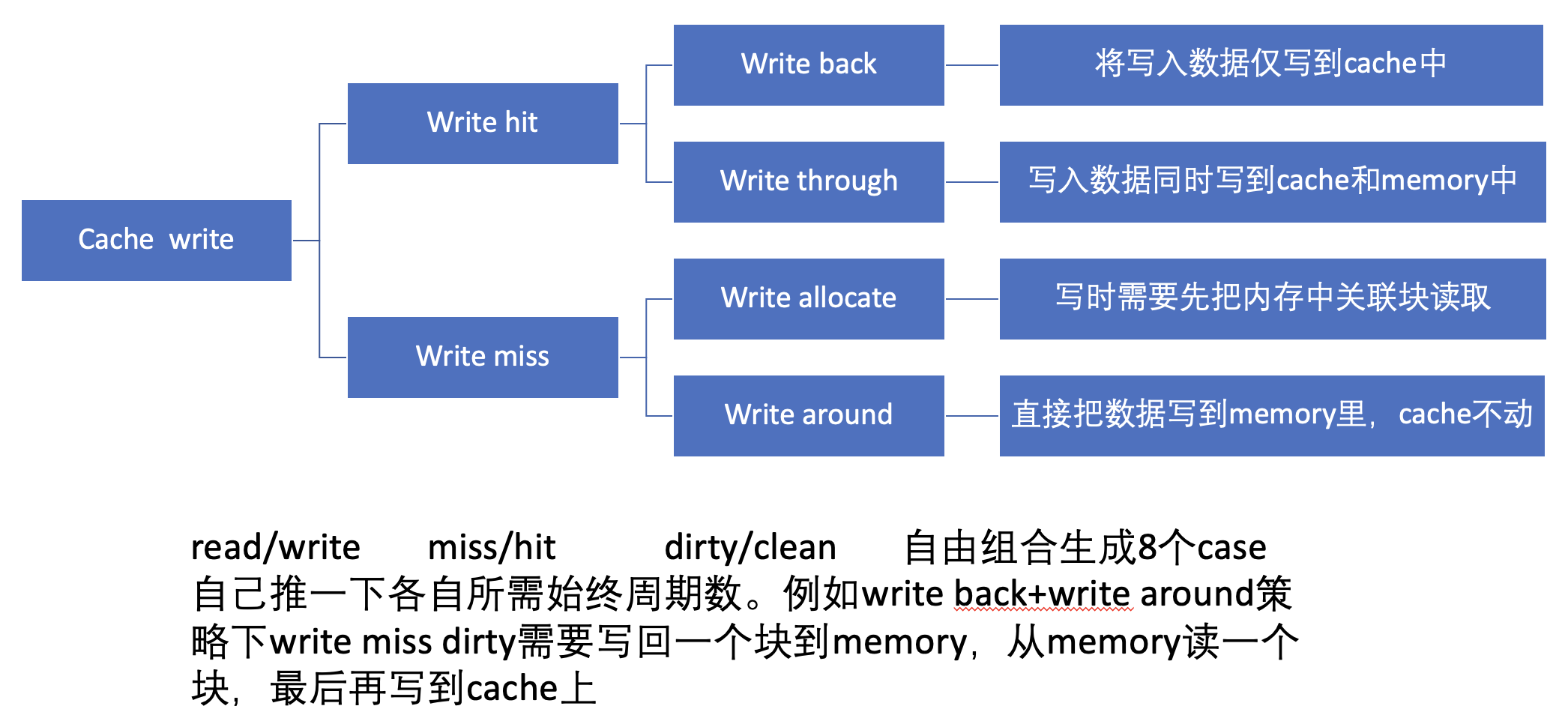
补充知识:统一缓存 vs. 分离缓存
- 统一缓存(unified cache):指令和数据共享同一个缓存空间
- 处理器在需要指令时从该缓存中获取,在需要数据时也从该缓存中获取
- 理论上,这类缓存可以更好地利用缓存空间,且硬件得以简化;但存在指令和数据访问会相互竞争缓存端口和带宽的问题
- 分离缓存(split cache):指令和数据拥有各自独立的缓存空间
- 通常,指令缓存(I-cache) 用于存储指令,数据缓存(D-cache) 用于存储数据
- 优点是允许处理器在同一周期内获取指令和数据(我们熟知的流水线 CPU 就是这么做的
) ,且指令流和数据流是独立的,互不干扰
Performance⚓︎
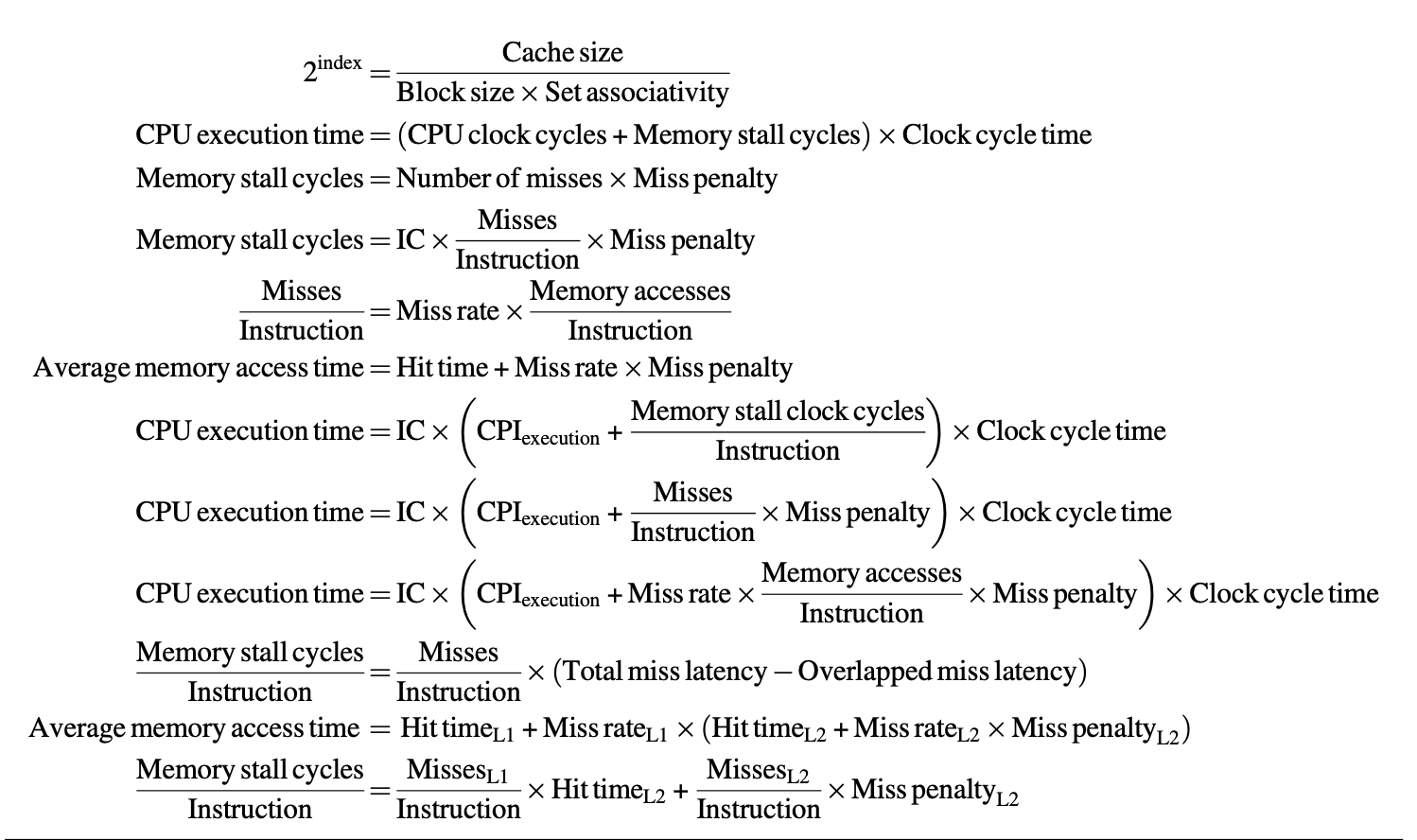
我们可以将上一章介绍的处理器执行时间的计算公式用于评估高速缓存的性能,不过需要额外加上存储器停顿周期数(memory stall cycles):
而存储器停顿周期数由失效数和失效损失(miss penalty) 共同决定:
- 其中最后一行式子更容易计算,因为这些量更容易被测量
- 失效损失实际上会随情况发生变化,但便于计算,我们就假定它是一个常数
- 失效率(miss rate):导致失效的高速缓存访问的比重
-
此外,失效损失和失效率在读和写的情况下会有所不同,所以如有必要可以分开讨论:
\[ \begin{align} \text{Miss stall clock cycles} = & \text{IC} \times \text{Reads per instruction} \times \text{Read miss rate} \times \text{Read miss penalty} \notag \\ & + \text{IC} \times \text{Writes per instruction} \times \text{Write miss rate} \times \text{Write miss penalty} \notag \end{align} \]但还是为了便于讨论,之后不会做这种区分。
-
有时,使用每条指令的失效次数(misses per instruction) 来衡量失效率,比原先用每次存储器访问的失效次数来衡量可能更好,因为这一指标和硬件实现无关。它们之间的关系为:
\[ \dfrac{\text{Misses}}{\text{Instruction}} = \dfrac{\text{Miss rate} \times \text{Memory accesses}}{\text{Instruction count}} = \text{Miss rate} \times \dfrac{\text{Memory accesses}}{\text{Instruction}} \]但这一指标的缺点在于它取决于架构实现。
如上所述,实际上无论是直接拿指令数,还是拿失效率作为衡量指标,都是有一些缺陷的,更好的测量方法是使用平均存储器访问时间(average memory access time, AMAT) 作为指标,对应的计算公式为:
- 单位可以是绝对时间,也可以是周期数
- 这种方法实际上还是一种间接的测量方法
例子






注意
在最后的计算中,教材误以为失效损失为 200 个时钟周期(题目说的是 100 个时钟周期






Impact of Caches on Processor Performance⚓︎
下面来探讨高速缓存的 AMAT 对处理器性能的影响。
- 虽然实际上可能有其他原因导致处理器的停顿,但为了便于讨论,我们假定只有存储器的停顿导致处理器的停顿
- 对于有序处理器而言,AMAT 确实能预测处理器的性能;但是对于乱序处理器(之后的章节会介绍)而言就没那么简单了
- 高速缓存的失效对于低 CPI 和高时钟频率的处理器而言有双重影响:
- \(\text{CPI}_{\text{execution}}\) 的值越低,高速缓存失效周期数的相对影响更大
- 即使对于两个存储器层级相同的两台电脑而言,时钟频率更高的处理器在每次失效中会有更多的时钟周期数,因此存储器在 CPI 的占比会更高
例子
下面来看一下不同的高速缓存组织对处理器性能的影响:



Out-of-Order Execution Processors⚓︎
对于乱序处理器而言,一件麻烦的事就是如何定义“失效损失”。下面我们仅将不重叠的时延作为失效损失来考虑,具体公式为:
我们需要考虑以下两点:
- 存储器时延的长度:在乱序处理器中,将什么东西考虑为存储器操作的开始和结束?
- 时延重叠的长度:什么是处理器内重叠的开始?
鉴于乱序执行处理器的复杂性,上述两个因素不存在唯一的正确定义。由于仅当操作到达提交流水线阶段时方可见,若处理器未能按该周期最大可能数量提交指令,我们认定它在某一时钟周期内停顿。我们将此停顿归因于首条无法被提交的指令。
对于时延的测量,我们可以从内存指令进入指令窗口队列时开始计时,或自地址生成时刻起算,亦可选择在实际向内存系统发送指令时启动计量。只要保持方法一致性,任一选择皆可行。
总之,尽管对乱序处理器中内存停顿的定义和测量相当复杂,但必须认识到这些问题会显著影响性能。这种复杂性源于乱序处理器能够在不损害性能的前提下,容忍由缓存失效引起的部分时延。因此,设计者在评估内存层次结构的权衡取舍时,通常会采用乱序处理器及内存的模拟器进行验证,以确保那些改善平均内存延迟的措施确实能提升程序运行效能。
例子

preceding example 如下:


性能计算公式汇总
Basic Optimizations⚓︎
根据 AMAT 的计算公式,我们可以得到以下三种提升高速缓存性能的方向,以及对应的优化方法:
- 降低失效率:更大的数据块,更大的高速缓存,更高的相联程度
- 降低失效损失:多级高速缓存,给予读取更高的优先级
- 降低命中时间:在索引(动词)高速缓存时避免地址的转换
在详细介绍这六种优化方法前,我们先为失效的情况分分类(称为 3C 模型
- 强制(compulsory)(也称为冷启动失效 (cold-start misses)/ 第一次引用失效 (first-reference misses)
) :最开始访问高速缓存的数据块时必定出现失效情况,此时对应的数据块必须先被带入到高速缓存中。 - 容量(capacity):在程序执行的过程中,高速缓存无法包含所有需要的数据块,于是不得不抛弃一些数据块,但之后可能又需要检索这些数据块,此时失效发生
- 冲突(conflict):对于组相联 / 直接映射而言,由于多个数据块映射到相同的组上,导致较早存入的数据被替换,使得后续访问时发生失效
注
其实还有第 4 个 C——一致性(coherency) 失效,它主要针对多核处理器的高速缓存。不过这个 C 不在本章的讨论范围内。
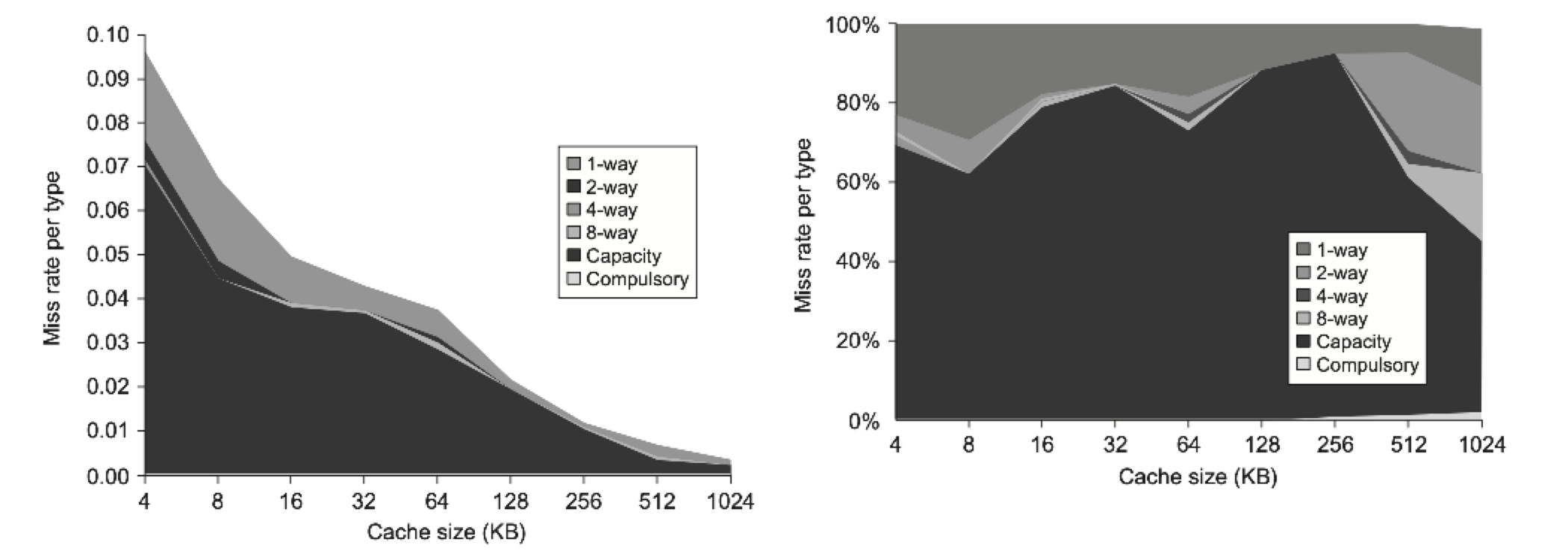
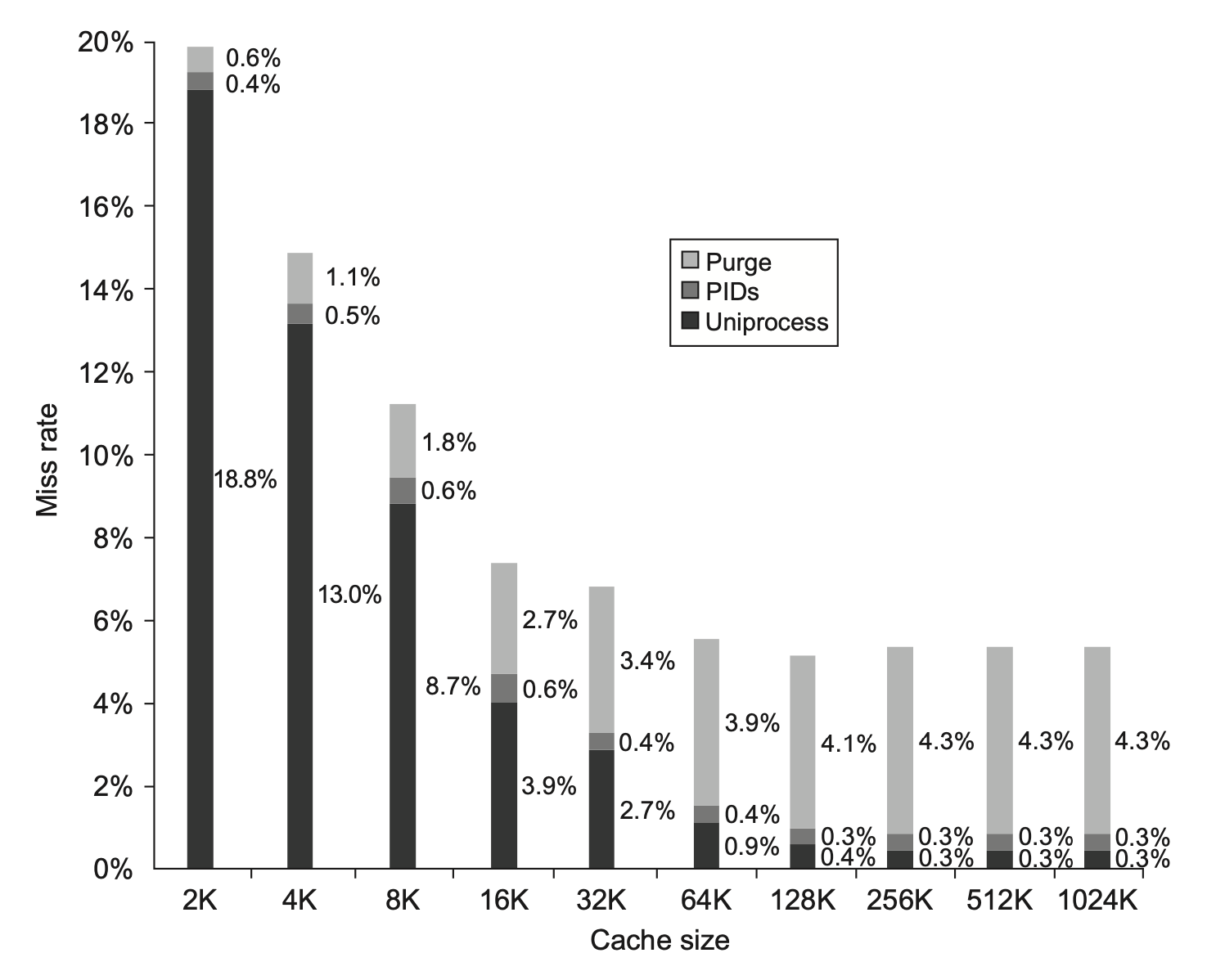
下面两张图分别展示了对于不同大小的高速缓存,3C 模型在总失效率和失效率分布上的情况:
现在我们来思考一下如何解决这三类失效问题:
- 最容易解决的是冲突失效——采用全相联的置放方案就可以完全避免此类失效问题,但这种理论上很简单的做法花费的实际成本较大,且会降低时钟频率
- 对于容量失效,唯一能做的就是扩大高速缓存的容量,因为上级存储器容量过小的话会导致数据传输和置换时间的增加,从而带来存储器层级的抖动(thrash) 问题
- 而对于强制失效,可以通过增大数据块容量来解决,但是这会导致其他失效的增加
3C 模型存在一些局限:
- 它只考虑了平均情况,而无法很好地解释个别的特殊情况
- 它同时忽视了替代的策略
所以,接下来我们将会看到:没有一种十全十美的优化方法,需要我们结合具体情况做好权衡。在正式介绍优化方法前,可以先瞄一眼下面这张总结图,留个总体的印象;等阅读完这六大优化方法后,再回过头来看这张图,这样有助于更好地理解这些优化方法带来的提升以及不足。
总结:六大基本的高速缓存优化方法
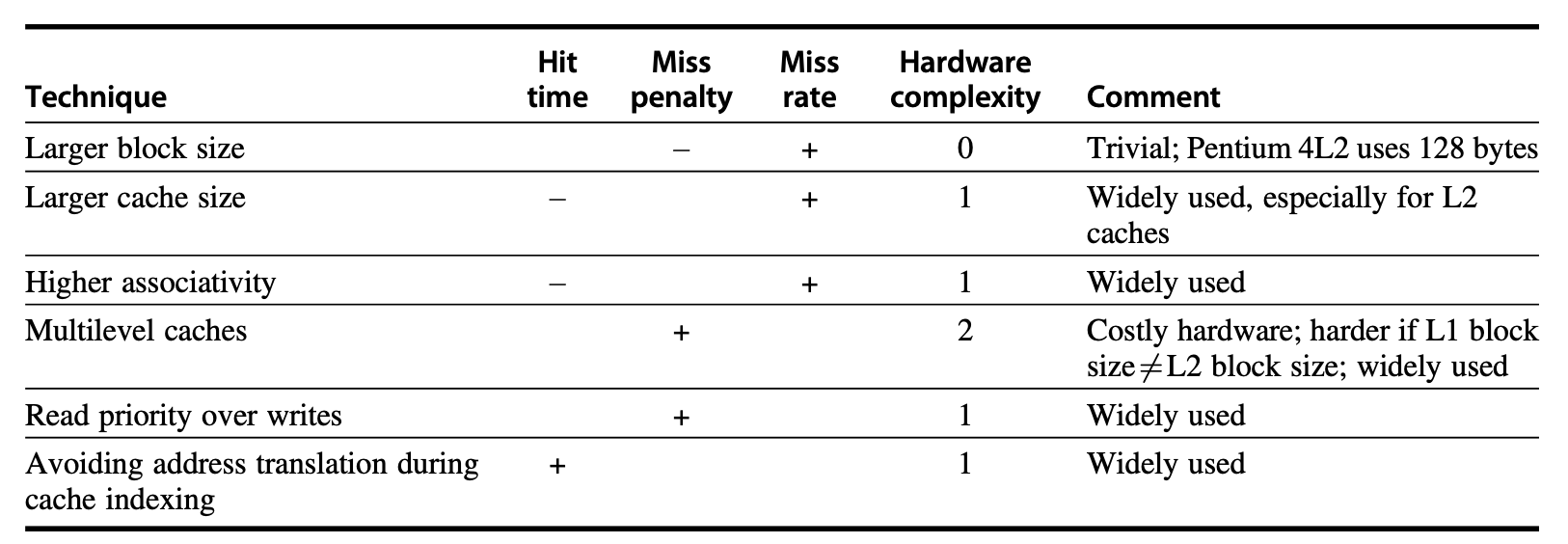
+表示对该因素起到提升作用-表示对该因素起到负面影响- 空白表示没有影响
Larger Block Size⚓︎
降低失效率的最简单的方法是增大数据块的大小,它借助了空间局部性的优势,可以减少强制冲突的发生。
同时,更大的数据块还会提升失效损失,因为对于相同大小的高速缓存,数据块的数量会随之减少,从而导致冲突失效乃至容量失效的发生(当高速缓存较小时
具体来说,数据块大小的选择需要同时考虑下级存储器的时延和带宽。
- 如果时延和带宽都很大的话,那么考虑使用更大的数据块,因为此时高速缓存在每次失效中可以得到更多的字节数据,而失效损失的提升相对较小
- 但如果时延和带宽都很小的话,则鼓励使用更小的数据块,因为更大的数据块只能节省很少的时间
下图展示了五种不同大小的高速缓存在不同大小的数据块下的失效率:
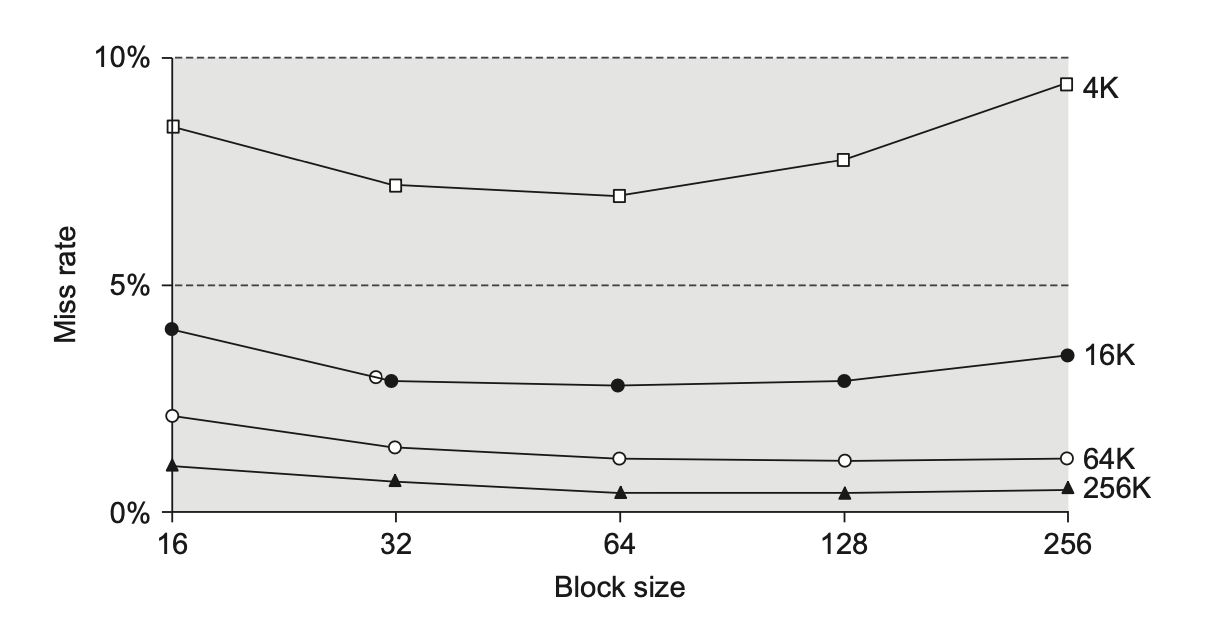
例子

