Chap 3: Instruction-Level Parallelism⚓︎
约 20343 个字 94 行代码 预计阅读时间 103 分钟
核心知识
先回顾各类依赖 / 冒险
从硬件和软件(编译器)两个角度来充分利用 ILP(加粗部分表示定量要求,最好根据例题推导一遍
- 硬件
- 动态调度
- 记分板
- 托马苏洛算法
- 寄存器重命名
- 推测(speculation)
- 多发射
- 静态调度超标量处理器
- VLIW
- 动态调度超标量处理器
- 动态调度
- 软件
- 循环展开
- 分支预测
- 1 位 /2 位静态预测(见计组笔记)
- 相关预测器
- 锦标赛预测器
- 分支 - 目标缓冲区
- 集成指令获取单元
- ...
Introduction⚓︎
本章我们来学习第一种并行技术:指令级并行(intruction-level parallelism, ILP),它允许指令能够被并行计算。我们在计组中学过的流水线就是其中一种指令级并行技术。
有两类利用指令集并行的方法,在本章笔记中会对它们进行详细介绍:
- 基于硬件的动态并行
- 基于软件(编译器)的静态(编译时)并行
大多数处理器采用的都是基于硬件的方法,并且该方法主宰了台式机和服务器的市场。虽然有人在基于编译器的方法上做了不少努力,但这种方法目前还是仅限于领域特定的环境或者结构良好的且具备较大程度的数据级并行的科学应用中。
尽管 ILP 对处理器性能带来不少提升,但它受到程序和处理器自身的局限。因此后来人们开始在多核处理器,即线程级并行(thread-level parallelism) 上做出努力。
流水线 CPU 的 CPI 计算公式为:Pipeline CPI = Ideal pipeline CPI + Structural stalls + Data hazard stalls + Control stalls。其中等号右侧第一项理想流水线 CPI是对实现中最大性能的衡量。通过降低等号右侧的每一项,我们能够降低总的流水线 CPI。下表展示了所有能够影响到流水线 CPI 的工艺:
在学习 ILP 时,我们会遇到一个概念:基本块(basic block),它是一段小规模的代码序列,既满足没有分支进入到它这里(除非它是入口
其中最简单也最常用的方法是采用迭代循环——这类并行也被称为循环级并行(loop-level parallelism)。举个例子:下面给出两个有 1000 个元素的数组相加的例子:
不难发现,虽然每个迭代的内部没有什么重叠好言,但是对于任意两个迭代而言,它们之间毫不相干,因此可以重叠在一起执行。之后,我们会介绍通过编译器或硬件来展开循环,实现循环的并行执行(当然也可以用下一章介绍的数据级并行来实现
Dependences in Instructions⚓︎
如果两条指令是并行的话,意味着它们能够在同一个流水线中同时执行,且不会造成任何停顿(假设流水线有足够多的资源,不会造成结构冒险问题
注:单条指令间的依赖关系(比如
add x1, x1, x1)不视为存在依赖。
Data Dependences⚓︎
如果满足下列条件,那我们称指令 j 数据依赖于指令 i:
- 指令 i 的执行结果会被指令 j 用到
- 指令 j 数据依赖于指令 k,而指令 k 数据依赖于指令 i
第二个条件告诉我们:多条指令间可能存在一条依赖链,甚至这条链可以遍布于整个程序中。
例子
考虑以下 RISC-V 代码序列:
这段代码中的数据依赖包括:2-3 行的 f0、3-4 行的 f4 和 5-6 行的 x1。
如果两条指令间存在数据依赖关系,则必须保留这两条指令的执行顺序,不得让它们同时执行。并且数据依赖关系表明指令间存在单个或多个数据冒险的问题,所以硬要同时执行这样的指令的话就会带来不小的麻烦。
我们需要辨别以下区别,这有助于我们理解如何利用好 ILP:
- 依赖是程序的一种性质;
- 而对应的流水线组织的一条性质是:对于给定的依赖,是否会导致能够被检测出来的真正的冒险,并且该冒险是否会导致停顿。
一个数据依赖传达了 3 件事,这也正是数据依赖为 ILP 带来的限制:
- 冒险发生的概率
- 结果必须被计算出来的顺序
- 能够被利用到的并行的上限
当然,我们肯定希望能够克服上述限制——我们可以通过以下两种不同的方法来克服:
- 保持依赖,但避免冒险发生
- 常见做法是对代码进行合适的调度(scheduling),可通过编译器或硬件实现
- 通过改变代码来消除依赖
数据流可以流过寄存器,也可以流过内存。对于前者,检测依赖比较直接,因为寄存器的名称是固定的(尽管有时会更复杂
Name Dependences⚓︎
当两条指令使用相同的寄存器或内存位置(称为名称(name)
- 反依赖(antidependence):指令 j 向指令 i 读取的寄存器或内存位置上进行写操作
- 输出依赖(output dependence):当指令 i 和 j 向同一个寄存器或内存位置上进行写操作
正如定义所言,由于具有名称依赖的两条指令之间不存在数据流,所以这种依赖不是真正的依赖,也就是说这样的指令可以并行执行或重新排序,只要改变这些指令使用的名称(寄存器或内存位置
对于寄存器而言,这种重命名操作更加容易(称为寄存器重命名(register renaming)
Data Hazards⚓︎
回顾一下冒险(hazard) 的概念:当指令间存在名称或数据依赖时,如果这样的指令足够接近,能够被重叠执行的话,那么就可能会改变访问和依赖相关的操作数的顺序,此时冒险就发生了。为了避免冒险的发生,在并行时必须保留那些会影响到程序执行结果的程序顺序(program order),即按源程序顺序来执行指令的顺序。
对于数据冒险(data hazard),我们根据指令的读写访问顺序,将其划分为以下几类(还是假设指令 j 的程序顺序在指令 i 的后面
-