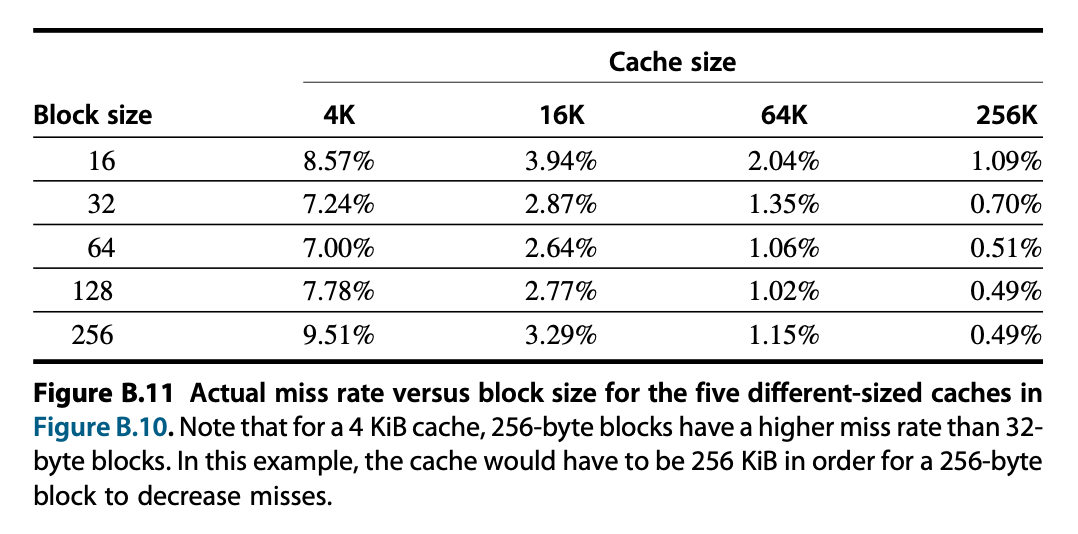

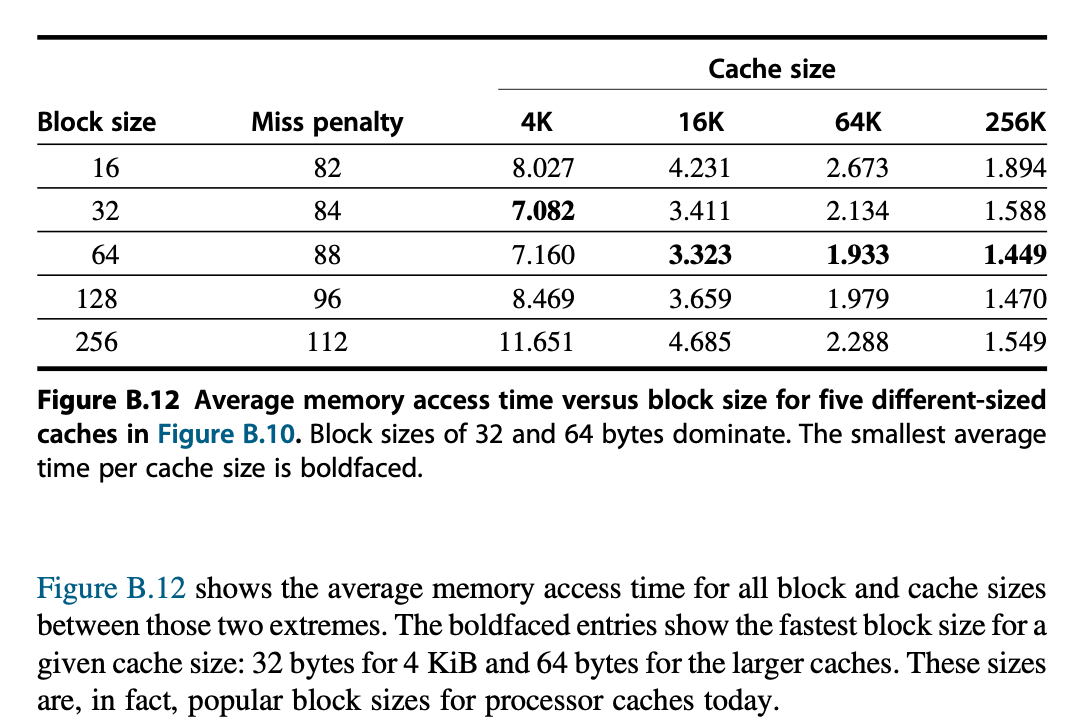


Larger Caches⚓︎
前面提到过,降低容量失效的一种方法是增大高速缓存的大小。但这样做的缺点是可能会带来更长的命中时间,以及消耗更高的成本和功率。
这种技术往往用于不在芯片上的高速缓存中。
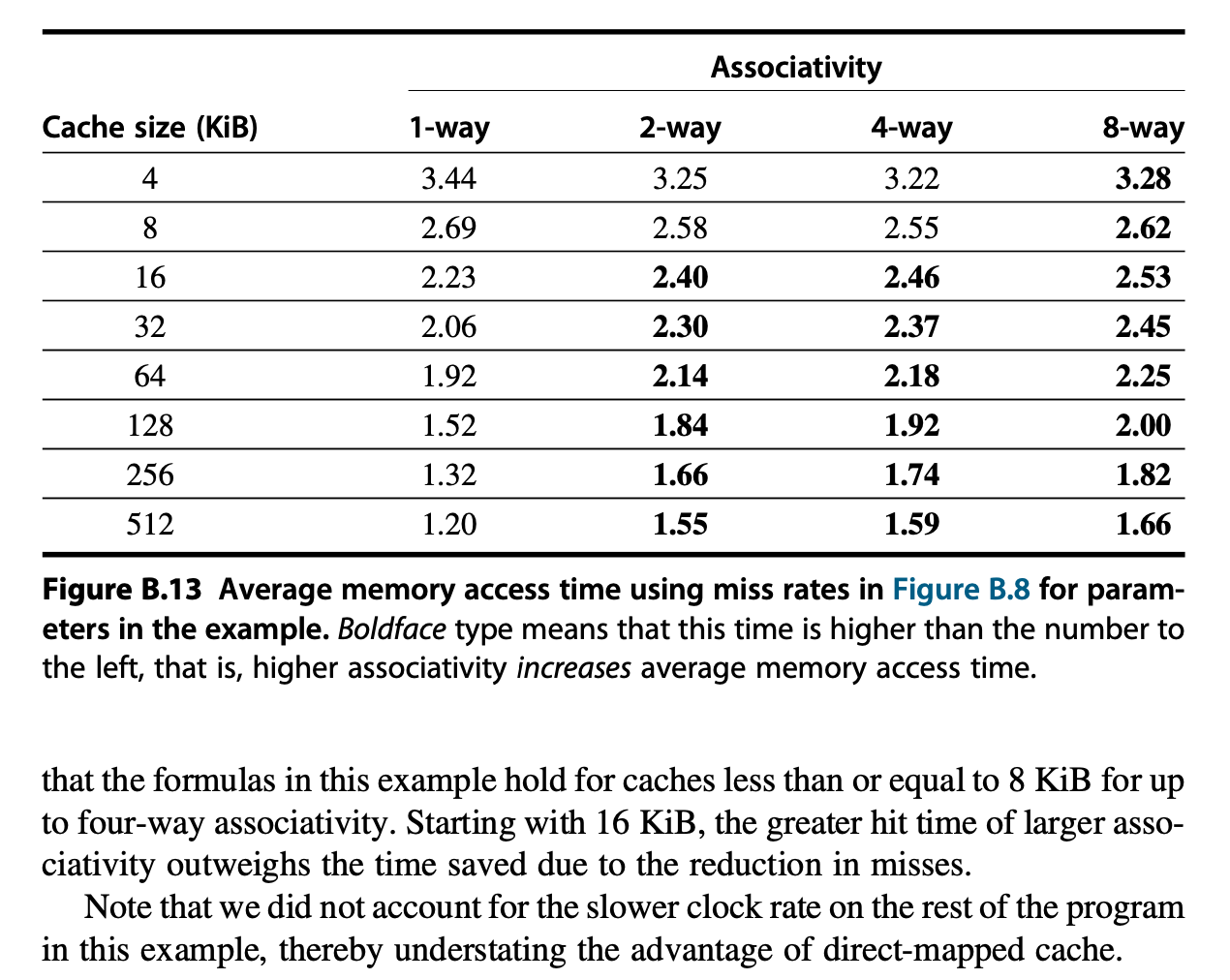
Higher Associativity⚓︎
在本节开篇介绍 3C 模型的时候,有两张关于 3C 模型与失效率相关的图表,里面也包含了和相联程度相关的内容。从这两张图表中,我们可以得到以下两条经验法则:
- 实际情况下,八路组相联降低失效的效果近乎等价于全相联的效果
- 2:1 高速缓存经验法则
: (对于 128KiB 以下的高速缓存)对于大小为 N 的直接映射的高速缓存,它的失效率与大小为 N/2 的二路组相联的高速缓存的失效率相等
相联程度的提高虽然能够降低失效率,但代价是增大了命中时间。因此,对于高时钟频率的处理器而言,不建议提升相联程度;而在失效损失较大的情况下,则鼓励提升相联程度。
例子


Multilevel Caches⚓︎
鉴于处理器和存储器之间的鸿沟,计算机架构师们会考虑这个问题:我们应该让高速缓存的速度变得更快,以跟上处理器的速度;还是应该让高速缓存变得更大,以克服处理器和内存之间不断变宽的鸿沟?那么鱼和熊掌是否可以兼得呢?——幸运的是,引入多级高速缓存(multilevel caches) 的概念,我们可以兼得鱼和熊掌!
我们先考虑最简单的情况——两级高速缓存:
- 第一级高速缓存(以下简称 L1)可以足够小,以跟上处理器的时钟周期
- 所以 L1 的速度将影响处理器的时钟频率
- 第二级高速缓存(以下简称 L2)可以足够大,以捕获更多对内存的访问
- 所以 L2 的速度仅对 L1 的失效损失有影响
- 如果 L2 不够大的话,反而会增加失效率
这样便能有效减少失效损失了。
引入多级高速缓存后,我们需要重新考虑 AMAT 的定义了——现在的计算公式变成了:
为了消除歧义,有必要在这里对“失效率”做进一步的阐述:
- 局部失效率(local miss rate) = 在某个高速缓存的失效次数 / 在该高速缓存中总的存储器访问次数
- L1 和 L2 的局部失效率分别为 \(\text{Miss rate}_{\text{L1}}, \text{Miss rate}_{\text{L2}}\)
- 全局失效率(global miss rate) = 在某个高速缓存的失效次数 / 来自处理器的总的存储器访问次数
- L1 和 L2 的全局失效率分别为 \(\text{Miss rate}_{\text{L1}}, \text{Miss rate}_{\text{L1}} \times \text{Miss rate}_{\text{L2}}\)
对于多级高速缓存而言,全局失效率是一种更合适的衡量指标。
如果不想考虑失效率的话,可以用每条指令的失效数作为衡量指标,计算公式为:
注
上述公式同时考虑到读取和写入操作,且假设 L1 采用写回策略。
下面这个例子能够展现这个指标相比 AMAT 的优越性:
例子



下面两张图分别展示了 L2 的大小对失效率和相对执行时间的影响:
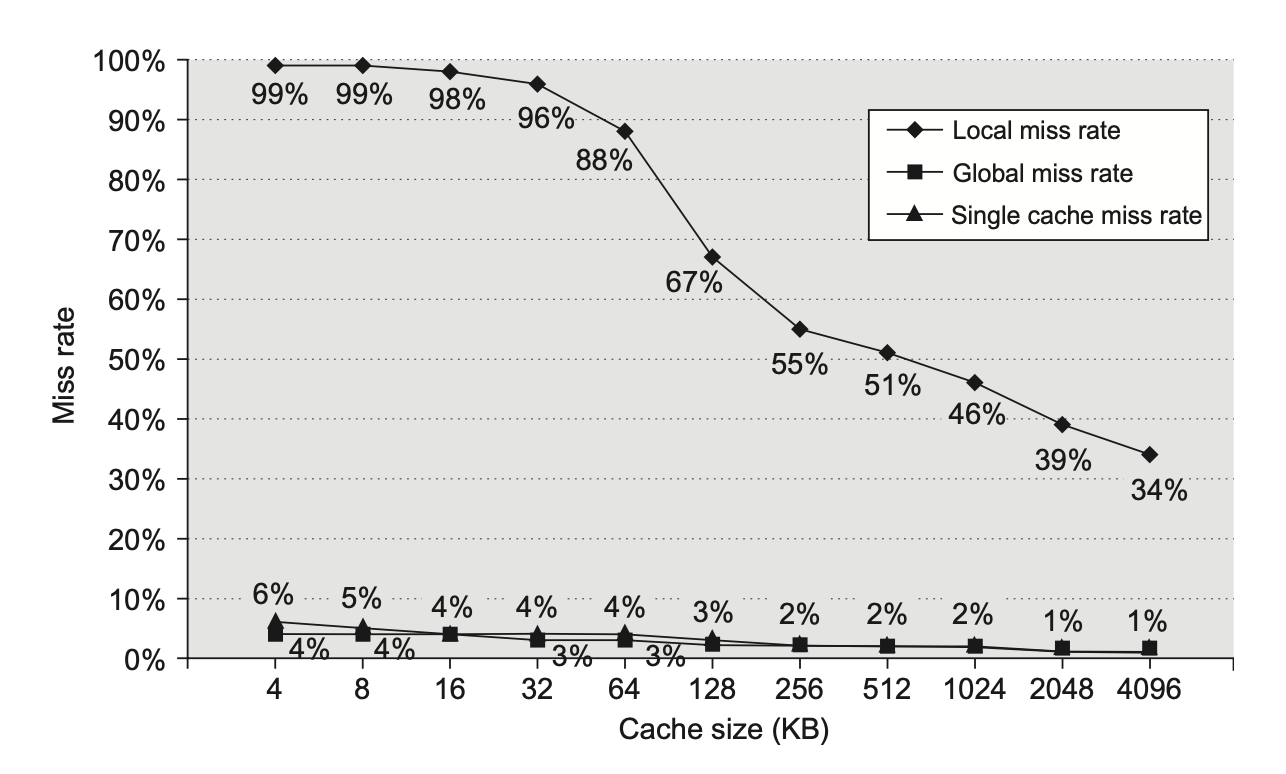
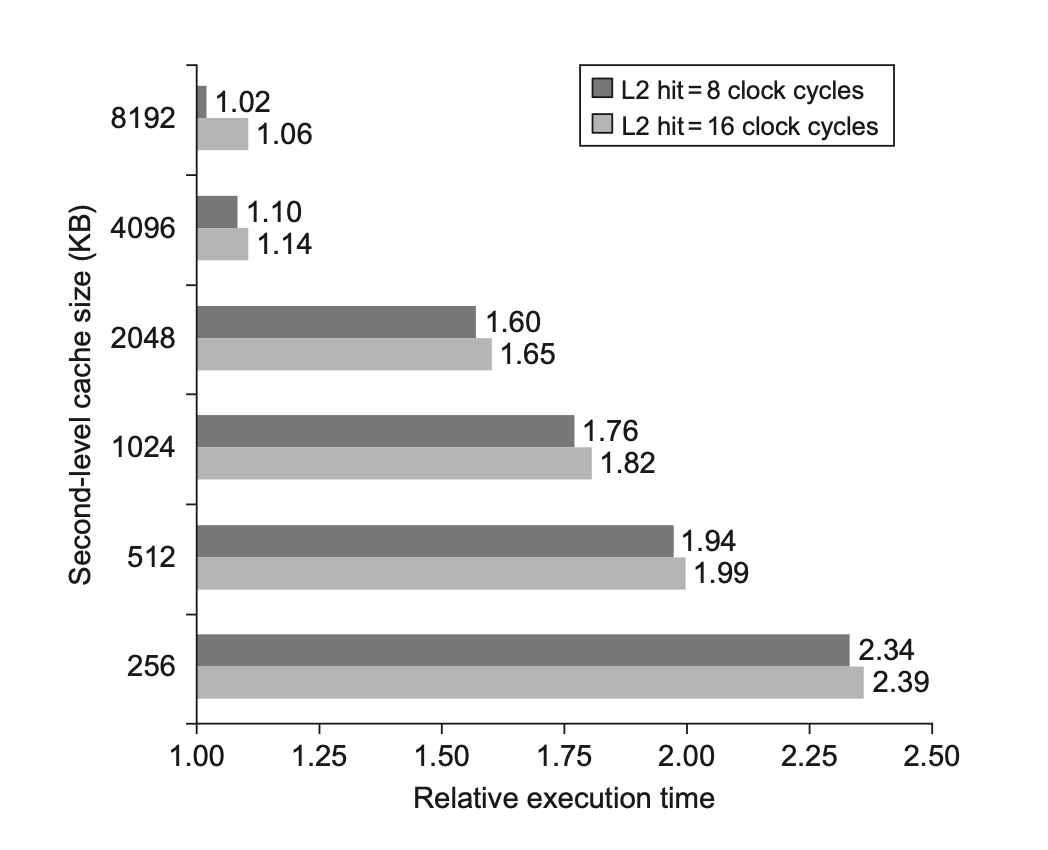
可以发现:
- 当 L2 足够大时,全局失效率与 L2 的失效率非常相似
- 局部失效率不是一个良好的二级高速缓存的衡量指标
此外,L2 的相联程度也会影响整个高速缓存的失效损失,具体见下面的例子:
例子

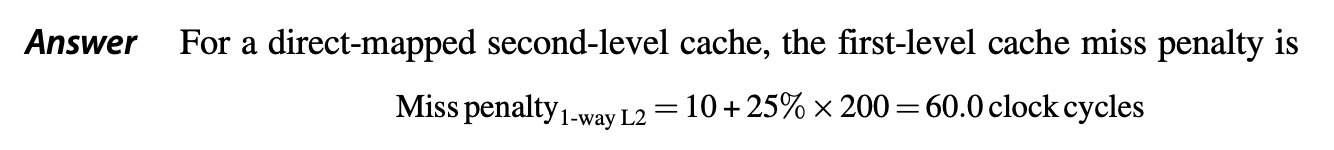

最后需要考虑的问题是:L1 内的数据是否需要出现在 L2 内?由此引出了两种策略:
- 多级包含(multilevel inclusion):L1 的数据永远都会在 L2 出现,这样可以确保数据的一致性
- 缺点是对于数据块大小不同的多级高速缓存中,需要做额外的处理工作,这样可能会略微提高 L1 的失效率。因此为了方便起见,很多高速缓存设计中会让各级的高速缓存保持相同大小的数据块。
- 多级排斥(multilevel exclusion):L1 的数据永远不会在 L2 出现
- 这适用于 L2 仅比 L1 稍大一些的情况。
- 当 L1 出现失效的情况时,交换 L1 和 L2 的数据,而非用 L2 的数据块替代 L1,以避免 L2 额外的空间浪费
Giving Priority to Read Misses over Writes⚓︎
在写穿策略中,我们会利用写缓冲区提升其性能。然而,写缓冲区虽然能提高写操作的效率,但它引入了一个复杂性:写缓冲区中可能包含了某个位置的最新更新值,而这个位置的数据可能在读失效时被请求。如果读操作直接从主存获取数据,而写缓冲区中的数据尚未写入主存,就会导致 RAW 数据冒险(即读到了旧数据
例子


我们有以下解决方案:
- 最简单但低效的方法是:让读失效操作等待,直到写缓冲区清空。但这会严重增加读失效的损失。
- 所以,普遍采用的优化方法是:当发生读失效时,检查写缓冲区的内容。
- 如果读请求的地址在写缓冲区中存在(意味着有待写入的最新数据
) ,则直接从写缓冲区获取数据。 - 如果没有冲突,并且内存系统可用,则允许读失效继续进行,从主存获取数据。
- 这种方法有效地赋予了读操作优先于写操作的权利。
- 如果读请求的地址在写缓冲区中存在(意味着有待写入的最新数据
即使是写回式高速缓存,写操作的开销也可以通过类似的方式减少:
- 当读失效需要替换一个“脏”的内存块时,不是先将脏块写回主内存,再从主内存读取新块,而是将脏块复制到写缓冲区中。
- 然后立即从主存读取新块
- 脏块的写回操作则在后台由写缓冲区处理。
- 同样,处理器在读未命中时也需要检查写缓冲区中是否有冲突的地址。
Avoiding Address Translation During Indexing of the Cache⚓︎
高速缓存需要完成从虚拟地址到物理地址的转换。
为了 "make common case fast",高速缓存会用到虚拟地址,因为这样会提高命中率,而这样的高速缓存称为虚拟高速缓存(virtual caches)(对应传统意义上使用物理地址的物理高速缓存(physical caches)
在高速缓存中,我们需要区分两件事:索引高速缓存(即找到对应的组)和比较地址(的标签位

看起来挺好的,但实际上没什么人会这样做,这是因为:
-
考虑到虚拟地址转换为物理地址时的页级保护机制
- 通过在失效时拷贝 TLB 上的保护信息,并用一个字段来保存这个信息,并且在每次访问虚拟高速缓存时进行检查来克服这个问题
-
歧义(ambiguity) 问题:每当切换进程时,相同的虚拟地址就会指向不同的物理地址,需要对高速缓存进行清除操作
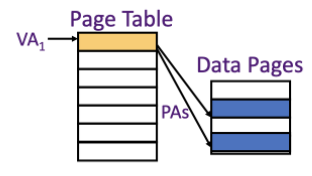
- 通过增加地址标签位的宽度,作为进程标识符标签(process-identifier tag, PID) 使用来解决这个问题。如果操作系统为进程赋予这些标签的话,它只需要清除那些 PID(用于区分高速缓存中的数据是否用于该程序)被回收的标签,避免过多的清除操作,从而降低失效率:
-
操作系统和用户程序可能使用两个不同的虚拟地址来指代同一个物理地址
- 这些重复的地址称为同义词 (synonyms) 或别名(aliases)
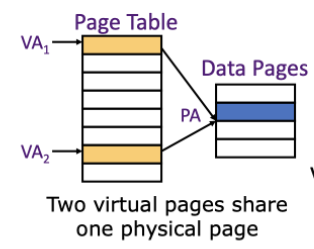
- 硬件层面上,解决此问题的方法是反别名(antialiasing):确保每个高速缓存数据块对应唯一的一个物理地址
- 软件层面上,解决此问题的方法是强迫这些别名共享一些地址位,这种限制称为页着色(page coloring),可以看作是组相联在虚拟内存中的应用。该方法能有效提升页偏移量,因为它保证了虚拟地址和物理地址最后的某些位是相同的
-
I/O 设备
一种可以同时利用虚拟高速缓存和物理高速缓存优势的方法是虚拟索引,物理标签(virtually indexed, physically tagged):
- 使用虚拟地址和物理地址中页偏移量相同的那部分来索引高速缓存
- 同时在使用该索引读取高速缓存的时候,转换地址的虚拟部分
- 并且用标签匹配物理地址
- 该方法实现了立即读取高速缓存的数据,并且仍然使用物理地址进行比较。
下图展示了从虚拟地址到 L2 高速缓存访问的存储器层级原理图:
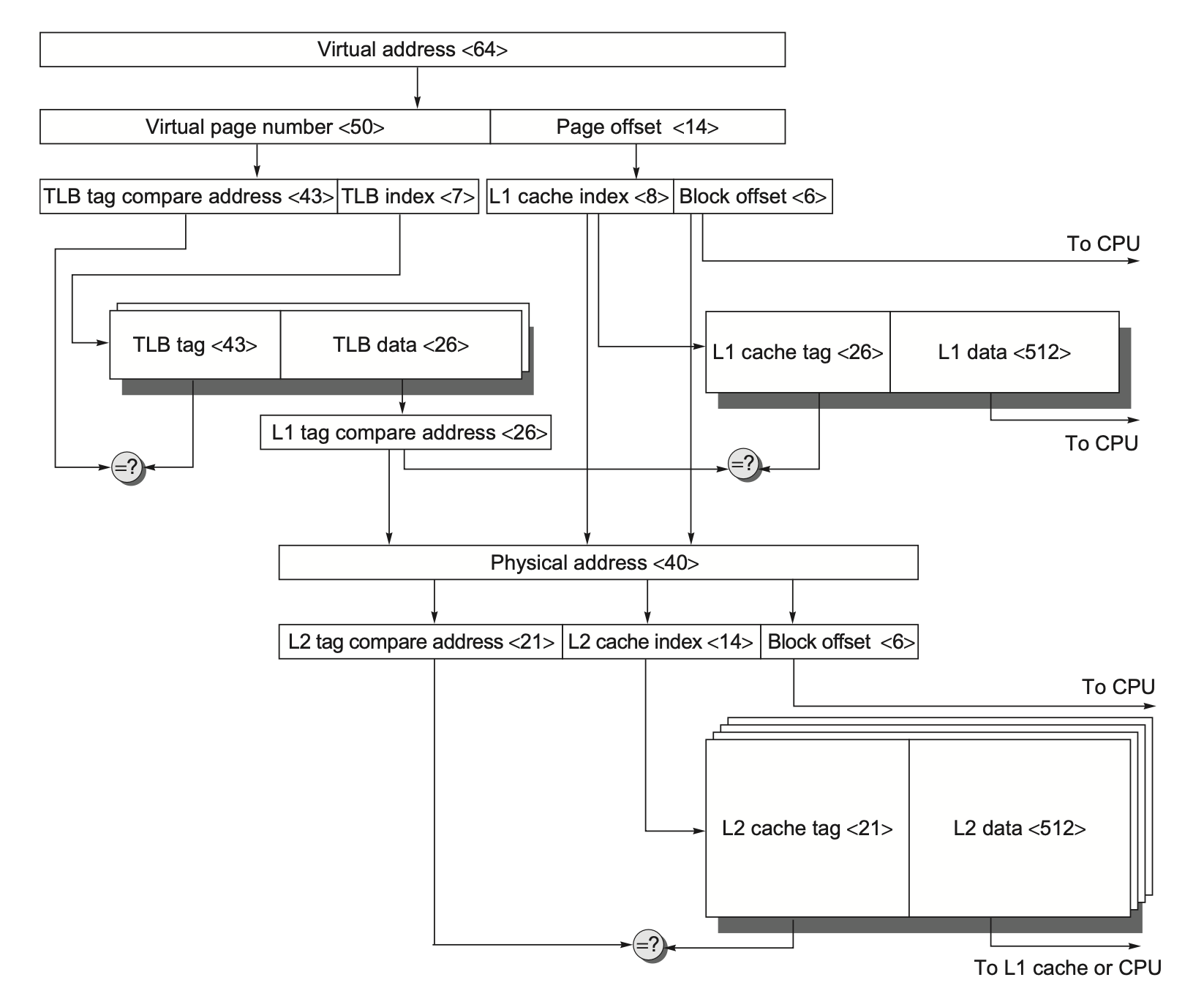
相联程度可以保留地址物理部分内的索引,并且仍然可以支持较大的高速缓存。
例子

虽然这道题涉及到“虚拟索引,物理标签”的知识,但这里的“虚拟地址宽度”信息实际上并没有被用到。

Advanced Optimizations⚓︎
在高级优化方法中,我们除了考虑 AMAT 公式中的三个因素外,还要考虑高速缓存的带宽和功耗问题。根据这 5 个因素,将下面即将介绍的优化方法分个类(也包括了上面一部分的基本优化方法
-
减少命中时间:小而简单的一级高速缓存,路预测 (way-prediction)。这两种方法还能降低功率。
- 基本优化中的最后一个方案也属于此类
补充——追踪高速缓存(trace cache)
追踪高速缓存是一种特殊的指令缓存。它不存储物理上连续的指令块,而是存储动态执行的指令序列(即 trace
) 。其工作原理如下:
- 记录执行路径:当处理器执行程序时,追踪高速缓存会“观察”并记录实际执行过的指令序列,包括那些跨越了分支的指令。
- 存储追踪:这些动态执行的指令序列(追踪)被存储在追踪高速缓存中。一个追踪可以包含来自不同内存地址的指令,但它们在逻辑上是连续执行的。
- 预测与命中:当处理器需要获取指令时,它会尝试在追踪高速缓存中查找一个匹配的追踪。如果命中,处理器就可以一次性获取一个较长的、已经排好序的指令序列,而无需担心分支预测和指令获取的停顿。
- 构建追踪:如果追踪高速缓存失效,处理器会从传统的指令缓存中获取指令,并同时在后台构建新的追踪,以便将来使用。
应用
追踪高速缓存的典型应用是 Intel Pentium 4:

-
增加高速缓存带宽:流水线高速缓存 (pipelined caches),多分区高速缓存 (multibanked caches)。这两种方法对功率的影响视具体情况而定
-
减少失效损失:关键字优先,合并写缓冲区。这两种方法略微提升功率。
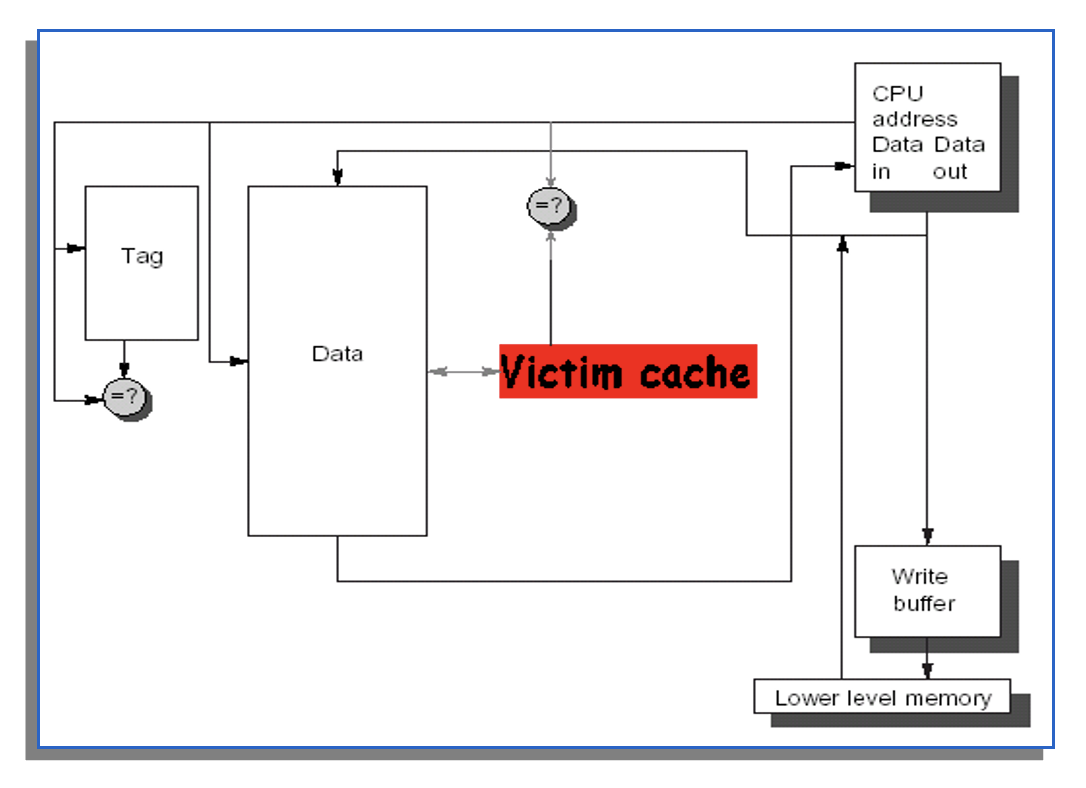
受害高速缓存 (victim cache)
这是一种小型、全相联的缓存,它位于主高速缓存和下一级内存之间。
其工作原理如下:
- 逐出时存储:当主高速缓存中的一个数据块被逐出时,它并不会直接被写回下一级内存,而是首先被移动到受害高速缓存中。
- 查找:当处理器发出一个内存访问请求时:
- 首先检查主缓存
- 如果主高速缓存失效,接着检查受害高速缓存
- 如果受害高速缓存失效,则将数据从受害高速缓存移回主高速缓存(通常是交换位置,即受害高速缓存中的数据块进入主高速缓存,主高速缓存中被替换的数据块进入受害高速缓存
) ,然后将数据提供给处理器。 - 如果受害高速缓存也未命中,则从下一级内存中获取数据。
- 替换策略:受害高速缓存通常采用 LRU 等替换策略来管理其有限的空间。
-
减少失效率:编译器优化。任何在编译时的提升能够降低功率。
-
通过并行减少失效损失或失效率:硬件预取,编译器预取。这两种方法都会提升功率,很可能是因为预取的数据没有被用到。
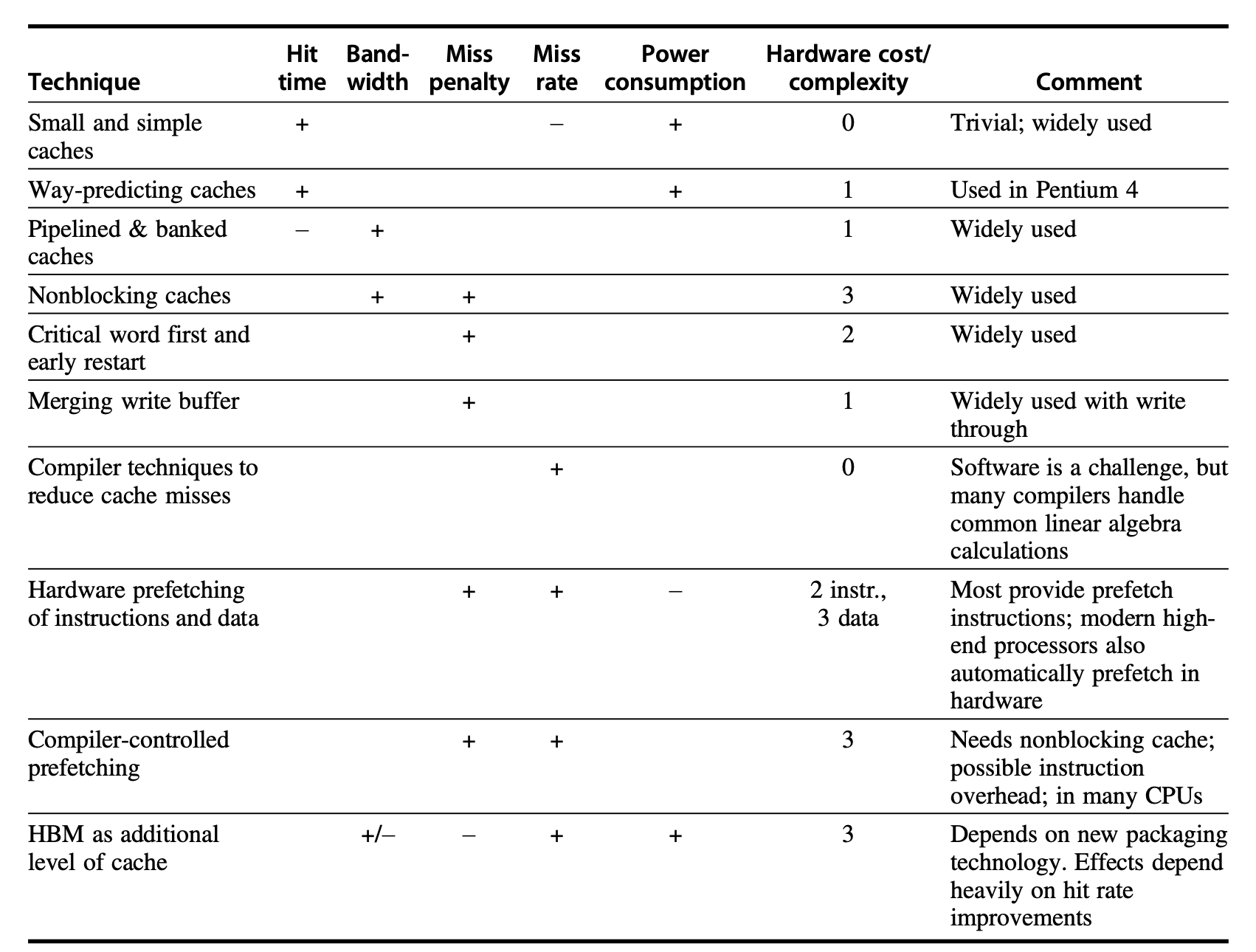
和介绍基本优化方法时一样,在开始之前也先放一张总结表格,可以先留个印象,学完后再回过头来看一遍,进一步加深印象。
总结:十大进阶的高速缓存优化方法
备考建议(来自 hsb 的 PPT)
- 可以将所有优化方法的要点完整地抄在 A4 纸上
- 计算题有空自己推一下
- 过程一定要写,至少有过程分。如果直接写答案错了没分
- 中间结果不要提前近似,一定要算到最后一步再近似
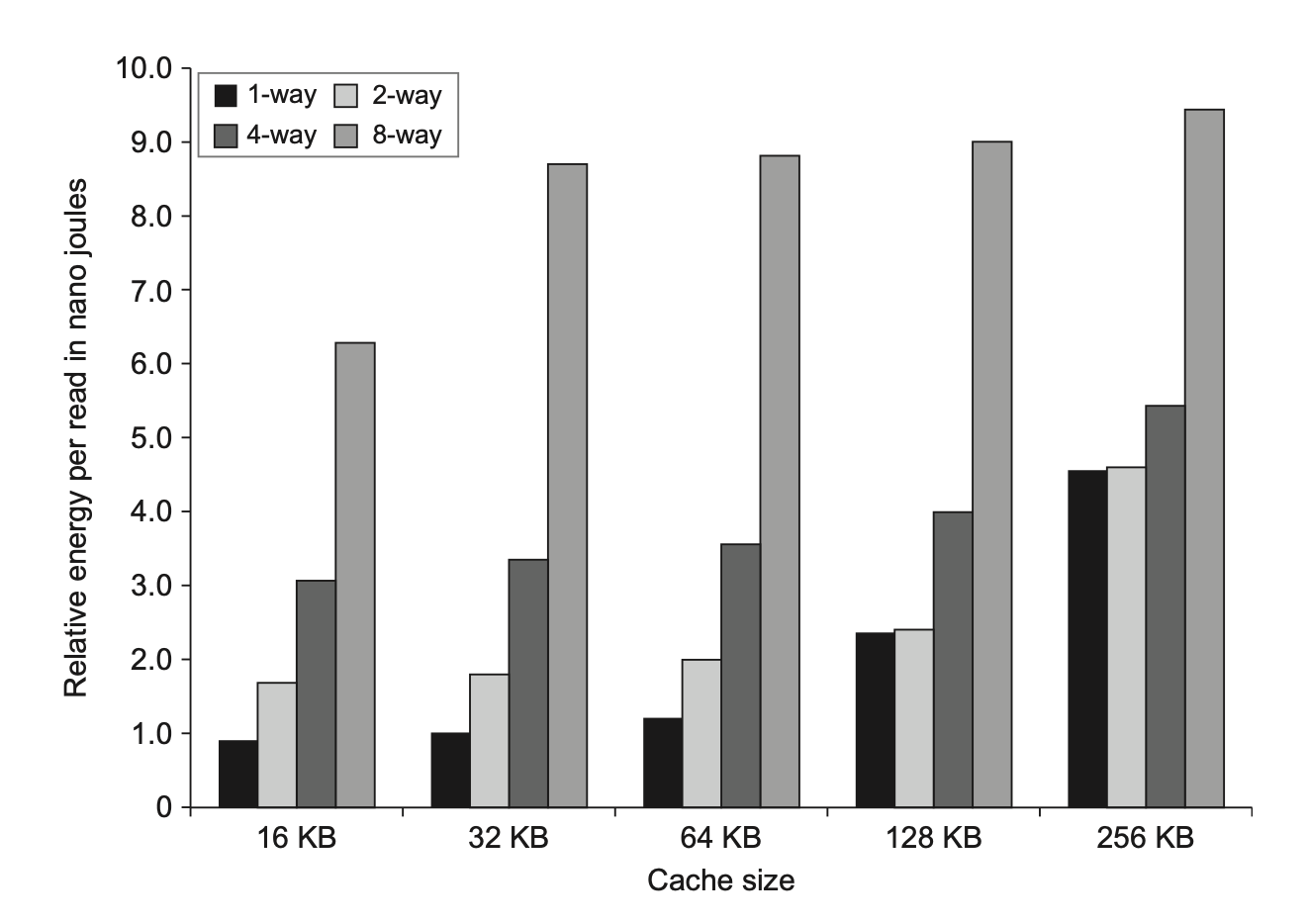
Small and Simple First-Level Caches⚓︎
减小一级高速缓存(以下简称 L1)的大小,或者降低 L1 的相关程度都有助于减小命中时间和功耗。
- 回顾高速缓存命中的过程
- 使用地址的索引部分找到待比较的组
- 使用地址的标签部分比较,检查是不是处理器所需要的数据
- 如果是的话,就通过 MUX 选择正确的数据项
- 所以,直接映射的高速缓存能够将 2-3 两步合并在一起(因为一个组里只有一个数据块
) ,从而降低命中时间;而且因为访问内容更少,还能降低功率 -
相联程度对命中时间的影响:
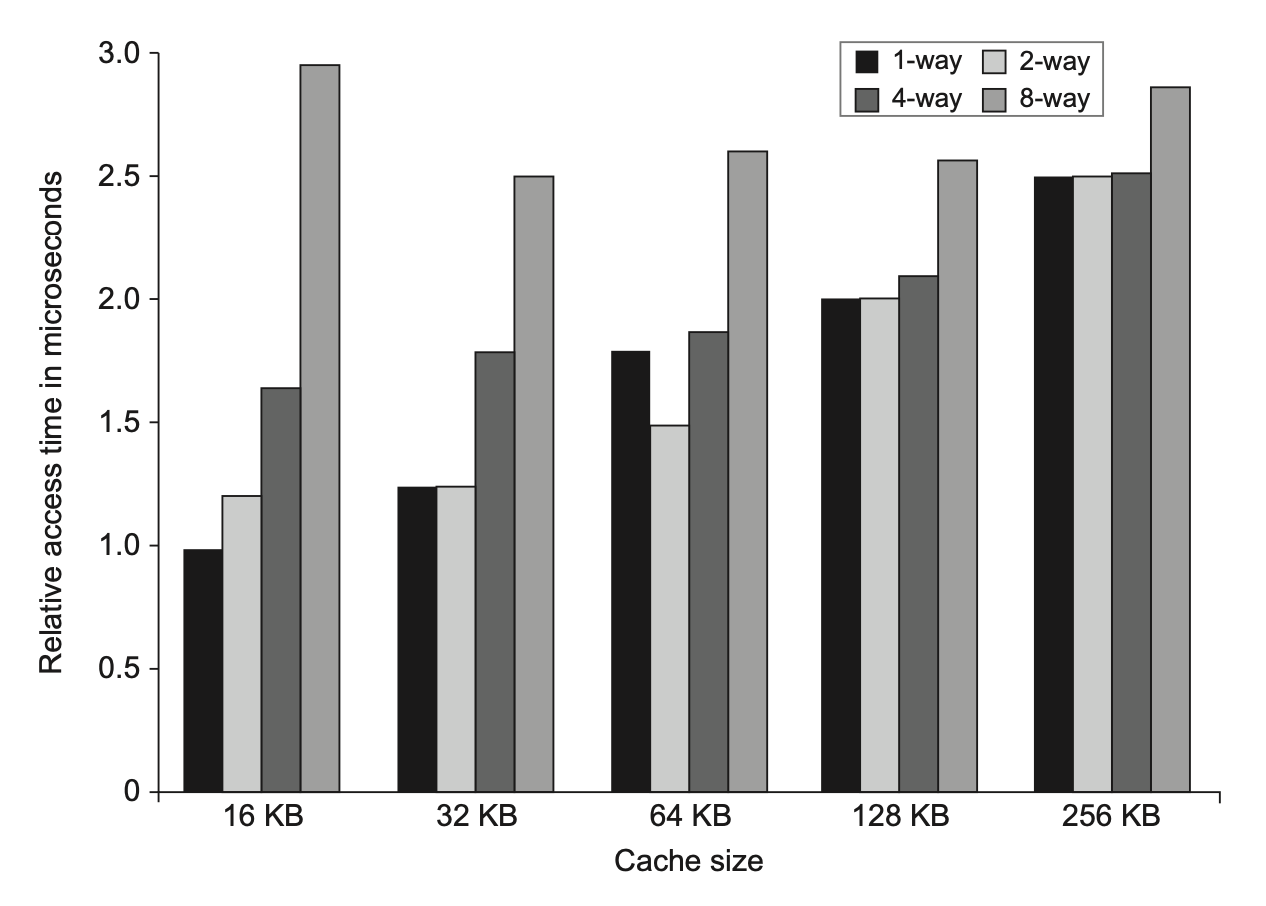
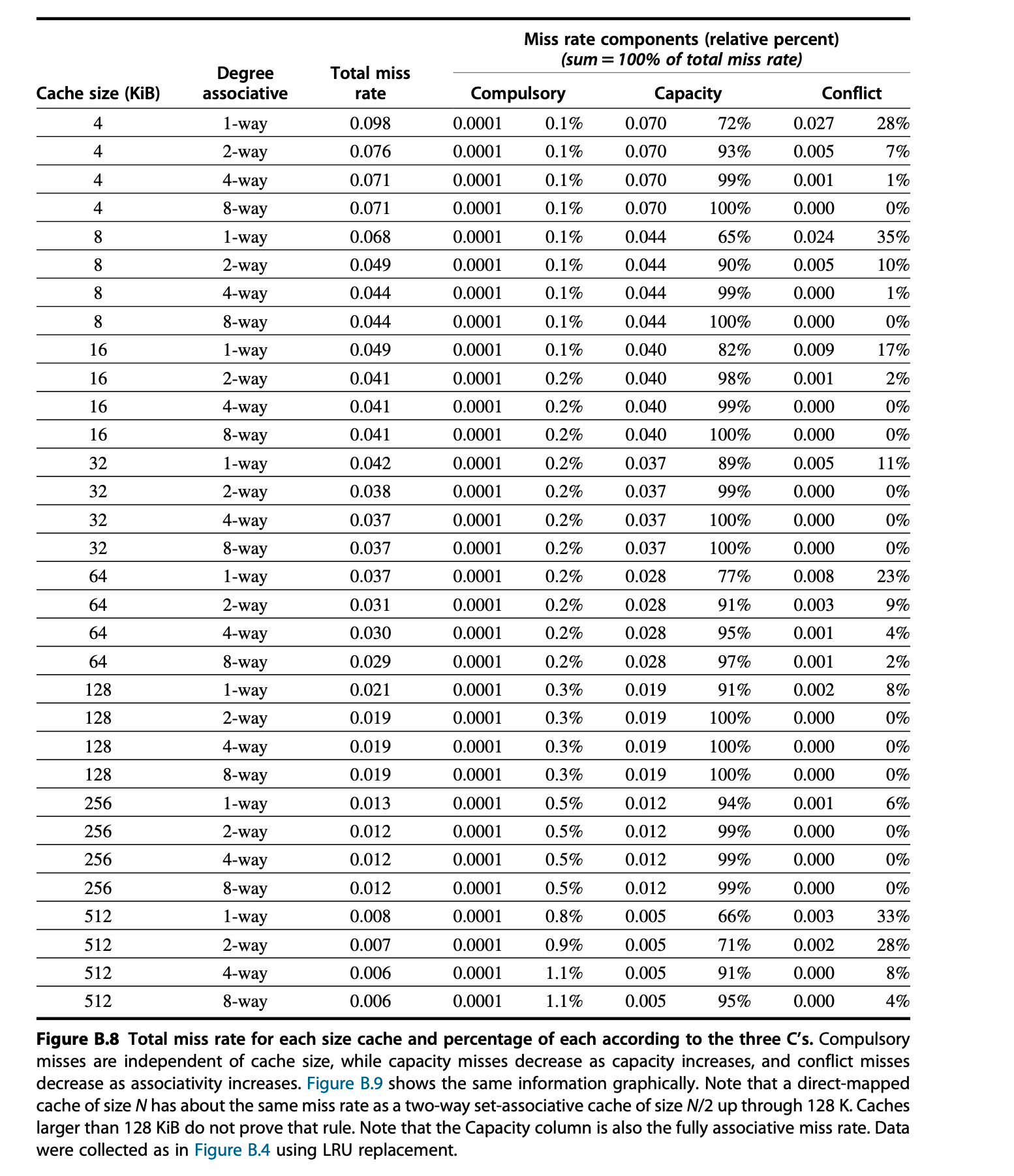
例子

Figure 2.8 就是上图,下图是 Figure B.8:

-
相联程度对功耗的影响:
-
最近的设计反而采用更高相联程度的高速缓存,这是因为:
- 很多处理器至少需要 2 个时钟周期来访问高速缓存,因此更长的命中时间并没有带来很大影响
- 为了减少 TLB 的延时,所有的 L1 都是虚拟索引的(有待进一步理解)
- 多线程导致冲突失效的增加,因而需要更高的相联程度
Way Prediction⚓︎
路预测(way-prediction):在高速缓存中保留额外的位(称为块预测器位(block predictor bit)
- 如果预测正确,高速缓存的访问时延就是很快的命中时间
- 如果预测失败,那么就要尝试下一个数据块,改变预测者的内容,并且会有一个额外的时钟周期时延
模拟结果表明:二路组相联和四路组相联的路预测准确率分别超过 90% 和 80%,且指令高速缓存相比数据高速缓存表现更好。
这种方法的一大缺点是加大了使高速缓存访问流水线化的难度。
Pipelined Access and Multibanked Caches⚓︎
使高速缓存访问流水线化以及采用多个分区(banks) 加宽高速缓存都能提升高速缓存的带宽。这些优化方法主要针对的是 L1,因为它的访问带宽会限制指令的吞吐量。但多个分区的做法同样可以用于 L2 和 L3 高速缓存中,但主要作为功率管理技术。
- 使高速缓存访问流水线化:带来更高的时钟周期数,代价是提升了时延
- 使指令高速缓存流水线化可以有效提升流水线 CPU 的阶段数量,但这样会导致更大的分支预测错误损失
- 使数据高速缓存流水线化可以在发射加载指令和使用数据之间增加更多的时钟周期数
- 指令高速缓存的流水线化相比数据高速缓存更为简单
-
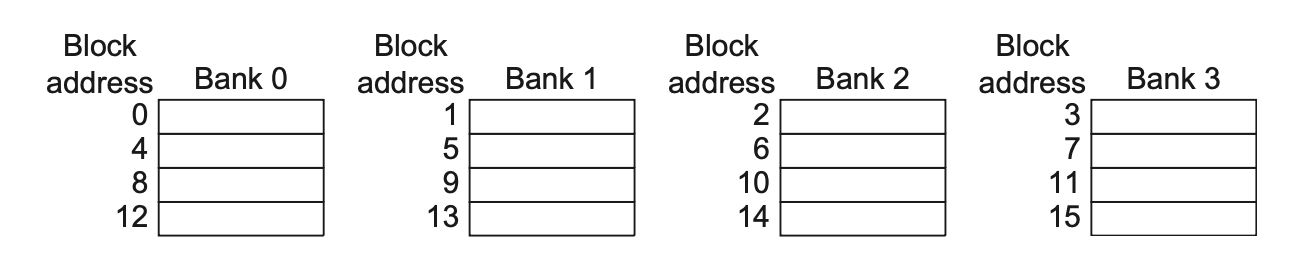
采用多个分区加宽高速缓存:高速缓存被分为独立的分区,每个分区支持独立的访问
- 当访问在这些分区中平均分布时,这种方法的表现最好,因此如何将地址映射到分区会影响到存储器系统的行为
- 一种简单的映射方法是按顺序将地址平均分配给每个分区,这样的方法称为顺序交错(sequential interleaving)
Nonblocking Caches⚓︎
乱序执行的流水线 CPU 不会在数据高速缓存失效时停顿,比如它在等待获取失效数据的同时还能继续从指令高速缓存中获取指令。而非阻塞的高速缓存(nonblocking caches) 允许数据高速缓存在失效发生时继续提供命中,从而发挥出乱序流水线 CPU 的潜在优势。这种 "hit during miss" 的优化方法能够降低失效损失。
一种更复杂,但能进一步降低失效损失的方法是 "hit under multiple miss" 或 "miss under miss":将多个失效重叠在一起。
例子