RAW(read after write):j 尝试在 i 写入某个源操作数之前读取它,这样 j 就会得到旧的数据。这是最常见的一类冒险,且对应真正的数据依赖(即真依赖(true dependence)
) 。比如: -
WAW(write after write):j 尝试在 i 写入某个操作数之前向它写入,这样导致写操作的执行顺序错误,该操作数的最终结果是 i 写入的结果而非 j。该冒险对应输出依赖,且仅存在于允许在多个阶段写入数据的流水线,或者允许指令在前一条指令停顿时继续执行的情况下。比如:
-
WAR(write after read):j 尝试在 i 读取某个目的操作数之前先向它写入,这样 i 就会错误地得到了新的数据。该冒险对应反依赖,在大多数静态发射的流水线中不会发生。比如:
注:RAR 不会导致冒险出现,故不在讨论范围内。
数据冒险的解决方案参见计组笔记。
Control Dependences⚓︎
控制依赖(control dependence) 决定了指令 i 关于分支指令的顺序。除了程序的第一个基本块外,所有指令都和某些分支之间存在控制依赖,并且这些控制依赖必须被保留下来,以保留程序顺序。考虑以下代码块:
不难发现:S1 控制依赖于 p1,S2 控制依赖于 p2 而非 p1。
控制依赖带来以下约束:
- 关于某个分支控制依赖的指令不得被移动到分支之前,否则的话该指令就不被该分支所控制
- 不受某个分支控制依赖的指令不得被移动到分支之后,否则的话该指令就要被该分支所控制
事实上,我们不需要严格保留控制依赖,而只需要保留两个关键的性质:异常行为(exception behaviour) 和数据流(data flow)。
- 保留异常行为意味着任何对指令执行顺序作出的改动,不能改变程序如何产生异常的。
- 更松弛的版本是:对指令执行的重新排序不得导致程序中出现新的异常。
- 之后介绍的推测(speculation) 技术能够让我们忽视选取分支带来的异常,从而允许我们在保留数据依赖的情况下对指令进行重排。
- 数据流是指令间产生结果或接受输入中的数据值的真实流动。分支让数据流变得动态,因为它们让数据源可以来自很多地方。通过保留控制依赖,就能够阻止对数据流的非法变化。
- 之后介绍的推测还能用于这种情况:在减小控制依赖的影响时,还能维护数据流。
有时,违反了控制依赖不会影响到异常行为或数据流。
控制依赖可通过实现控制冒险检测(导致控制停顿的发生)来被保留。我们可通过一系列的硬件或让软件工艺来消除或减小控制停顿的发生次数。
控制冒险(依赖)的解决方案参见计组笔记。
Basic Compiler Techniques: Loop Unrolling and Scheduling⚓︎
现在介绍一种能够增强处理器 ILP 能力的简单的编译器技术,但对处理器的静态发射或静态调度而言是很关键的。
为了让流水线完全处在工作状态,我们需要找出那些不相关的,可以被重叠执行的指令。为了避免流水线停顿,执行某条依赖指令时必须将其和它依赖的指令拉开几个时钟周期(等于被依赖指令的流水线时延)的差距。编译器实现这些调度的能力取决于程序中可用的 ILP 量,以及流水线中功能单元的时延。
一些约定
我们假设:
- 采用标准的五级流水线
- 功能单元完全被完全流水线化或被复制,这样能确保每个时钟周期下任何类型的操作都能被发射,且没有结构冲突发生
本节我们会介绍编译器是如何通过转变循环来增加可用 ILP 的量——来看下面的例子:
例子
对于以下 C 代码:
将其转化为 RISC-V 代码,且没有做过任何调度的结果如下所示:
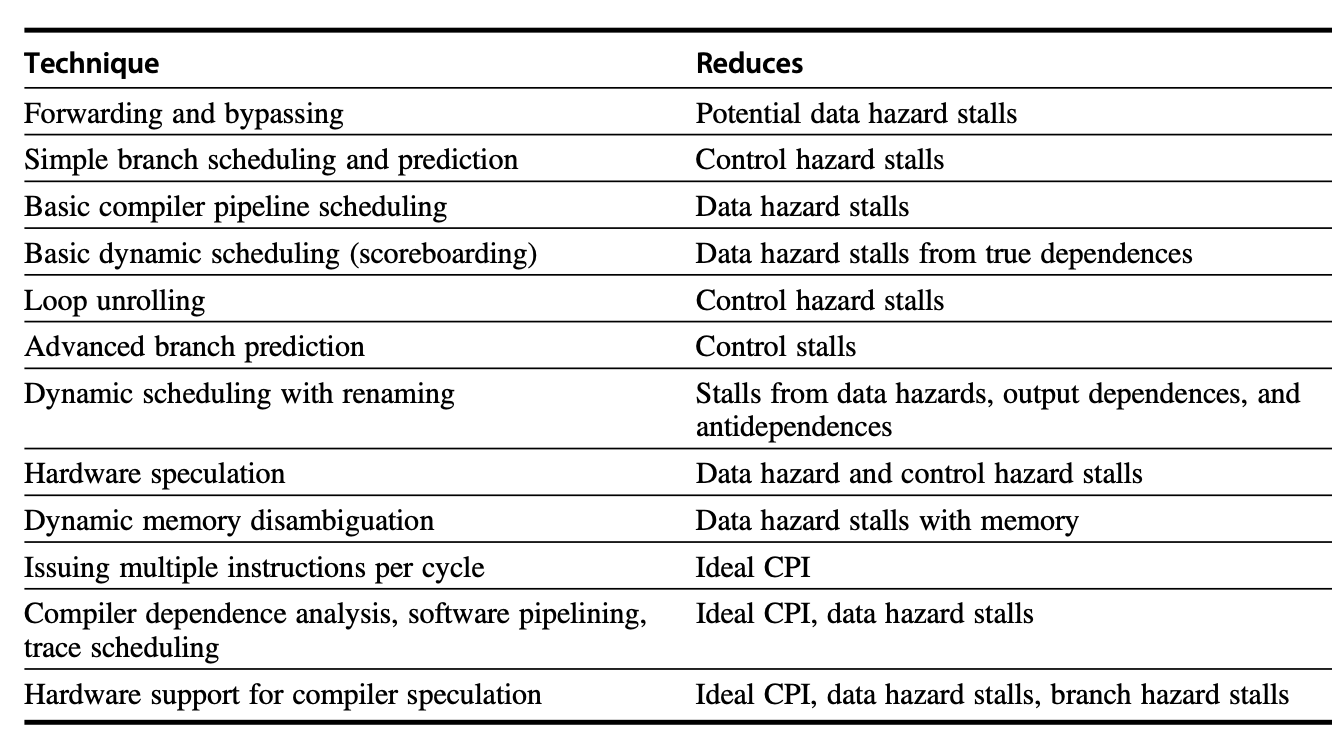
如果没有调度的话,执行一趟循环需要停顿 8 个时钟周期:

但如果进行调度后,就可以消除一个停顿:

这里我们将 addi 指令移到了 fld 的下一条指令的位置上。
对于上述例子,事实上真正对数组操作的指令只有三条(fld、fadd.dfsdaddi 和 bne 指令,我们希望能够消除掉,为此这里引入一种名为循环展开(loop unrolling) 的方法:
- 具体来说就是拷贝多份循环体,并调整循环终止相关的代码。
- 此外,该方法还能提升调度,因为它消除了分支,所以能允许不同迭代下的指令被一起调度。
- 此时,为了消除数据使用停顿的问题,我们通过在循环体内创建额外的独立指令,这时可能还需要用到更多不同的寄存器。
- 该方法在每次循环的迭代都是相互独立,即没有依赖关系的情况下最有效,此时现代处理器(超标量、乱序执行)就可以并行执行这些独立的操作,从而最大化 ILP。
例子
接着上面的例子,使用循环展开,拷贝 4 份循环体。这里假设 x1 - x2 的值是 32 的倍数,这也意味着迭代次数为 4 的倍数。在确保不重用任何寄存器的情况下消除冗余的计算。
在展开的时候,我们合并了 addi 指令,并删掉了不必要的重复的 bne 指令。结果如下所示:

如果没有调度的话,上述改变不会对性能带来多少提升(每趟循环 6.5 个时钟周期,其中 fld 和 fadd.d 之间要停顿 1 个时钟周期,而 fadd.d 和 fsd 之间要停顿 2 个时钟周期)
但是再加上调度的话,就能够显著提升性能了(每趟循环 3.5 个时钟周期

循环展开通常在编译前就完成了,这样的话冗余的计算就能被优化器发现并消除了。
在真实的程序中,我们往往不清楚循环的上界。假设上界为 n,并且我们想在循环展开时拷贝 k 份循环体。循环展开会生成一对连续的循环:第一个循环执行 (n mod k) 次,其循环体就是原始循环;第二个循环是被外层循环(需迭代 (n / k) 次)包裹的展开的循环体。对于更大的 n,大多数的执行时间花在了展开的循环体内。
循环展开通过消除指令开销,发现更多可通过调度来减少停顿的计算来提升性能,但代价是显著增加了代码规模。
在得到最终展开的代码前,我们必须做出以下判断和转换:
- 通过找到独立的循环迭代来确定循环展开是否有用
- 使用不同的寄存器,以避免因相同寄存器执行不同计算而带来的不必要的限制
- 消除额外的检验和分支指令,并校正循环终止和迭代的代码
- 通过观察不同迭代下的加载和存储是否独立,来确定展开循环中的加载和存储能否可以互换。这一转换需要分析内存地址,并确定它们不是指向相同的地址
- 通过调度代码来保留依赖,确保产生的结果和原代码一致
循环展开的限制有:
- 每次展开摊还的开销量下降
- 代码规模限制
- 更大的代码规模可能会带来更大的高速缓存失效率
- 寄存器压力(register pressure):用来存放“活值”的寄存器变得更多,导致可用寄存器变少,尤其为多发射处理器带来困难
- 编译器限制
Advanced Branch Prediction⚓︎
因为分支可能会损害流水线的性能,所以需要采取一些措施以降低其负面影响。前面讲到的循环展开是一种方法,另一种方法是分支预测(branch prediction)。之前我们在计组笔记 Chap 4 中介绍过简单的分支预测器 (predictors) 技术;但对于更深层的流水线以及多发射处理器,我们需要更精确的分支预测,所以下面将介绍一些用于提升动态预测精度的高级技术。
例题(作为热身)



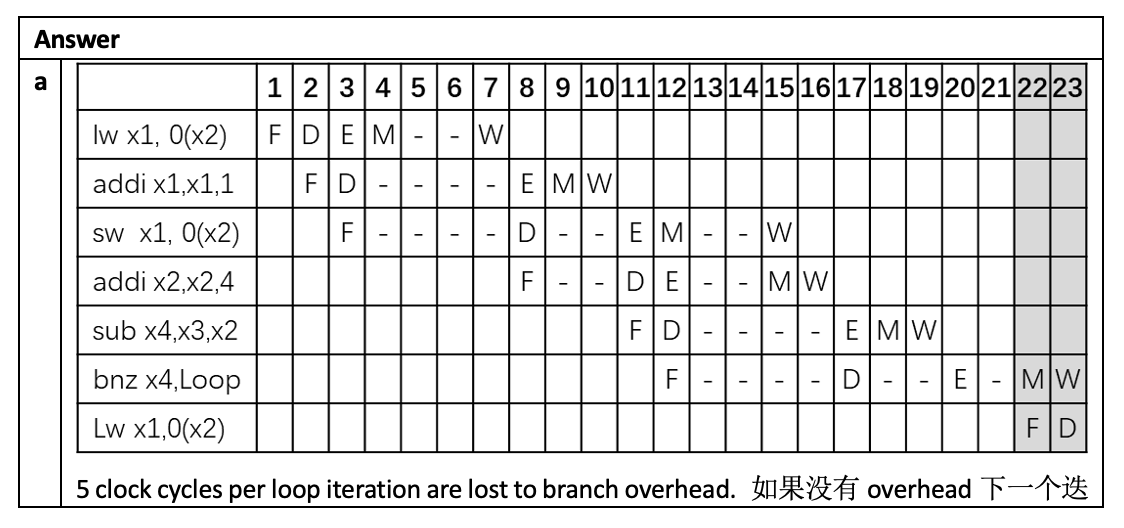


答案:A
- 尽管预测分支跳转,且实际也是跳转,但是要等到 EX 阶段结束后才知道跳转目标地址。因此在 ID 阶段和 EX 阶段读取的指令就要作废,因此有 2 个时钟周期的损失。
- 而预测分支不跳转的话就能和往常一样继续读取下一条指令,无需计算跳转目标地址,因此没有任何损失。
Correlating Branch Predictors⚓︎
我们之前介绍过一种 2 位预测器,它只能根据某个分支最近的行为来预测该分支的未来行为。事实上,我们也可以通过观察其他分支的最近行为来提升预测的精度。来看下面的例子:
例子
这是一段有多分支的代码:
对应的 RISC-V 代码为:
addi x3, x1, -2
bnez x3, L1 // branch b1
add x1, x0, x0 // aa = 0
L1:
addi x3, x2, 02
bnez x3, L2 // branch b2
add x2, x0, x0 // bb = 0
L2:
sub x3, x1, x2 // x3 = aa - bb
beqz x3, L3 // branch b3
可以发现分支 b3 的行为和分支 b1、b2 相关。如果预测器只能观察一个分支的行为的话,那么该预测器就会失效。
我们称能够利用其他分支的行为来预测的预测器为相关预测器(correlating predictors) 或两级预测器(two-level predictors)。相关预测器会添加和最近分支的行为相关的信息,来决定如何预测给定的分支。
一般的相关预测器有 2 个位:
- 第 1 位:若上次分支不跳转 (not taken, NT),将其作为当前分支参考依据
- 第 2 位:若上次分支跳转 (taken, T),将其作为当前分支参考依据
| 预测组合 | 第 1 位 | 第 2 位 |
|---|---|---|
| NT/NT | NT | NT |
| NT/T | NT | T |
| T/NT | T | NT |
| T/T | T | T |
注意
“上次分支”可能是同一条指令,也可能是不同的指令。
下图展示了相关预测器的结构:
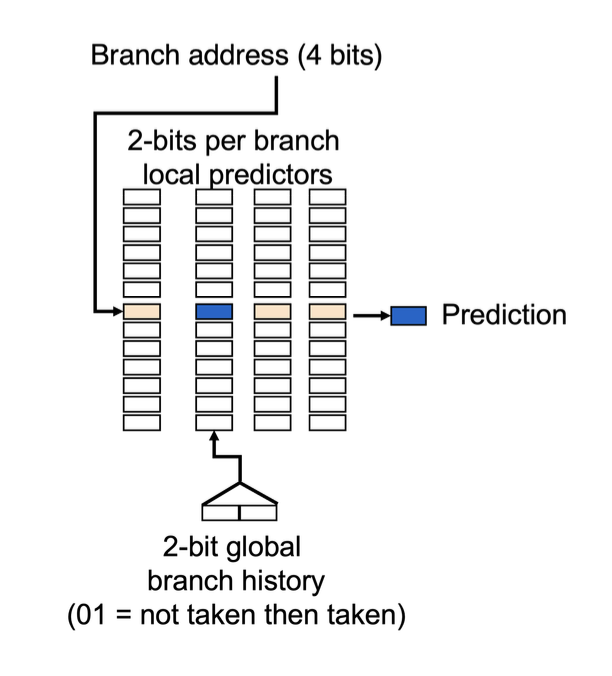
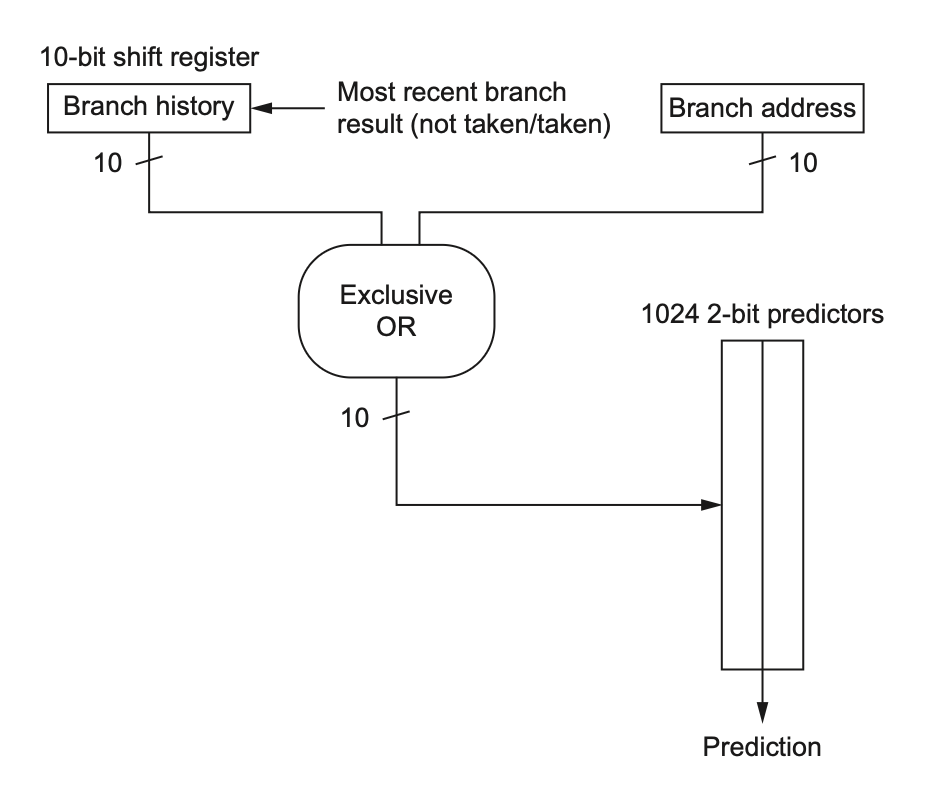
而一个 \((m, n)\) 相关预测器能够预测最近 \(m\) 个分支的行为,来选择 \(2^m\) 个分支预测器,每个都是对应单个分支的 \(n\) 位预测器。这类预测器能够在仅增加少量硬件的基础上,就能产生比 2 位预测器更高的预测率。相关预测器的结构大致如下所示:
\((m, n)\) 预测器的总位数为:
例子
带有 4K 个项的 (0, 2) 分支预测器有多少位?相同位数的 (2, 2) 预测器能装多少项?
带有 4K 项的预测器有 \(2^0 \times 2 \times 4K = 8K\ bits\)
(2, 2) 预测器的分支选择项有:\(\dfrac{8K}{2^2 \times 2} = 1K\) 个分支项
而硬件之所以简单,是因为关于最近 \(m\) 条分支的全局历史能够被一个 \(m\) 位移位寄存器记录下来,每一位表示对应分支是否被采用。然后分支预测缓冲器通过对分支地址的地位和 \(m\) 位全局历史的拼接来被索引。通过拼接(或简单的哈希函数)来结合局部和全局信息,我们能够为一个预测器表索引,得到比 2 位预测器更快的预测。而这种能够结合局部分支信息和全局分支历史的预测器也被称为合金预测器(alloyed predictors) 或混合预测器(hybrid predictors)。
Tournament Predictors⚓︎
锦标赛预测器(tournament predictors) 同样用到了多种预测器(全局 + 局部
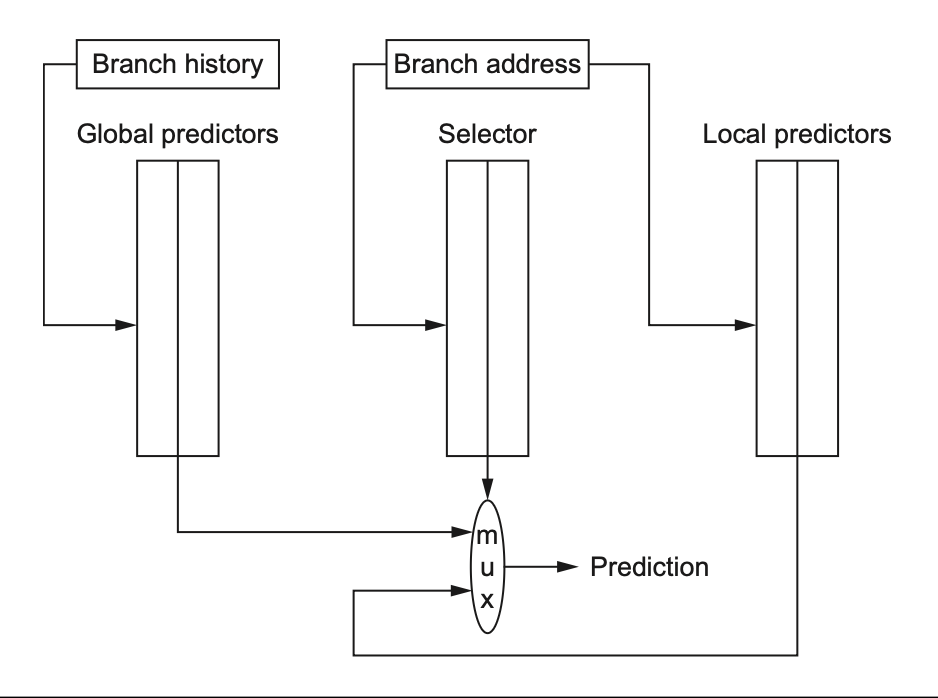
- 全局预测器(global predictors) 使用最近的分支历史来索引预测器
- 局部预测器(local predictors) 使用分支地址作为索引
锦标赛预测器在中等规模(8K-32K bits)下能够取得更好的精度,且能够有效利用大量的预测位。它会在每个分枝上用一个 2 位的渗透计数器,基于哪个预测器在最近带来更有效的预测,来选择两者中的一个。在原来的 2 位预测器中,这个渗透预测器在选择更好的预测器前会有两次错误的预测。
锦标赛预测器的优势是能够在特定分支上挑选正确预测器的能力,对于整数的基准测试而言相当关键。
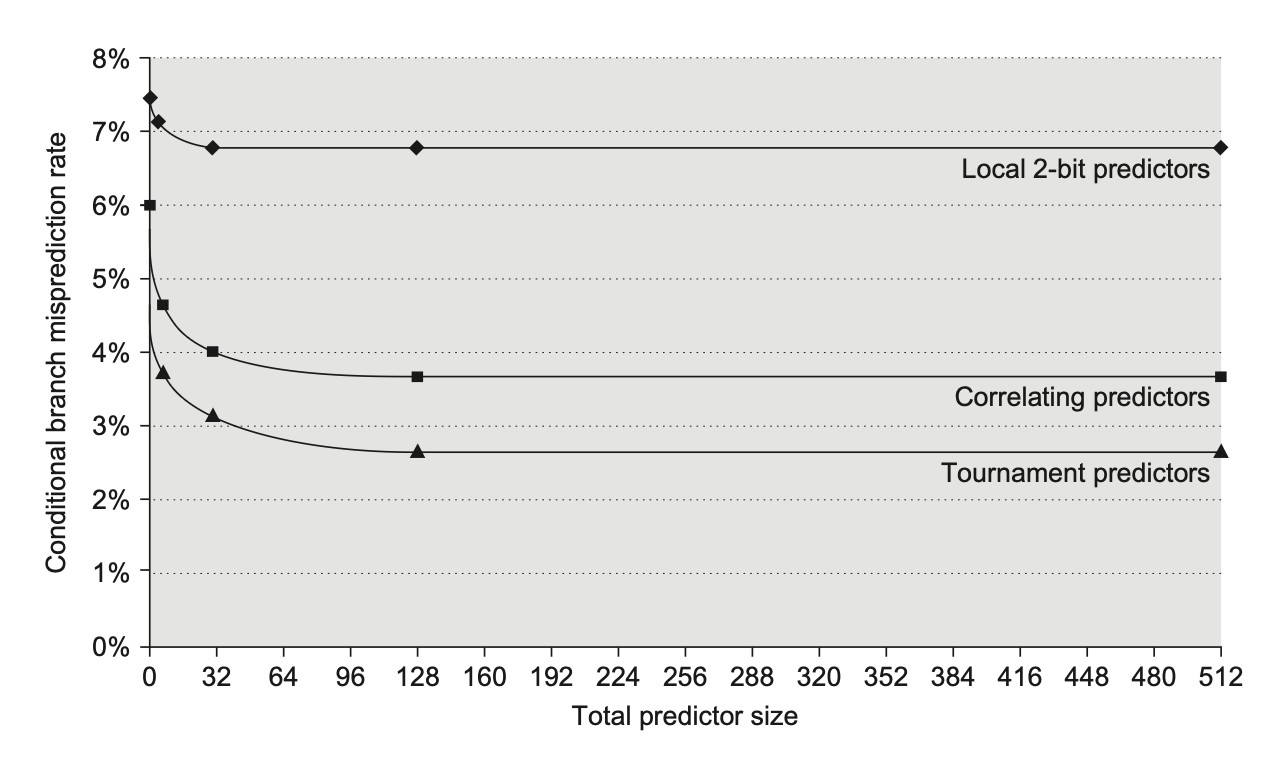
下图比较了已经介绍过的 3 类预测器的误预测率:
Tagged Hybrid Predictors⚓︎
有一类表现更好的预测器,它参照了一种叫做 PPM(prediction by partial matching,根据部分匹配预测)的类似分支预测算法的算法,使用了一系列用不同长度的历史索引的全局预测器——这类预测器称为带标签的混合预测器(tagged hybrid predictors),其大致结构如下所示:
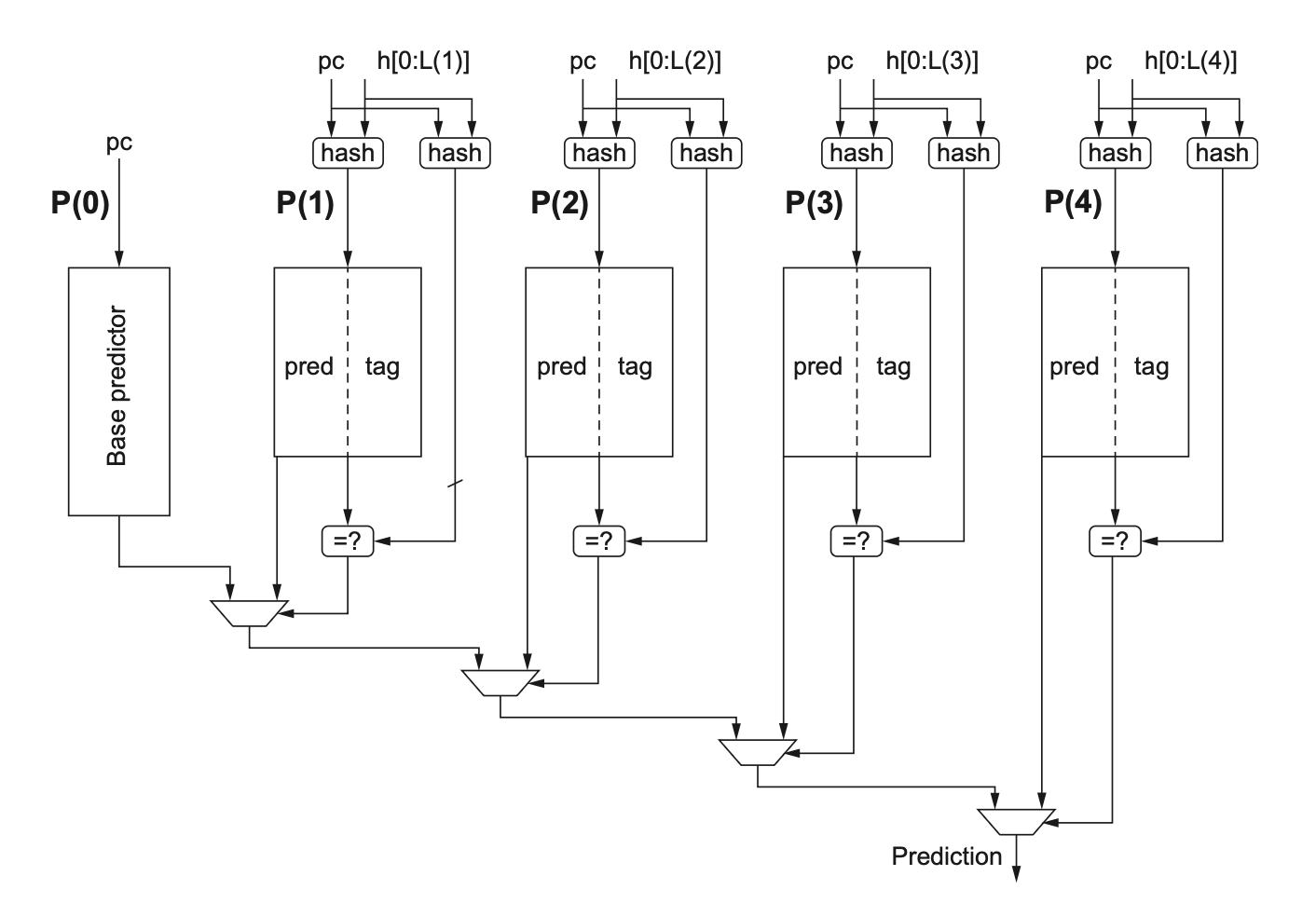
可以看到,它有 5 个预测表:\(P(0), P(1), \dots, P(4)\)。它使用 PC 的哈希值和最近 \(i\) 条分支(被保存在移位寄存器里)来访问 \(P(i)\) 。除了不同的历史长度外,另一个特点是在表 \(P(1), \dots, P(4)\) 上使用标签。一般情况下 4-8 位的小标签就能取得最佳效果了。仅当标签和分支地址和全局分支历史的哈希值匹配时,才会用到 \(P(1), \dots, P(4)\) 内的预测。\(P(0 \dots n)\) 例的每个预测器可以是一个标准的 2 位预测器。在实际上,3 位计数器的效果会略微优于 2 位计数器。
给定分支的预测来自于标签匹配的,且分支历史最长的预测器上。\(P(0)\) 总是能够匹配,因为它没有标签,因此如果其余表都没有匹配的话,那么它就提供默认的预测了。预测器里还会用到 2 位的使用字段(use field),用于表明预测是否在最近被用到过,因此它可能是更精确的。所有的使用字段会被周期性地复位,以清除旧的预测。
这类预测器的缺点是实现上过于复杂,且可能会更慢(因为检查多个标签,选择预测结果需要时间
而更大的预测器会带来其他问题,比如如何初始化预测器——如果是随机的话,那么需要花费相当多的执行时间。所以有些预测器会用一个合法位,来表明预测器里的元素是否被置位,或处于“未使用状态”。
Dynamic Scheduling⚓︎
先简单回顾静态调度(static scheduling) 的概念:静态调度的流水线处理器在获取指令后会发射该指令,除非发现该指令存在数据依赖且无法通过前递 (forwarding) 来隐藏该指令,此时冒险检测硬件会暂停流水线,直到依赖清除后在获取新的指令。
本节我们将介绍动态调度(dynamic scheduling),它是一种在程序执行时,根据当前的处理器状态和资源可用性来决定指令执行顺序的技术。具体来说,它通过硬件重排指令的执行,以减少停顿,同时维护了(即不会改变)数据流和异常行为。它的优点有:
- 可以让在某个流水线上被编译的代码在其他流水线上也能高效运行,消除了多份二进制文件以及重新编译的需求
- 能够处理在编译时没有被发现的依赖,比如内存引用或数据依赖分支,或者采用现代的动态链接或分派
- 能让处理器容忍无法预测的时延,比如对于高速缓存失效,可通过在等待失效解决时执行其他代码来实现这一点
下一节还会介绍一种叫做推测 (speculation) 的技术,它建立在动态调度的基础上,能够为处理器带来额外的性能优势,但代价是增加了硬件的复杂程度。
简单流水线技术的一大限制是采用有序(in-order) 指令发射和执行,即指令按照程序顺序发射,如果有指令停顿了,后面的指令就不得继续执行。因此,如果两条很接近的指令间存在依赖,那么就会导致冒险发生,因而产生停顿;如果有多个功能单元的话,那这些单元在停顿期间就处于空闲状态了。对于下面的指令序列:
前两条指令存在依赖关系,因而产生停顿。第三条指令和前两条没有依赖关系,但也不得不跟着一起停顿。所以我们希望在停顿发生时还能继续执行第三条指令。为了做到这一点,我们将发射过程分为两部分:检查任何的结构冒险,以及等待数据冒险的消失。因此我们仍然使用有序的指令发射,但我们希望当处理器的操作数空闲时就能执行指令,这样的流水线做的就是乱序执行(out-of-order execution)。
乱序执行会引入 WAR 和 WAW 冒险的可能,这在原来的流水线中是没有的,不过这两类冒险都可以用寄存器重命名来避免。
例子
对于以下指令序列:
- 第 2、3 条指令间存在反依赖,所以若第 3 条指令先于前一条指令执行的话,就会违背该依赖,导致 WAR 冒险的发生
- 第 1、3 条指令间存在输出依赖,所以若第 3 条指令先于第 1 条指令执行的话,就会违背该依赖,导致 WAW 冒险的发生

确定这 6 条指令的依赖关系:
- I1 写入
x6-> I4、I5 读取x6 - I3 写入
x2-> I5、I6 读取x2 - I5 写入
x8-> I6 读取x8
A、C、D 均遵守上述依赖关系,唯有 B 出现了 I5 先于 I3 执行的情况,这会影响到最终的执行结果,因此是不正确的。
乱序执行还会为处理异常带来麻烦。动态调度处理器会通过延后通知某条指令异常,直到处理器知道该指令是下一条要被执行的指令时,来保留异常行为。此外,动态调度处理器还会产生不精确(imprecise) 的异常,即异常发生时处理器无法确保异常点之前的所有指令均已完成执行,且后续指令可能已部分执行的状态。
与之相对的精确异常(Precise Exception)会严格保证异常点的指令上下文完全可重现。现代处理器通常通过检查点恢复(类似数据库系统的 ARIES 算法)或重排序缓冲区(ROB)等机制将不精确异常转化为精确异常处理。
不精确的异常会加大异常发生后重新执行的难度,所以之后在介绍推测技术时会介绍一种解决方案:在带有推测的处理器上提供精确的异常。
例子

答案:C
- A 和 B 是精确异常的定义,不多解释
- C:导致异常的指令的地址不是放在