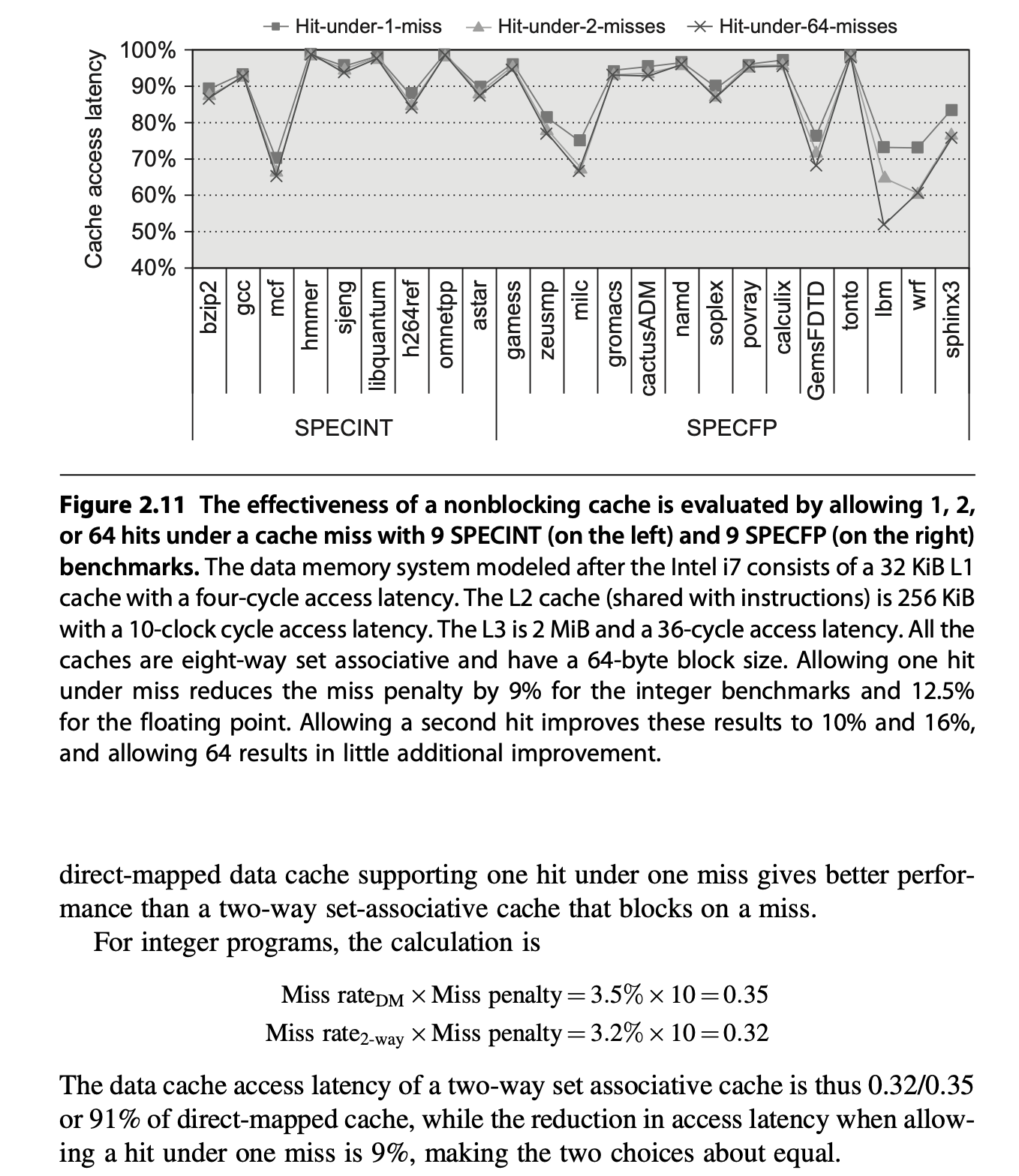
高速缓存失效不会使处理器停顿的特点加大了评估非阻塞高速缓存性能的难度。有效的失效损失不是所有失效损失之和,而时使得处理器停顿的非重叠的时间。非阻塞高速缓存带来的好处取决于多个失效带来的失效损失、内存引用模式以及在未完成的失效(outstanding misses) 发生时处理器执行的指令数。
乱序处理器能够隐藏在 L1 失效但在 L2 命中的失效损失,但是无法隐藏更低级的高速缓存失效。决定支持多少未完成的失效取决于以下因素:
- 失效流的时间和空间局部性,这决定了失效是否发起向下一级高速缓存或内存的访问
- 相应内存或高速缓存的带宽
- 为了允许最底层的高速缓存有更多的未完成的失效,要求最高层的高速缓存至少支持与最底层同样多的失效,因为失效是从最高层的高速缓存中发起的
- 存储器系统的时延
实现一个非阻塞高速缓存较为困难,原因有:
- 为命中和失效的竞争进行仲裁
- 解决方案:给予命中更高的优先级,然后为冲突的失效排序
- 追踪未完成的失效,以弄清何时让加载和存储操作继续
- 解决方案:使用失效状态处理寄存器(miss status handling register, MSHR) 来记录信息。一个 MSHR 对应一个未完成的失效,记录与这个失效相关的一些信息。
Critical Word First and Early Start⚓︎
- 关键字优先(critical word first):从内存中请求失效的字数据,一旦获取数据后便立即发送给处理器,并让处理器在填充数据块剩余字数据的同时继续执行指令。
- 早启动(early start):按正常顺序获取字数据,但一旦获取到所需的字数据,就将其发送给处理器并让处理器继续执行指令。
这两种优化方法仅在高速缓存数据块较大的情况下有明显的好处。它们带来的好处还取决于访问数据块中未获取的部分的可能性。
它们和非阻塞高速缓存一样,为计算失效损失带来了不小的麻烦。
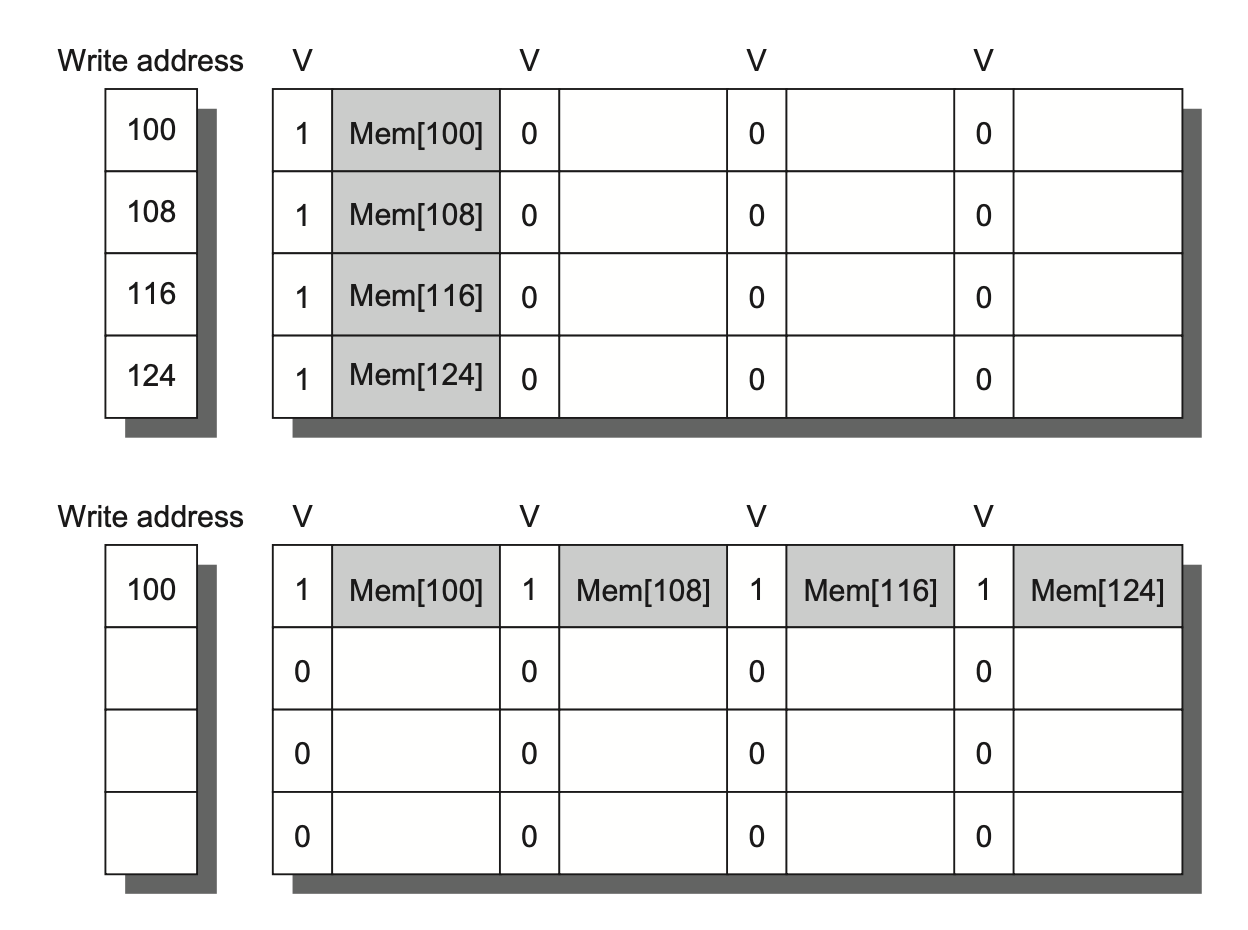
Merging Write Buffer⚓︎
- 写穿依赖于写缓冲区,即使是写回有时也会用到写缓冲区。
- 如果写缓冲区是空的,那么数据和完整的地址都会被写入到缓冲区中,并且从处理器的视角看写操作已完成,所以在写缓冲区准备将字数据写入内存时,处理器继续干活。
- 如果缓冲区包含一些被修改的数据块,那么就要检查一下地址,看这些新数据的地址是否与某个有效的写缓冲区项匹配,如果匹配的话,就将新数据并入到这个项里。这种优化方法称为写合并(write merging)。
- 但如果写缓冲区是满的,且没有任何地址匹配,那么高速缓存(和处理器)必须等待,直到写缓冲区有一个空的项。
- 这种优化方法能够更加高效地利用内存,因为一次写入多个字数据通常比一次写一个字数据的速度更快;并且也能减少停顿次数。
- 下图比较了未使用写合并的写缓冲区和使用写合并的写缓冲区:
Compiler Optimizations⚓︎
前面讲到的优化都是硬件层面的优化,我们当然也可以进行软件层面的优化。下面就来介绍如何通过优化编译器来减少失效率。
-
对于指令:
- 重排内存中的过程,以降低冲突失效
- 分析指令,以观察冲突是否发生
-
对于数据:
-
合并数组(merging arrays):用单个数组表示复合元素,以提升空间局部性
-
循环交换(loop interchange):有时通过交换内层循环和外层循环,使得访问数据的顺序更符合存储数据的顺序。这种方法通过改进空间局部性来减少失效率。
-
循环融合(loop fusion):合并两个具有相同循环,且部分变量重叠的独立循环。
-
分块(blocking):将大的数组划分一块块小块 (block),通过分别解决每个小块来解决整个数组。该方法同时利用了空间和时间的局部性。下面通过一个矩阵乘法的例子来认识该方法带来的好处:
例子
给定两个规模均为 NxN 的矩阵 y, z,计算 x = y * z。
代码如下:
for (i = 0; i < N; i++) for (j = 0; j < N; j++) { r = 0; for (k = 0; k < N; k++) r = r + y[i][k] * z[k][j]; x[i][j] = r; }在最坏情况下,\(N^3\) 次运算需要访问 \(2N^3 + N^2\) 个内存字数据。
下图展示了某个时间段内矩阵的运算情况,其中深灰色表示最近访问的元素,浅灰色表示之前访问的元素,白色表示尚未访问的元素。
如果高速缓存空间有限,这样做显然是不行的。所以在计算前,需要将矩阵划分为 BxB 大小(B 称为分块因子(blocking factor))的子矩阵,逐个计算子矩阵乘法的结果。此时所需的内存字数据个数为 \(2N^3 / B + N^2\),节省了高速缓存的空间,从而减少容量失效的发生。代码为:
for (jj = 0; jj < N; jj += B) for (kk = 0; kk < N; kk += B) for (i = 0; i < N; i++) for (j = jj; j < min(jj + B, N); j++) { r = 0; for (k = kk; k < min(kk + B, N); k++) r = r + y[i][k] * z[k][j]; x[i][j] += r; }下图展示了某个时间段内矩阵的运算情况:
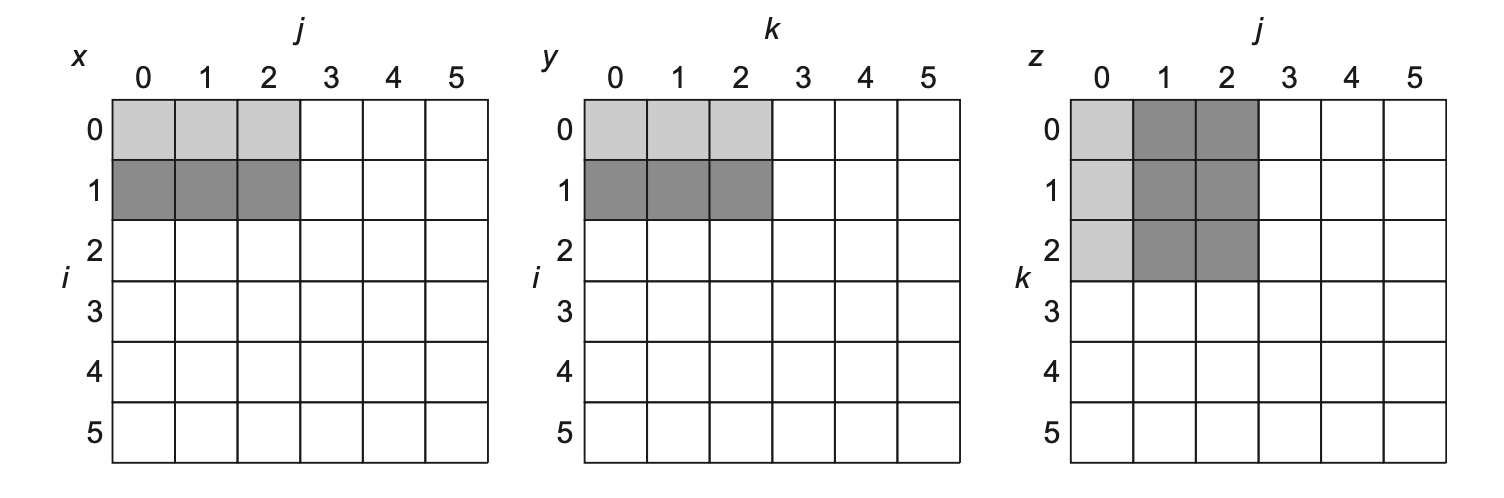



答案由 Gemini 2.5 pro 生成,且经过笔者验证。

-
Hardware Prefetching of Instructions and Data⚓︎
硬件预取(hardware prefetching) 的核心思想为:
- 利用到非阻塞缓存,允许在执行过程中存在重叠的内存访问
- 在处理器请求数据之前,提前将指令和数据预取到缓存或外部缓冲区中
我们可以将预取分为:
- 指令预取:
- 通常由硬件在高速缓存外部完成
- 当发生指令失效时,处理器不仅会请求当前缺失的指令块,还会预取下一个连续的指令块
- 这些预取到的块会被放置在指令流缓冲区(stream buffer) 中
- 如果请求的块已经在流缓冲区中,则取消原始缓存请求,并发出下一个预取请求
- 数据预取:上述方法也适用于数据访问。
但使用预取时要考虑以下问题:
- 带宽利用:预取依赖于利用原本可能未被使用的内存带宽;如果预取与实际需求访问竞争带宽,反而可能降低性能
- 无用预取:如果预取的数据最终没有被使用,则会浪费内存带宽和缓存空间
- 缓存污染:无用的预取数据可能会驱逐掉缓存中真正有用的数据,从而增加失效率
- 功耗:预取操作会消耗额外的功耗,如果预取效率不高,这种功耗就是浪费
- 编译器协助:编译器可以通过提供预取提示来帮助减少无用预取(下面马上介绍👇)
Compiler-Controlled Prefetching⚓︎
硬件预取的替代方案是使用编译器(compiler),在处理器获取数据前,插入请求数据的预取指令。具体有以下两类方式:
- 寄存器预取(register prefetch):将值加载到一个寄存器里。
- 高速缓存预取(cache prefetch):将数据仅加载到高速缓存中。
这两类方式都有发生错误的可能,也就是说地址可能引发,也可能不会引发虚拟地址错误和违反保护的异常。按照这种术语体系,常规加载指令可被视为 " 错误触发型寄存器预取指令 "。而非错误触发的预取指令若在正常情况下会导致异常时,则会自动转为空操作 (no-ops)——这正是我们期望的行为。
最有效的预取是对程序“语义上不可见的”(semantically invisible):预取不改变寄存器和内存的内容,并且它不会导致虚拟地址的错误。现在大多数处理器都提供了非错误触发的高速缓存预取,因此本节就专注于这类预取(又称为非绑定预取(nonbinding prefetch)
类似硬件预取,这类预取的目标是对预取而来的数据重叠执行。循环是很重要的,因为我们可用它来做预取优化。如果失效损失较小,编译器仅需展开 1-2 次循环,并在执行过程中调度预取;如果失效损失较大,它会用到软件流水线,或展开多次循环,以在未来迭代中预取数据。
发射预取指令会带来额外的指令开销,所以编译器必须小心,确保这样的开销不会盖过其带来的好处。
例子