mtvec(机器陷阱向量基地址寄存器 (machine trap vector base address register)) ,而是放在mepc(机器异常程序计数器 (machine exception program counter))里的。mtvec存储的是异常处理程序的入口地址 - D
: mtval(机器陷阱值寄存器 (machine trap value register)) ,它的功能和选项一致
为了实现乱序执行,我们将流水线的 ID(译码)阶段划分为两个子阶段:
- 发射(issue, IS):对指令译码,检查结构冒险(顺序发射)
- 读取操作数(read operands, RO):等待,直到没有数据冒险,然后读取操作数(乱序执行)
我们需要区分指令何时开始执行,以及何时完成执行;而在这两个时间点之间,我们认为指令正在执行。并且我们假设处理器有多个功能单元,以实现多指令的同时执行。
有以下实现动态调度的技术:
- 记分板(scoreboarding):当有足够资源以及没有数据依赖的情况下,允许指令乱序执行的技术。
- 托马苏洛算法(Tomasulo's algorithm):相比记分板更为精密的技术,它能够通过动态地为寄存器重命名来处理反依赖和输出依赖的问题;此外它还可以被扩展,用于处理推测。
下面将详细介绍这些技术。
注
我们主要关注该算法在 RISC-V 指令集,以及在浮点数单元 (float-point unit) 和加载 - 存储单元 (load-store unit) 上的表现。
Scoreboarding⚓︎
记分板是一项能够让指令在有足够资源以及没有数据依赖的情况下乱序执行的技术。它的目标是通过尽早执行指令,维护执行速率至每时钟周期一条指令。因此,当下一条要执行的指令被停顿时,可以发射和执行其他不依赖于任何当前处于活跃或停顿状态的指令的指令。可以看到,记分板会对指令的发射、执行以及对所有的冒险检测负责,可见其责任重大。
下图展示了带有记分板的 RISC-V 架构下的处理器基本结构:

每条指令(主要针对浮点数运算)要经历以下执行步骤:
-
发射(issue):
- 若所需功能单元空闲,且没有其他指令用到和当前指令相同的寄存器,那么记分板就将指令发射到这个功能单元上,并更新其内部数据结构。
- 该步骤替换了原来 RISC-V 流水线中的 ID 阶段。
- 通过确保没有其他活跃的功能单元想要将结果写入到相同的目标寄存器中,我们保证了 WAW 冒险不会发生。
- 如果结构冒险或 WAW 冒险存在,那么必须停止指令发射(包括其他指令
) ,直到这些冒险都不存在为止。 - 当停顿发射时,IF(指令获取)和发射阶段之间的缓冲区将会被填充。
- 如果缓冲区只保存单项,IF 能够立刻停止;
- 如果缓冲区是一个能保存多条指令的队列,那么只有当队列被填满时 IF 才停止。
-
读取操作数(read operands):
- 记分监控源操作数的可用性。
- 若没有先前发射的活跃指令要向其写入的话,该源操作数就是空闲的,此时记分板会告诉功能单元可以从寄存器读取该操作数,并继续执行下去。
- 记分板在这步动态解决了 RAW 冒险,且指令可能以乱序形式被送往执行阶段。
- 该步骤结合上一步,完成了原 RISC-V 流水线上的 ID 阶段的功能。
-
执行(execution):
- 一旦接收到所有操作数,功能单元开始执行。
- 当结果计算出来后,它通知记分板这一完成情况。
- 该步骤取代了原 RISC-V 流水线的 EX 阶段,且需要在浮点数运算上花费多个时钟周期。
-
写入结果(write result):
- 一旦记分板知道功能单元完成执行,它会先检查 WAR 冒险,如有必要会停顿这一完成执行的指令。
- 当出现以下情况时,完成执行的指令暂时不能写入其结果:先于完成执行指令之前的指令还没有读取操作数,且这个操作数和完成执行指令的结果用到相同的寄存器。
- 如果 WAR 不存在或被消除,记分板告诉功能单元将结果存储到目标寄存器中。
- 这一步替代原 RISC-V 流水线的 WB 阶段。
不同于简单流水线,该方法确保一旦完成执行后,指令的结果就立马被写入到寄存器堆中(假设没有冒险
基于自身的数据结构,记分板通过和功能单元间的通信来控制指令于各阶段的前进。但寄存器堆的源操作数总线和结果总线数量有限,表明可能存在结构冒险问题。因此记分板必须保证在第 2-4 步中功能单元的允许数量不超过可用的总线数。而 CDC 6600 则通过将 16 个功能单元划分为 4 个组,为每个组提供一个数据干线(data trunk)(一组总线
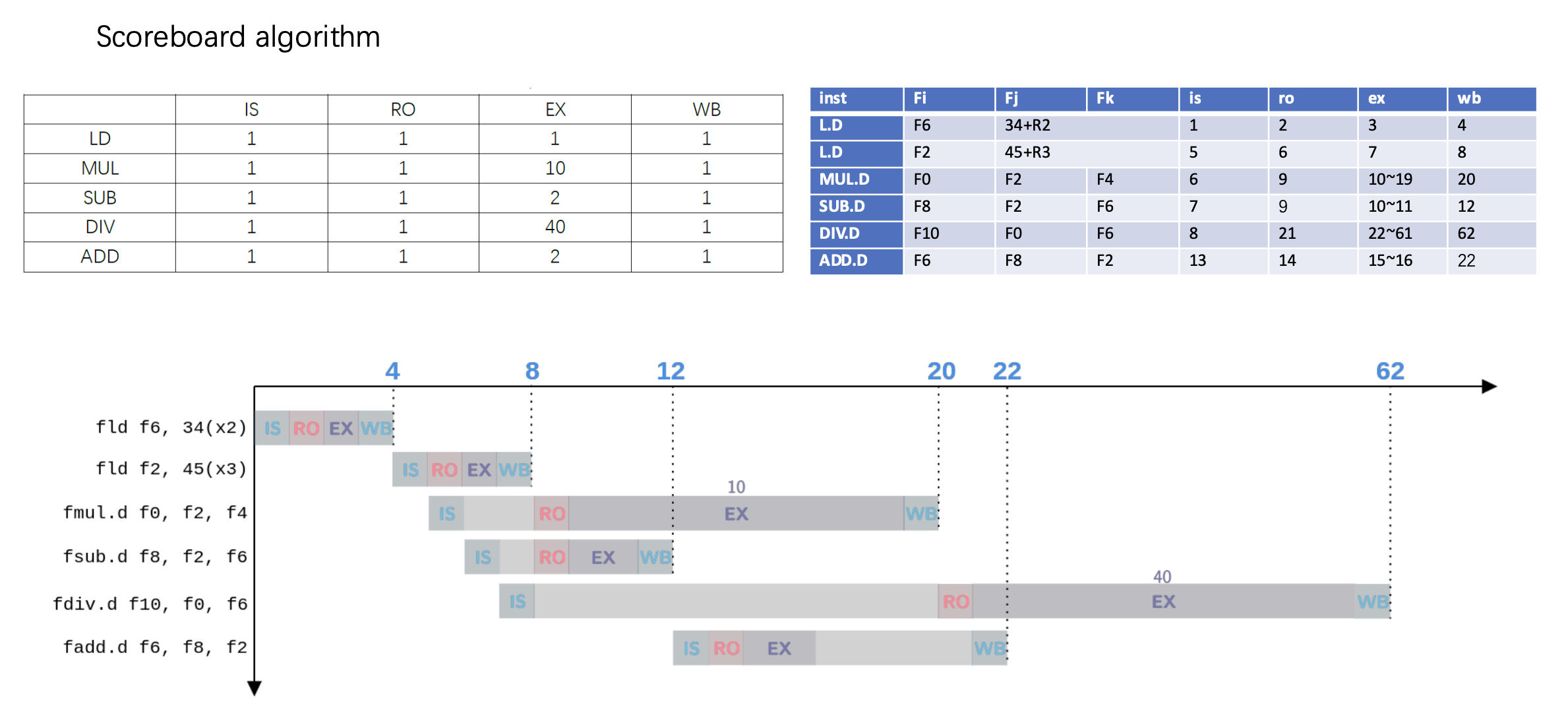
在分析记分板时,我们会用到以下三张表:
- 指令状态表(instruction status table):记录指令所处的阶段和状态
- 功能单元状态表(functional unit status table):会记录以下一些信息
- busy:功能单元是否空闲
- op:正在执行的操作
- Fi, Fj, Fk:操作数对应的寄存器
- Qj, Qk:操作数的来源(功能单元)
- Rj, Rk:操作数的预备状态
- 寄存器状态表(register status table):
- 如果寄存器的值还在某个功能单元内计算,则保留这个操作的编号
- 计算完毕后填入实际值
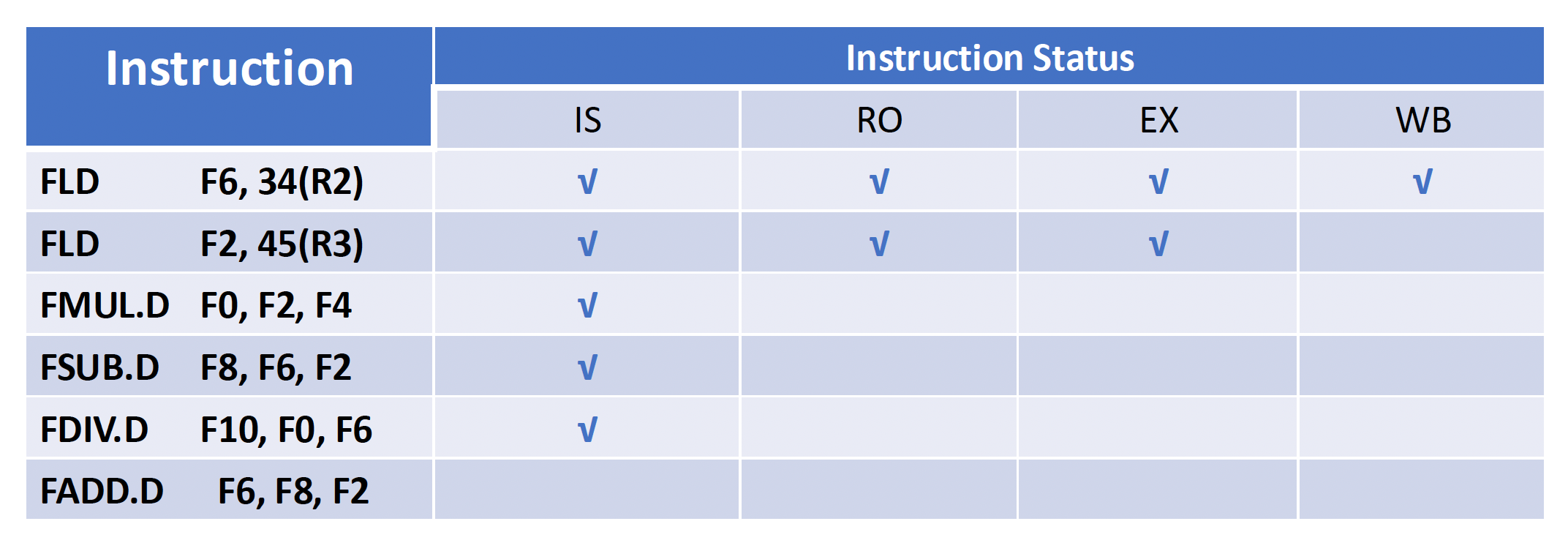
例子

假设上题为 Q1,下面还有 2 个小问:
- Q2:Show what the status tables look like when the
FMUL.Dis ready to write its result. - Q3:Show what the status tables look like when the
FDIV.Dis ready to write its result.

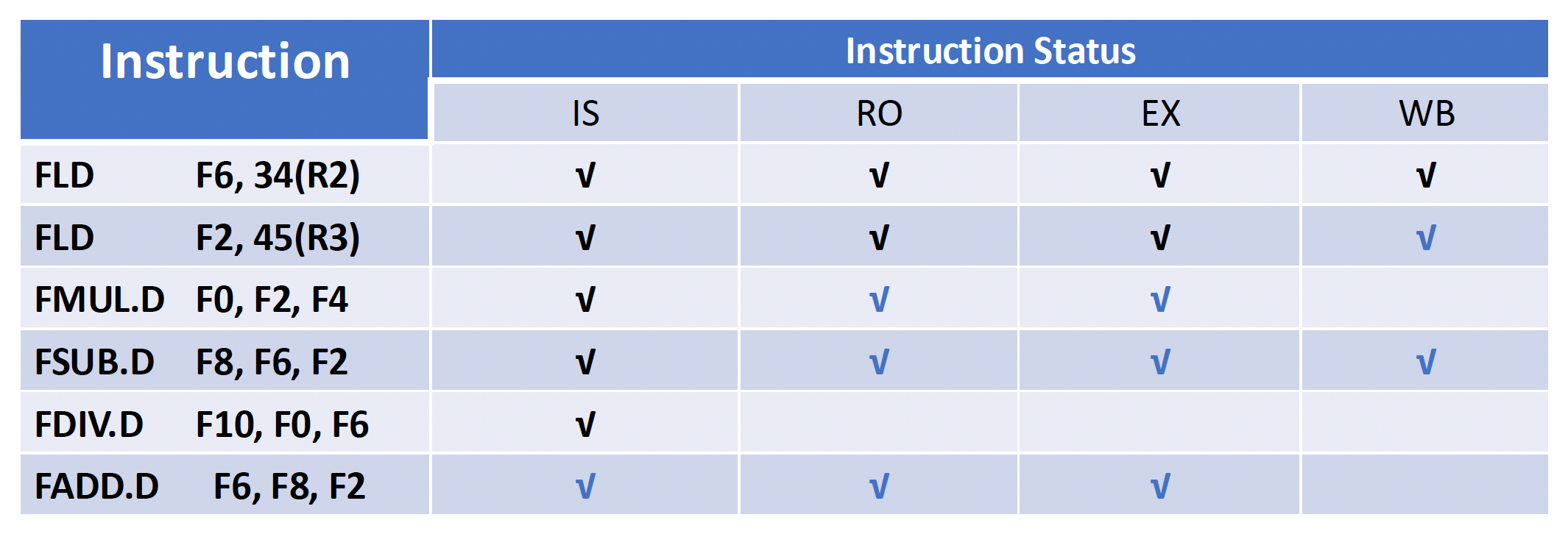
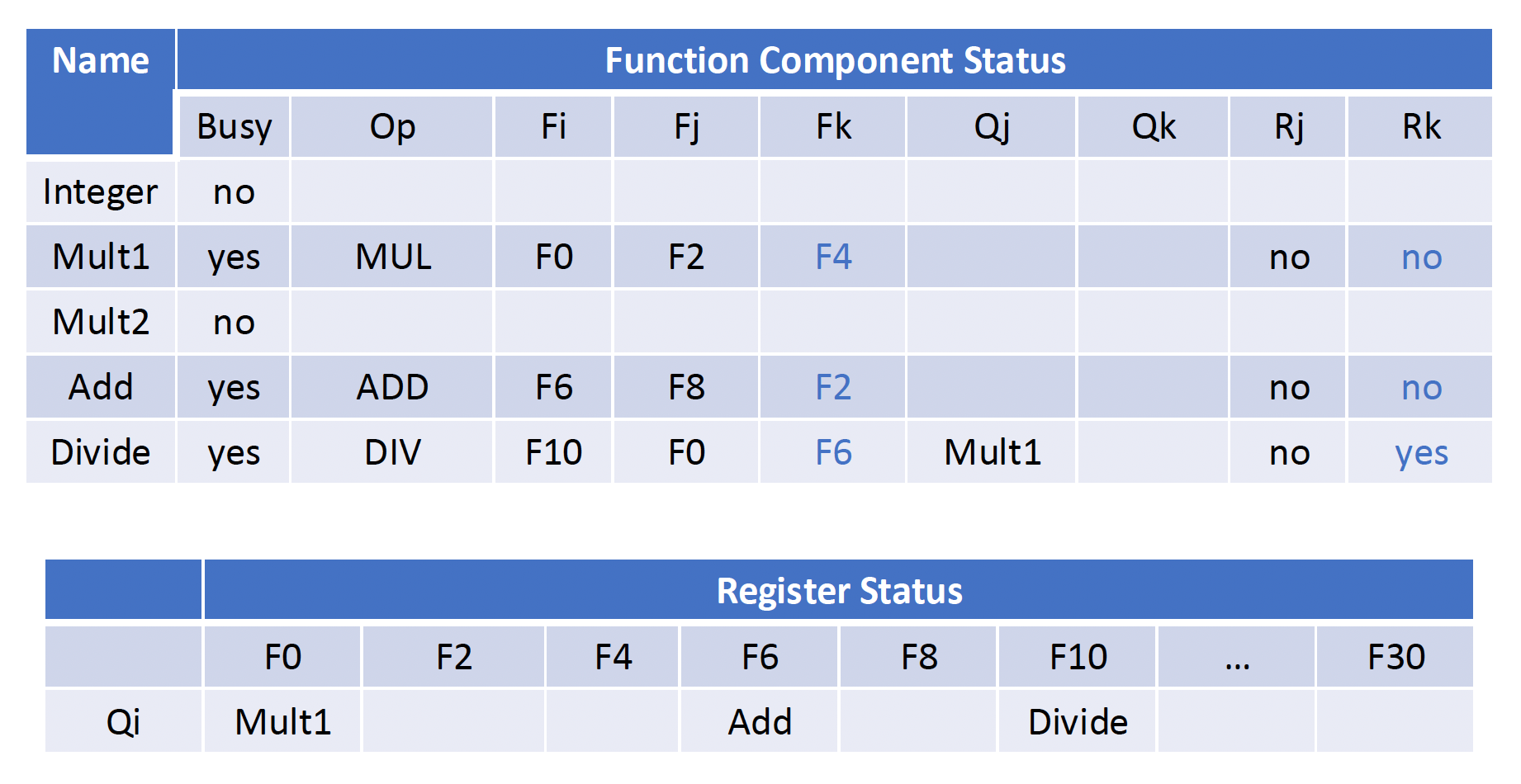
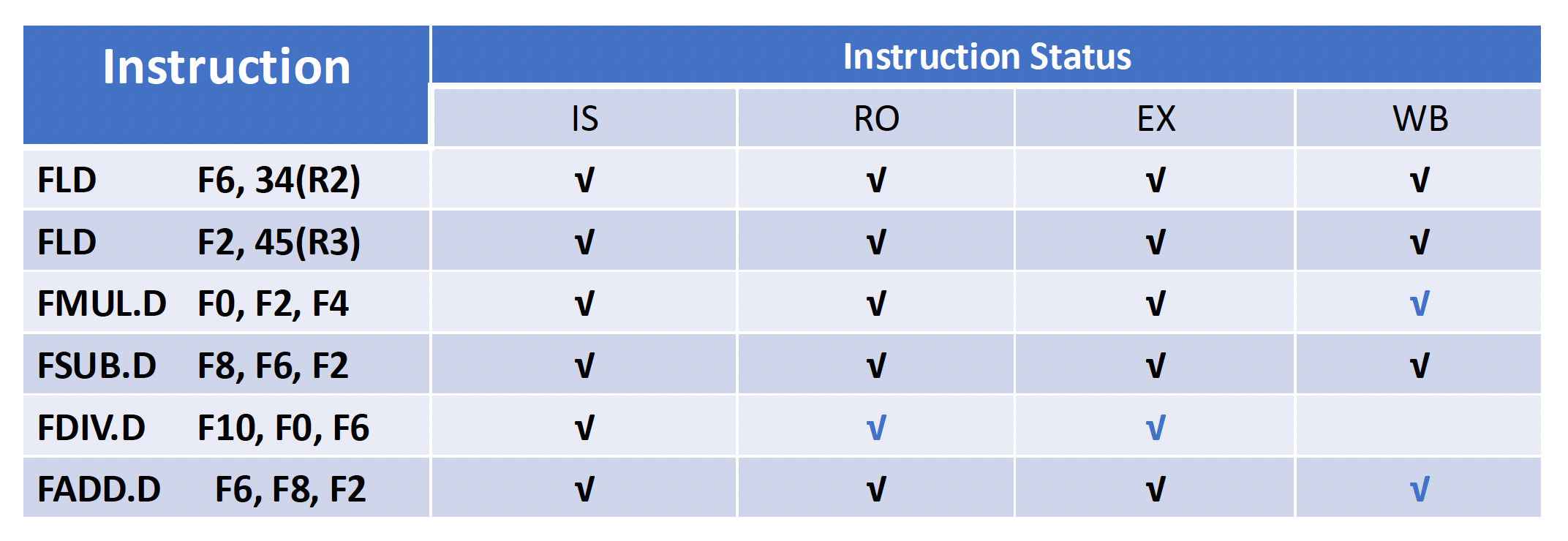
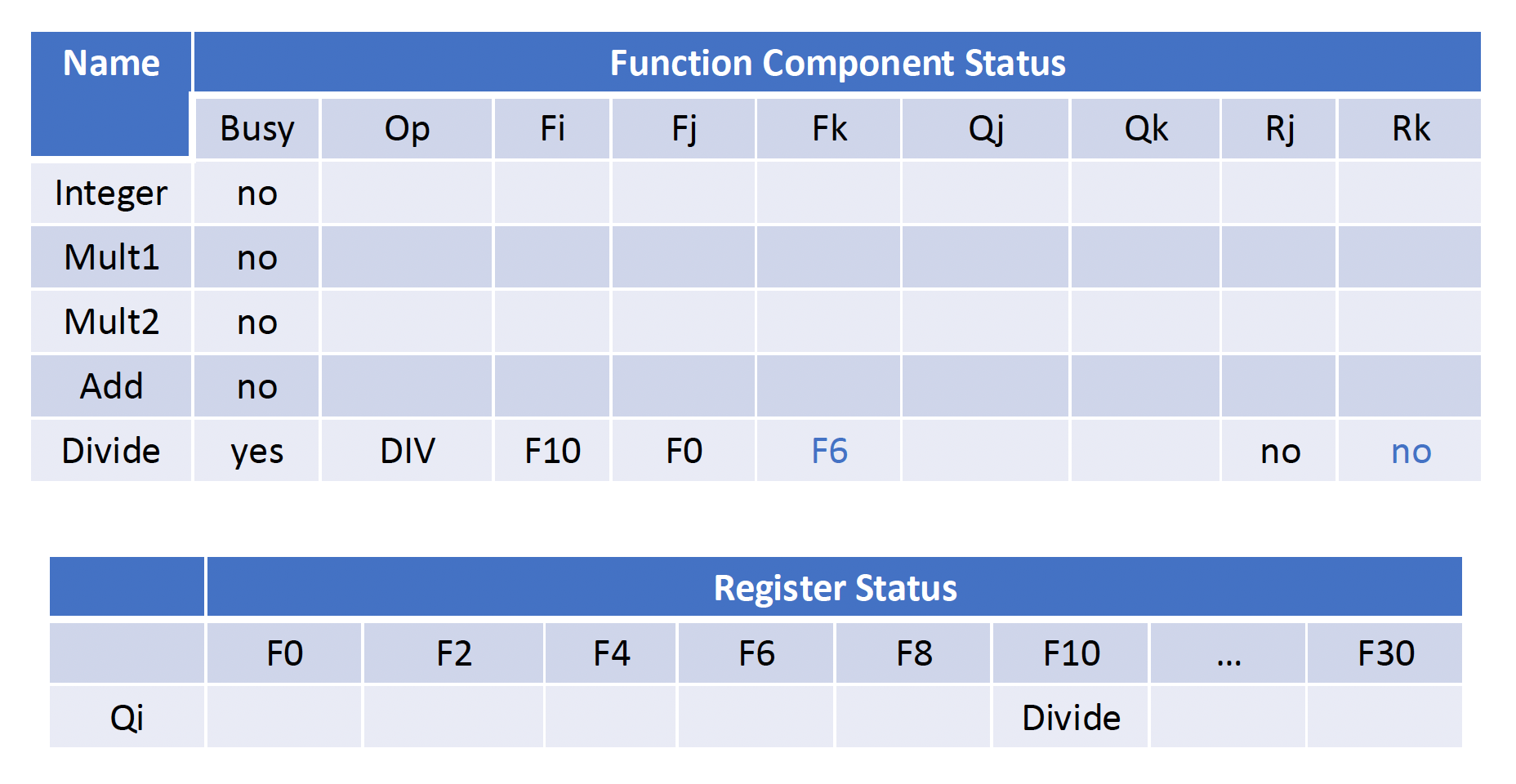



限制记分板的因素
- ILP 程度:如果我们找不到能够执行的独立指令,那么记分板就没什么作用了。
- 发射序列的大小:
- 该因素决定了 CPU 要提前多久去寻找能够并行的指令
- 又称为视窗(window)
- 目前我们假设视窗不会横跨一个分支,即视窗仅包含一个基本块内的指令
- 功能单元的数量、类型和速度:决定了结构冒险产生停顿的频率
- 反依赖和输出依赖的存在
- 相比 RAW 冒险,WAR 和 WAW 冒险对记分板的限制更大,因为它们会带来停顿
- RAW 问题出现于任何技术中,但 WAR 和 WAW 冒险可以用除了记分板之外的方法解决
Tomasulo's Algorithm⚓︎
在使用托马苏洛算法的动态调度处理器中,
- RAW 冒险可通过在操作数空闲时就执行指令来避免
- WAR 和 WAW 冒险可通过寄存器重命名(register renaming) 来消除。
其中寄存器重命名通过重命名所有的目标寄存器,包括等待先前指令读 / 写的寄存器来实现,这样的话乱序写操作就不会影响到任何依赖于操作数先前值的指令。如果有足够多可用的寄存器的话,编译器就会实现这种重命名。
例子
这是原来的指令序列,里面有 WAR 和 WAW 的问题:
其中第 2、4 条指令和第 3、5 条指令之间存在反依赖(对应 WAR 冒险ST)来消除,如下所示:
在托马苏洛算法中,寄存器重命名由保留站(reservation station) 实现。它作为正在等待发射且和功能单元相关的指令的缓冲区(其物理属性更接近于寄存器
保留站的使用带来的重要性质有:
- 冒险检测和执行控制是被分配好的:在每个功能单元内,保留站保存的信息用于确定指令何时在该单元开始执行