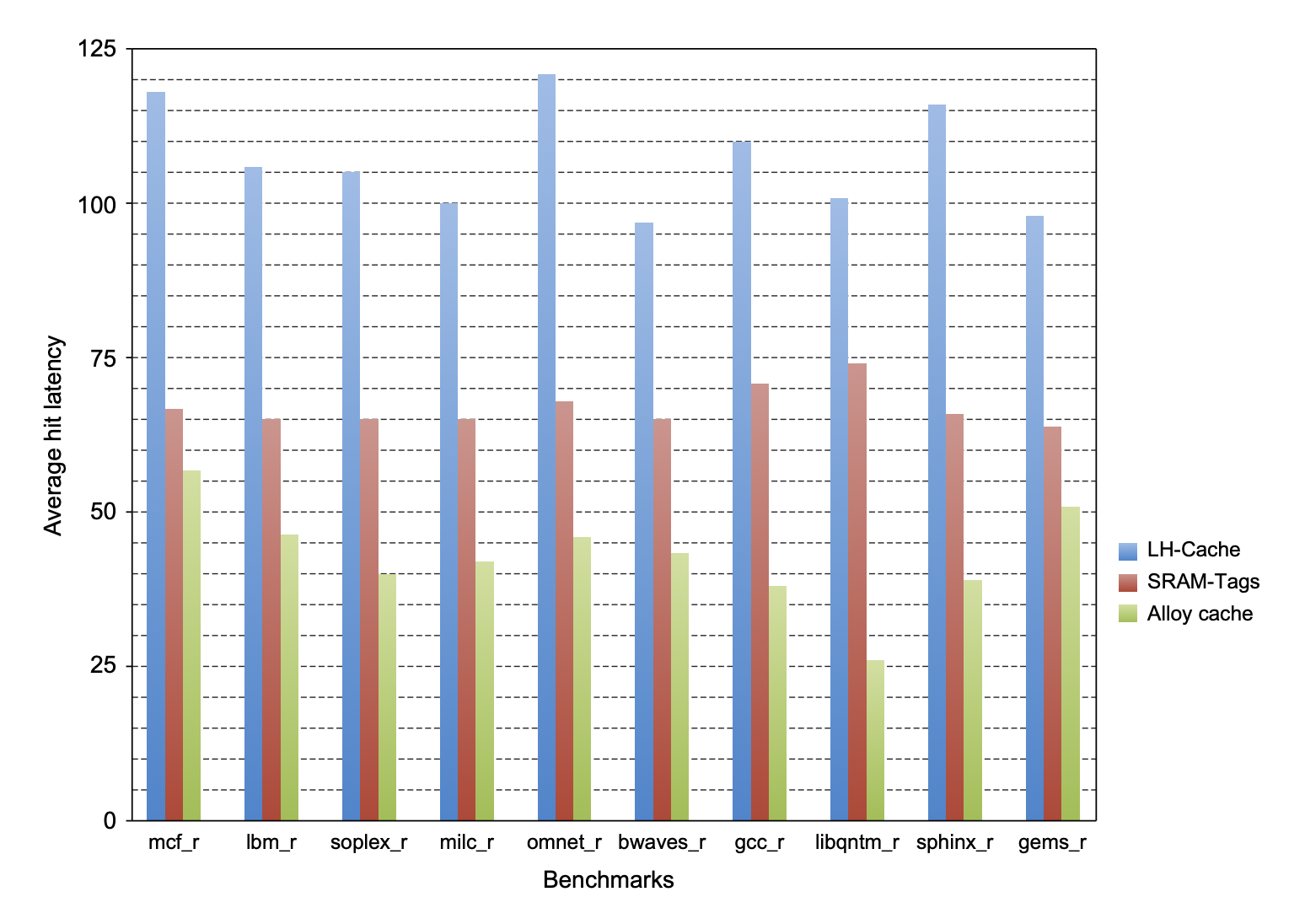
Using HBM to Extend the Memory Hierarchy⚓︎
HBM(high bandwidth memory):高带宽内存。
当使用 HBM 作为大容量 L4 缓存时,
- 若采用小块大小(如 64B
) ,那么标签所需的静态内存量巨大(96 MiB) ,远超 CPU 上的 L3 缓存大小 - 但若采用大块大小(如 4KiB
) ,则会产生以下问题:- 碎片化问题(fragmentation problem):缓存块内容未被完全利用,导致效率低下
- 传输效率低下:传输大块数据时,如果大部分数据未被使用,会造成浪费
- 冲突和一致性缺失增加:缓存中可容纳的不同块数量减少,导致更多缓存未命中
此外,传统的标签为存储方案具备一定的延迟,因为标签被存储在 L4 缓存中,需要两次 DRAM 访问(一次取标签,一次取数据
为了解决上述问题,这里提供了以下方案:
- Loh and Hill (L-H) 方案:
- 将标签和数据存储在 HBM SDRAM 的同一行中
- 打开行虽然耗时,但访问同一行中不同部分(如先标签后数据)的延迟显著降低(约新行访问时间的 1/3)
- L4 缓存被组织为 29 路组相联,每行包含一组标签和 29 个数据段
- Qureshi and Loh(合金缓存(alloy cache))方案:
- 在 L-H 方案基础上改进,将标签和数据融合在一起
- 采用直接映射的缓存结构
- 将 L4 访问时间缩短到单个 HBM 周期(通过直接索引和突发传输)
- 权衡:显著降低了命中时间(比 L-H 方案快 2 倍
) ,但会略微增加失效率(1.1-1.2 倍)
下图展示了这些方案和以及原方案的命中时延:
另外针对未命中延迟问题,我们有以下解决方案:
- 使用映射来跟踪缓存中块的存在性
- 使用内存访问预测器(基于历史预测技术)来预测可能的失效
- 小型预测器可以高精度预测失效,从而降低失效损失
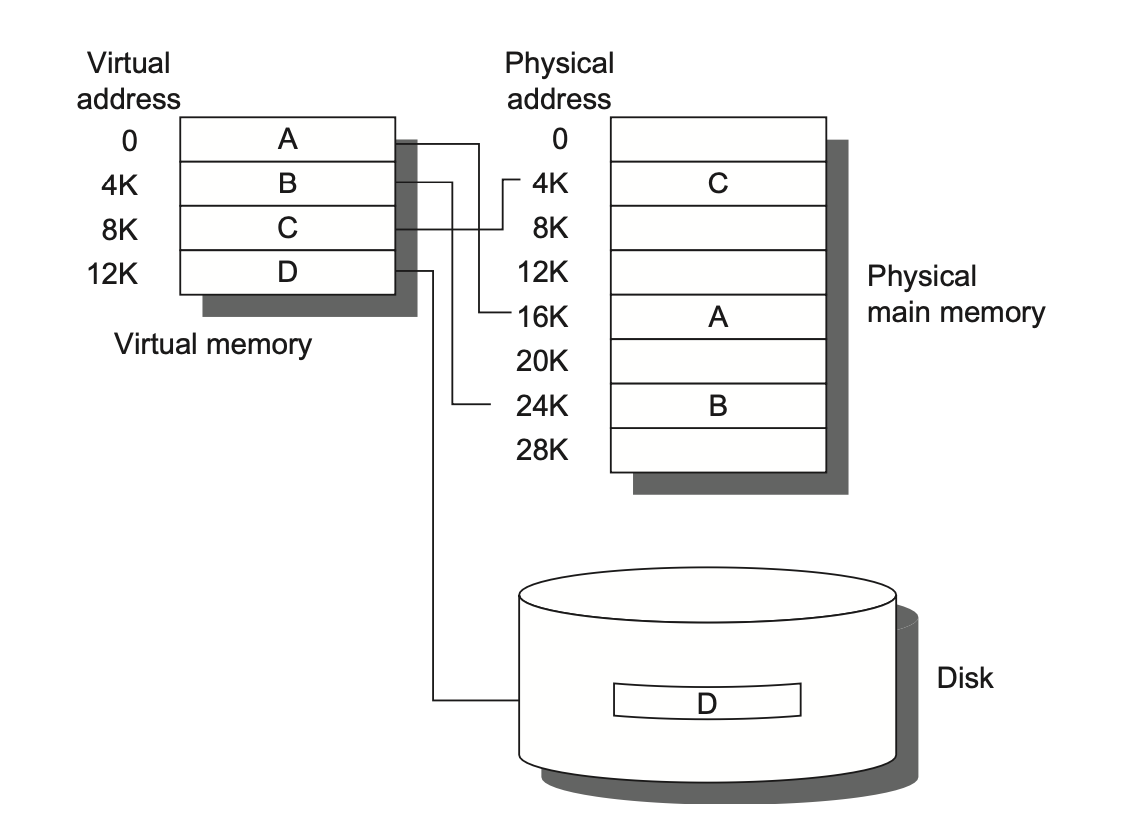
Virtual Memory⚓︎
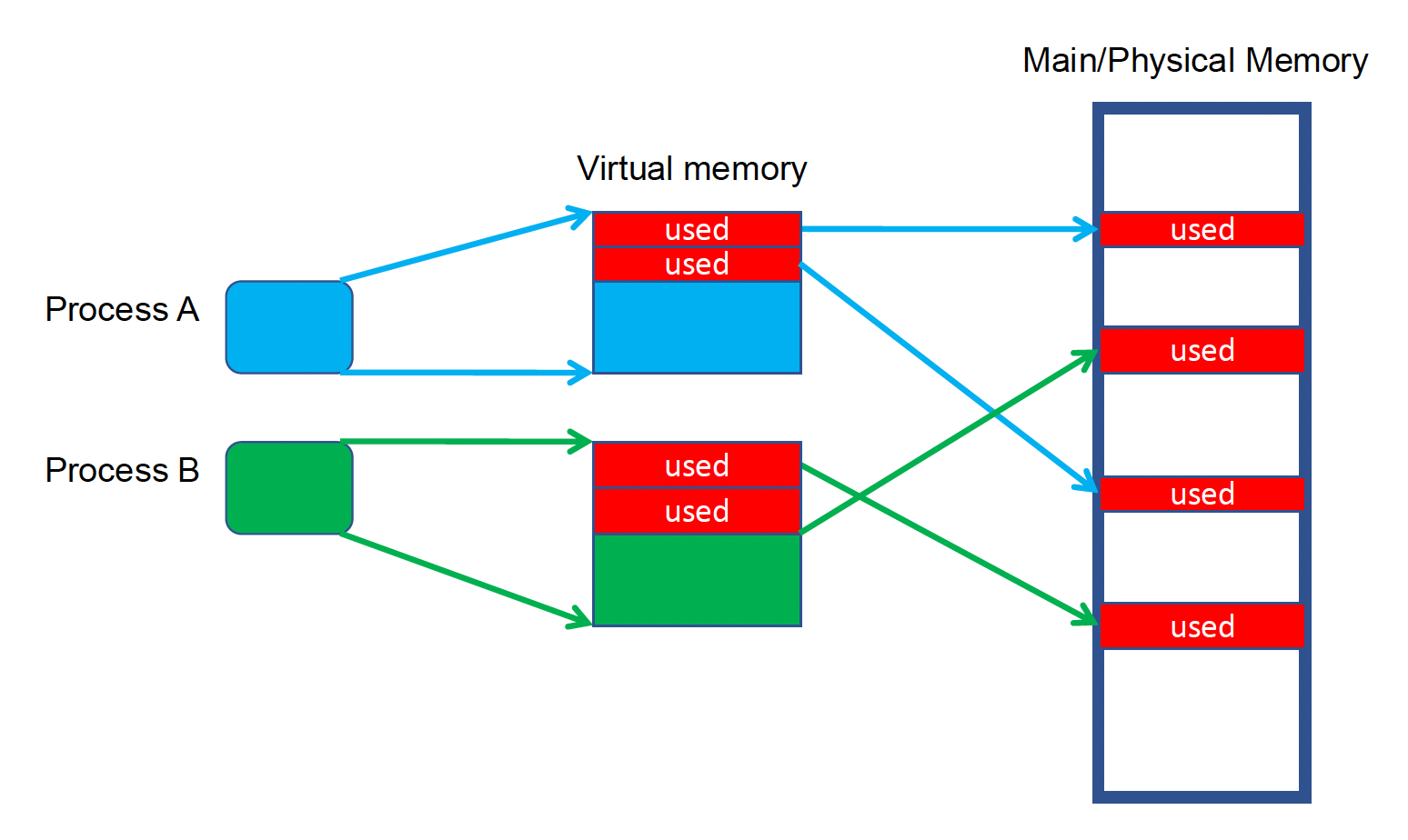
虚拟内存(virtual memory) 将物理内存划分为块,并且将其分配到不同的进程中。下图展示了虚拟地址到物理地址的映射情况:
虚拟内存的作用包括:
- 共享受保护的内存空间
- 虚拟内存采取一种保护机制,防止属于某个进程的内存块被其他进程访问
-
自动管理存储器层级
-
不必分配连续的物理内存
-
-
简化执行程序的加载:通过重定位(relocation),允许相同的程序可以在物理内存中的任意位置运行
- 减少开始程序的时间:因为无需物理内存中所有的代码和数据
下面是虚拟内存中常见的一些概念,包括:
-
页(page)/段(segment)(类比高速缓存的数据块)
- 页:定长的虚拟内存数据块,一般是 4KB 到 8KB 左右
- 按页寻址:定长的地址被划分为页编号和页偏移量
- 对编译器而言,这种地址空间更简单
- 段:变长的虚拟内存数据块,最大可以到 64KB 到 4GB 左右,最小可以只有 1B
- 按段寻址:使用 1 个字来表示段编号,另 1 个字表示段偏移量
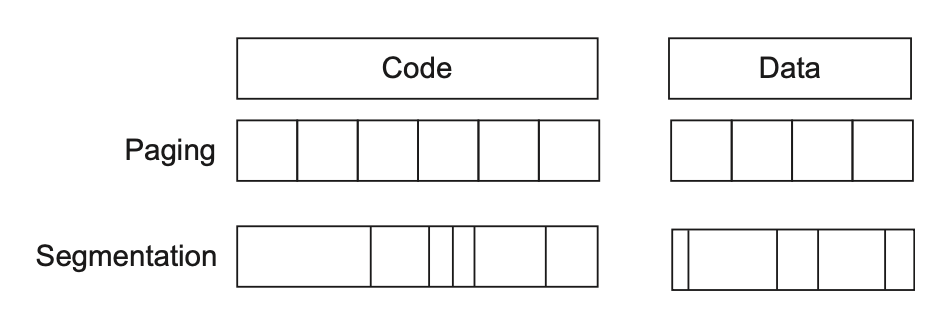
下图比较分页和分段两种方式的优劣:
- 页:定长的虚拟内存数据块,一般是 4KB 到 8KB 左右
-
页错误(page fault)/地址错误(address fault)(类比高速缓存的失效)
- 虚拟地址(virtual address) 和物理地址(physical address)
- 内存映射(memory mapping)/地址转换(address translation)
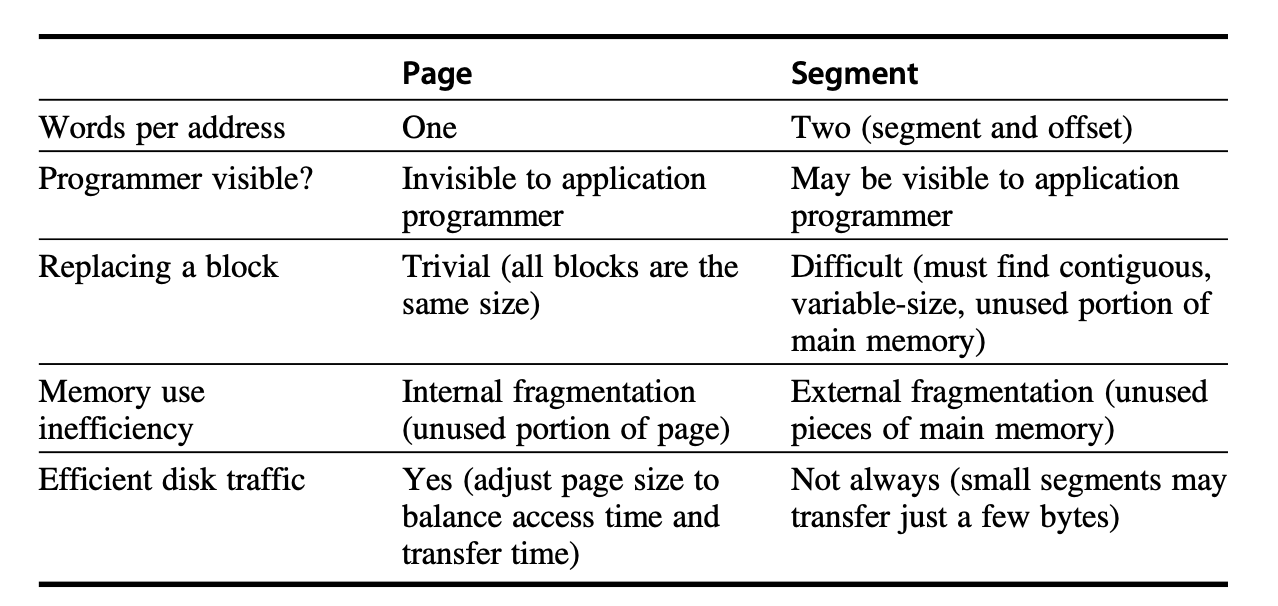
高速缓存与虚拟内存的不同之处有:
- 高速缓存失效的替换是由硬件控制的,而虚拟内存的替换是由操作系统控制的
- 处理器地址的大小决定了虚拟内存的大小,而高速缓存的大小与处理器地址的大小无关
Four Memory Hierarchy Questions Revisited⚓︎
-
数据块放置:全相联
- 理由:虚拟内存的失效损失相当相当大(数百万个时钟周期数
) ,因此需要尽可能地降低失效率,而全相联的失效率最低。
- 理由:虚拟内存的失效损失相当相当大(数百万个时钟周期数
-
数据块识别:通过页 / 段编号来索引对应的页 / 段
-
通常使用页表(page table) 这一数据结构来存储虚拟内存数据块的物理地址(段的话还要存储偏移量
) ,作为虚拟地址转换为物理地址的参照依据。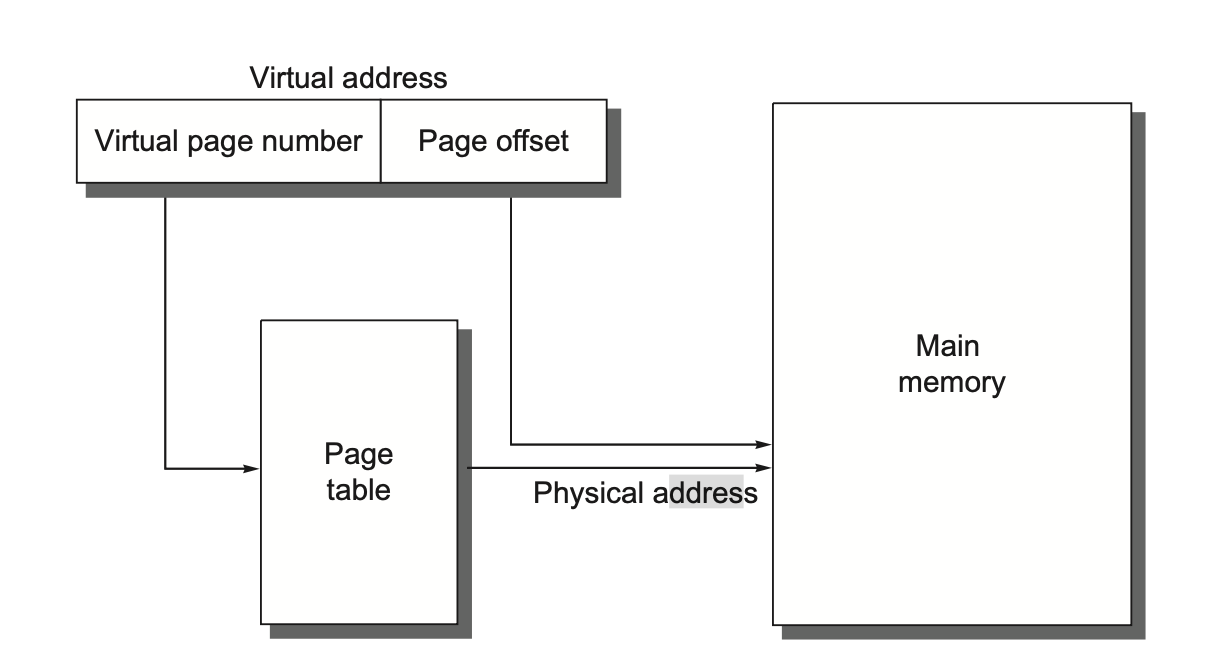
-
页表的大小就是虚拟地址空间中的页数量。有些计算机为了减小这一数据结构大小,会对虚拟地址采用哈希函数,使得其大小等于内存中物理页的数量,这种数据结构称为逆页表(inversed page table)。
- 为了减少地址转换的时间,通常还会用到一种名为转换后备缓冲区 (translation lookaside buffer, 以下简称 TLB) 的部件
-
-
数据块替换:LRU,具体会用到一个使用位 / 引用位 (use/reference bit)。操作系统会周期性地清除使用位,随后又添上去,这样便可以记录一段时间内页的访问情况。
-
写入策略:写回
- 理由:内存和处理器访问时间的巨大差异,所以不可能使用写穿策略
- 虚拟内存系统用到 1 个脏位(dirty bit),允许数据块在因从硬盘读取而被改变的时候写入到硬盘中
Techniques for Fast Address Translation⚓︎
由于页表很大,所以一般被存在内存中,甚至有时候页表自己也要分页。而分页意味着逻辑上内存访问需要分两步走:首先需要找到物理地址,然后再根据物理地址找到数据。为了避免额外的内存访问,我们可以借助局部性原则,将部分地址的翻译保留到一个特殊的缓存中,这样的缓存就是我们熟知的 TLB。