- 源操作数直接从缓存它们的保留站中传到功能单元内,而无需经过寄存器。这种旁路 (bypassing) 操作通过一根公共数据总线(common data bus, CDB) 来实现,它允许为所有单元同时加载正在等待的操作数
下图展示了基于托马苏洛算法的浮点数单元的基本结构:
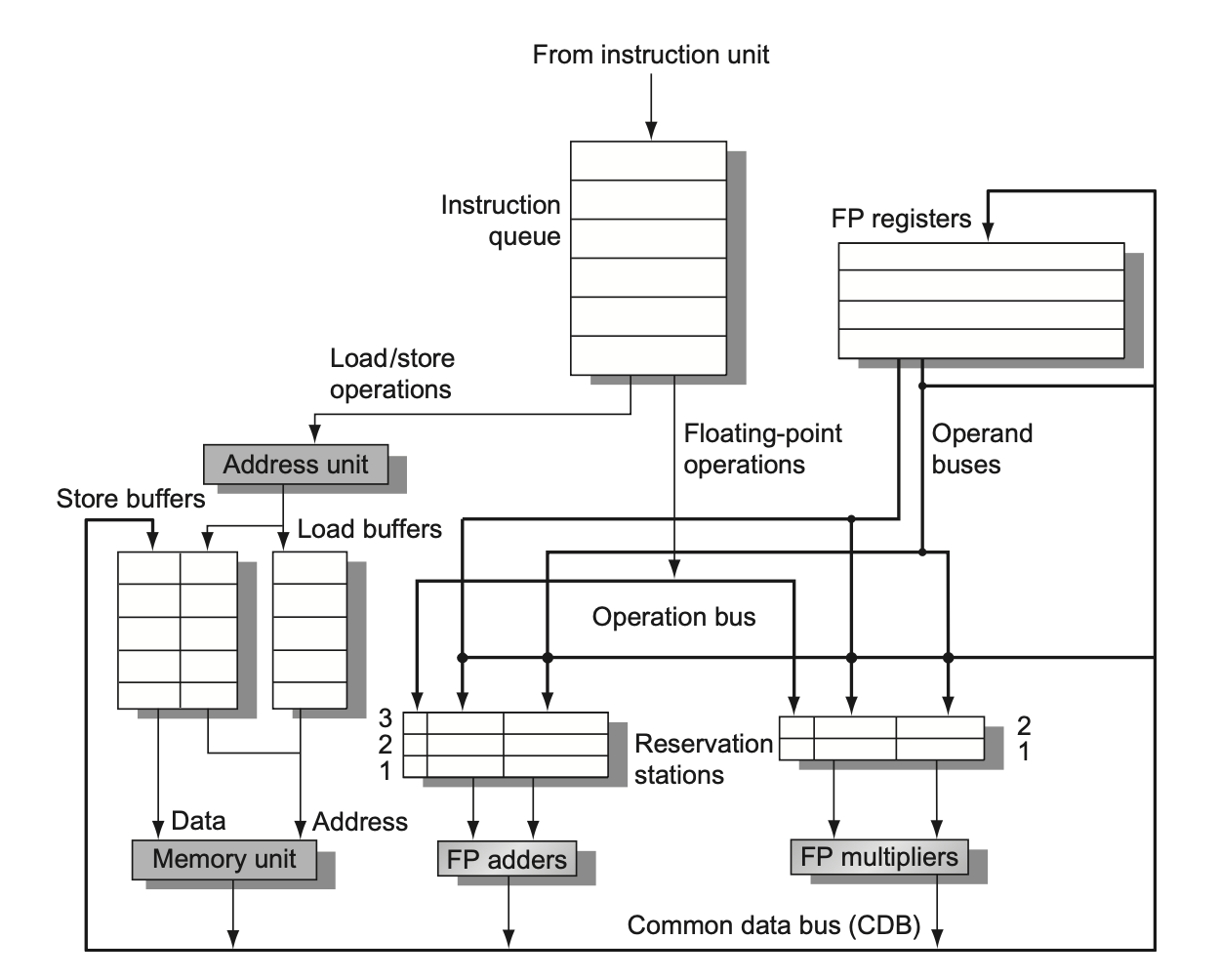
- 里面包含了浮点数单元和加载 - 存储单元
- 每个保留站保存了一个被发射的,且正等待在功能单元内被执行的指令
- 如果该指令的操作数值已经被计算出来的话,那么该值也会被一起保存;否则保留站会保存那些提供操作数值的保留站的名称
- 加载缓冲区和存储缓冲区分别保留了来自或前往内存的数据或地址,表现上和保留站类似
- 浮点数寄存器被一对来自功能单元的总线,以及一根来自存储缓冲区的总线连接
- 所有来自功能单元和内存的结果会被送到 CDB 上,该总线除了不经过加载缓冲区外,会经过其他所有部件
- 所有的保留站都有一个标签字段,为流水线控制所用
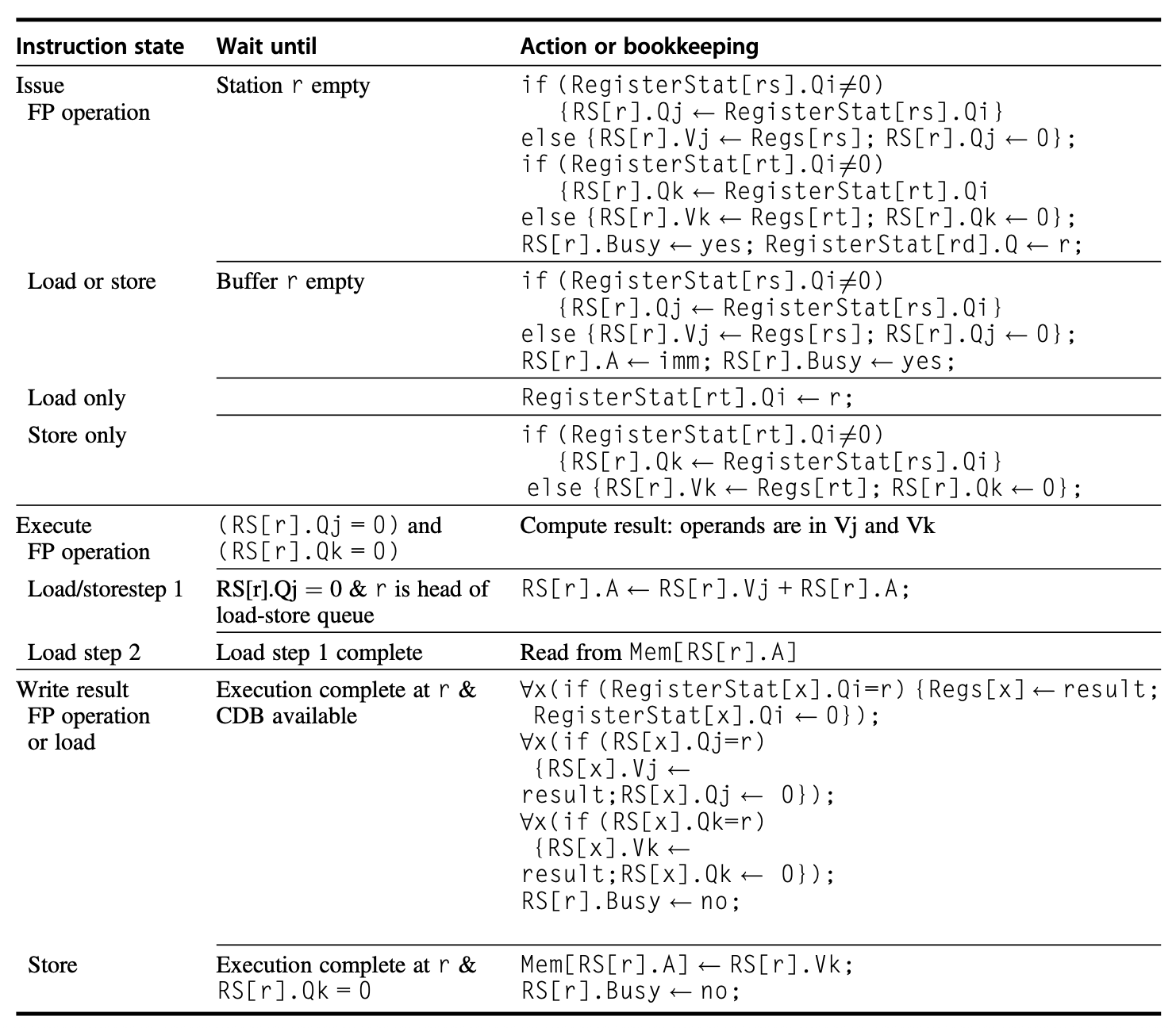
在上述处理器中,一条指令会经过以下三步:
- 发射(issue)(有时会称为分派(dispatch)
) :- 从指令队列(FIFO 顺序,以维持正确的数据流)的队首中获取下一条指令
- 如果该指令匹配到的保留站是空的,那么将该指令及其操作数(如果当前已在寄存器内的话)发射到该保留站内
- 如果没有空的保留站,那么就存在结构冒险,指令发射停止,直到某个保留站空间被释放
- 如果操作数不在寄存器内,那么追踪会产生操作数值的那个功能单元
- 这一步实现了寄存器重命名,消除了寄存器内的 WAR 和 WAW 冒险
- 执行(execute):
- 如果一个或多个操作数不可用的话,那么保留站监控 CDB,等待操作数被计算出来
- 当某个操作数可用时,它将会被放到任何等待它的保留站内