TLB 的结构类似高速缓存:它的标签位用于保存虚拟地址;而数据位用于保存物理页编号,保护字段,合法位,以及可能的使用位和脏位。
- 如果要改变页表中的物理页编号和保护信息,那么操作系统必须将 TLB 中的对应部分给清掉。
- 这里的“脏位”表示对应的页是不是“脏”的,而不是表示 TLB 中的地址翻译或数据缓存的特定的数据块是不是脏的。
- 操作系统通过改变页表中的值,以及使 TLB 中对应的项无效化来实现对这些位的重置
下图展示了在地址转换中,TLB 内发生的操作:
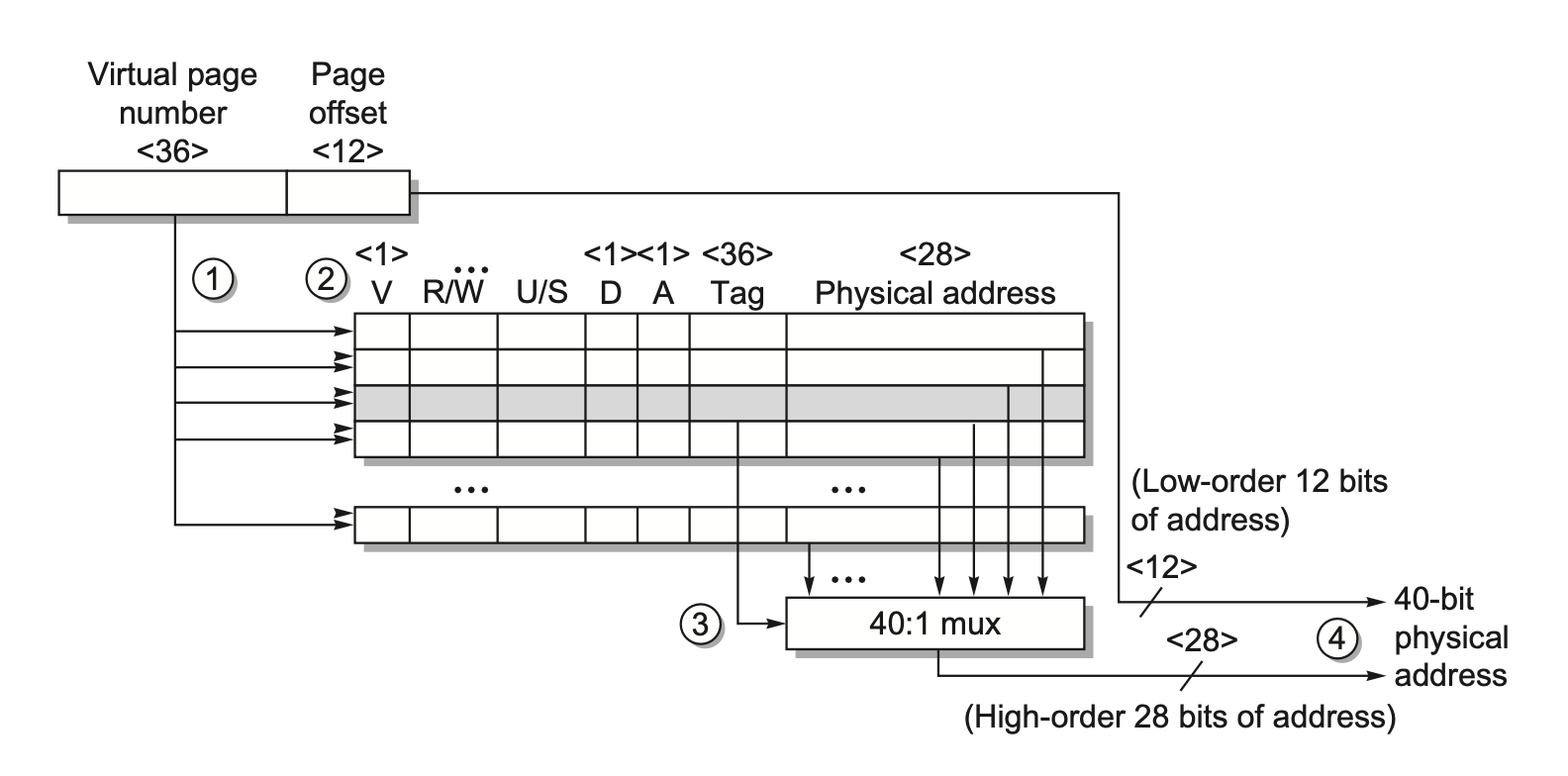
- 将虚拟地址发送至所有标签
- 检查内存访问类型,与 TLB 中的保护信息进行比对
- 匹配到的标签将物理地址发给 MUX
- 拼接页偏移量和物理页帧,组成最终的物理地址
Page Size⚓︎
在以下情况,我们倾向于使用更大的页:
- 由于页表的大小和页的大小成反比,因此内存(或其他存储页表的资源)可以通过增大页的大小来节省空间
- 更大的页可以使用更大的高速缓存,以达到更快的命中时间
- 在二级存储器,或者在网络中传输更大的页,相比传输更小的页更有效
- 更大的页意味着更多的内存能被有效映射,因此减少了 TLB 失效的情况
而当需要保留存储空间,或者希望启动进程的速度更快时,我们更倾向于使用更小的页。
我们也可以做到“鱼和熊掌兼得”——采用多种页大小。最新的处理器开始支持多种页大小的选择,主要因为更大的页大小减少 TLB 内的项数,从而减少 TLB 失效的次数(对于某些程序,TLB 失效对 CPI 的影响和高速缓存失效差不多大
Protection⚓︎
- 多程序(multiprogramming):并发运行的程序共享一台计算机资源
- 进程(process):包括正在运行的程序,以及该程序运行的状态
- 时间共享(time-sharing):多程序的一种变体,同时为多个可交互的用户分享处理器和存储器资源,当作这些用户有自己的计算机
- 进程 / 上下文切换(process/context switch):任何时候从一个进程切换到另一个进程的行为
- 由于进程可能会被多次中断或切换,因此计算机(硬件)以及操作系统的设计者需要为维护正确的进程行为负责,具体来说:
- 计算机设计者确保进程状态中处理器的那部分能够被保存和恢复
- 操作系统设计者保证进程之间不会相互干扰——通过划分内存来确保不同的进程在同一时间内有自己的状态
- 每个进程都有自己的页表,指向不同的内存页,以保护进程
- 环级权限(ring):处理器的一种保护机制,分为用户、核 (kernel),以及可能更多的特权等级
- 除了保护机制外,计算机还需提供进程间的共享代码和数据,以允许进程间的通信或通过减少相同信息的拷贝来节省内存空间
The Design of Memory Hierarchies⚓︎
Protection, Virtualization and Instruction Set Architecture⚓︎
虚拟内存和虚拟化技术对处理器架构和操作系统提出了新的要求,需要对指令集架构进行调整以支持这些功能。例如,IBM 360 和 80x86 架构都曾因虚拟化而进行修改,以解决特权指令(如 POPF)在用户模式下运行时的行为问题。
为了提高虚拟化性能,IBM 硬件和 VMM(虚拟机管理器)曾做过以下努力:
- 降低处理器虚拟化成本
- 减少中断开销
- 降低调用 VMM 的中断成本。
为了实现这些目标,现代芯片组增加了对应的特殊指令。
Autonomous Instruction Fetch Units⚓︎
现代乱序执行和深流水线处理器通常使用独立的指令获取单元。这些单元能够获取整个指令块,并预取到 L1 缓存中,从而减少指令缓存失效损失。虽然这样做反而可能增加可数据缓存的失效率(因为预取了不立即需要的数据
Speculation and Memory Access⚓︎
这里涉及到指令级并行 (ILP)
推测(speculation) 是高级流水线中的一项重要技术,它基于分支预测,在处理器确定指令是否真正需要执行之前就进行尝试性执行。如果推测错误,流水线中的推测指令会被清除,并可能产生不必要的内存引用,从而增加缓存失效率。然而,结合预取技术,推测实际上可以降低总体的缓存失效损失。因此,在比较失效率时,需要注意推测执行可能带来的误导性影响。
Special Instruction Caches⚓︎
这里涉及到数据级并行 (DLP)
为了满足超标量处理器(superscalar processor) 对高指令带宽的需求,可以采用小型缓存来存储最近翻译的微操作(micro-operations),有助于减少分支预测错误带来的惩罚。
Coherency of Cached Data⚓︎
这里涉及到线程级并行 (TLP)
在存储器层次结构中,当存在多份数据副本时,我们需要确保这些数据的一致性(coherency)。
- 在单处理器系统中,只要处理器是唯一的数据使用者,一致性问题较小。
- 但在多处理器系统中,由于多个处理器可能拥有同一数据的副本,数据一致性成为一个主要挑战,可能导致处理器读取到陈旧数据。
I/O 缓存一致性(I/O cache coherency) 是一个特殊且重要的问题:当 I/O 设备与缓存数据交互时,需要确保 I/O 操作的数据与缓存中的数据保持一致,否则可能导致处理器看到陈旧(stale) 数据或因等待 I/O 而停顿。
要解决这些问题,可以采取使缓存条目失效,或刷新缓冲区等措施。
Fallacies and Pitfalls⚓︎
陷阱
- 地址空间过小
- 地址的大小限制了程序的长度,因为程序的大小和程序所需数据的量必须不超过 \(2^{\text{Address size}}\)
- 反例:PDP-11 的地址大小只有 16 位,而之后出产的 IBM 360 和 VAX 的地址大小分别为 24-31 位和 32 位,结果就是后面两台电脑明显比前者卖的更好
- 忽视操作系统对存储器层级性能的影响
- 大约 25% 的存储器停顿时间都是来自操作系统的干扰
- 依赖操作系统来改变页的大小
评论区