- 当某个操作的所有操作数都可用时,该操作就会在对应的功能单元内被执行
- 通过延时到所有操作数都可用时再执行指令,RAW 冒险得以避免
- 有时多条指令可能在相同的时钟周期下准备就绪,且要用同一个功能单元,此时该单元不得不从中做出选择,比如浮点数单元是随机挑选的,而加载 - 存储单元则更加复杂
- 加载和存储需要两步执行过程:
- 当基寄存器可用时,计算有效地址
- 然后将其放在加载或存储缓冲区内
- 对于加载,当内存单元可用时,加载会立马执行;对于存储,在值被送到内存单元前,会一直等待执行
- 为了保留异常行为,直到在程序顺序中先于指令的分支完成执行后,才允许后面的指令被执行
- 如果处理器记录了异常的发生,但没有发起异常,那么该指令会被执行而不停顿,直到它进入“写入结果”阶段
- 这个阶段还会涉及到推测,放在下一节介绍
- 写入结果(write result):
- 当结果可用时,将其写入 CDB 中,然后再写到寄存器以及任何等待该结果的保留站中(包括存储缓冲区
) 。这一操作称为广播(broadcast)) - 存储操作一直缓存在存储缓冲区内,直到值被存储,且存储地址可用,此时结果被写入空余的内存单元上
- 当结果可用时,将其写入 CDB 中,然后再写到寄存器以及任何等待该结果的保留站中(包括存储缓冲区
用于检测和消除冒险的数据结构被附加在保留站、寄存器堆以及加载和存储缓冲区上,它们的信息有略微的区别。这些标签是用于重命名的虚拟寄存器的名称。在上面的处理器中,标签位是 4 位的,指代 5 个保留站以及 5 个加载缓冲区中的 1 个,这样就需要 10 个寄存器,用以描述哪个保留站能够产生源操作数结果的指令。由于保留站的数量多于真正的寄存器的数量,因此 WAW 和 WAR 冒险可通过使用保留站编码重命名结果来被消除。
CDB 和保留站从总线中对结果的检索实现了在静态调度流水线中用到的前递(或旁路)机制,但相比起来动态调度方法还会引入一个时钟周期的时延。
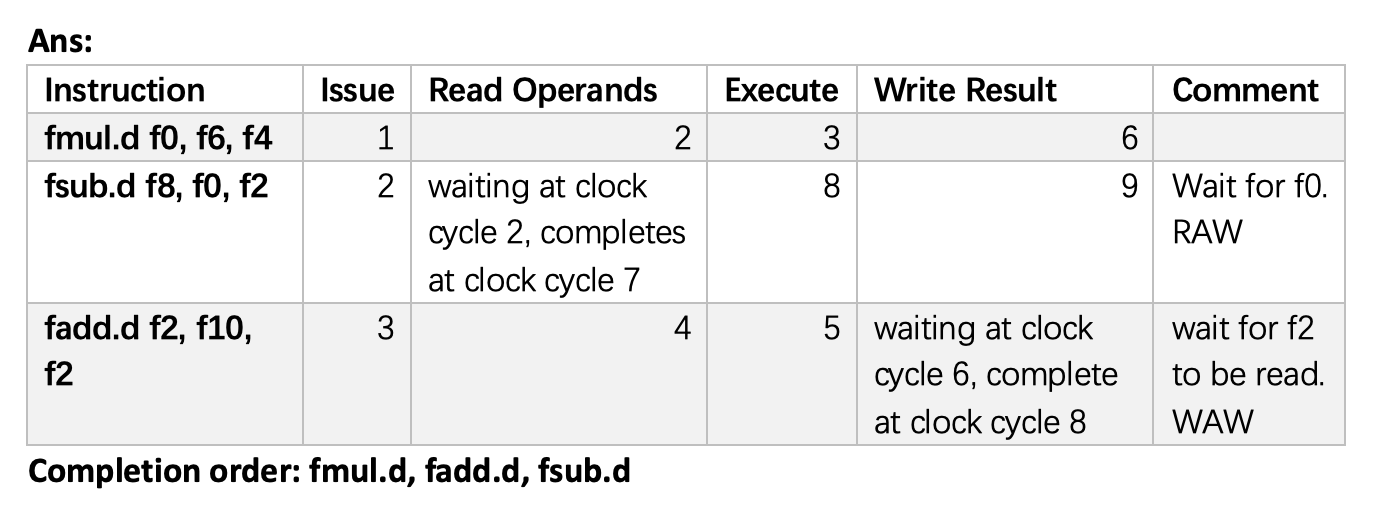
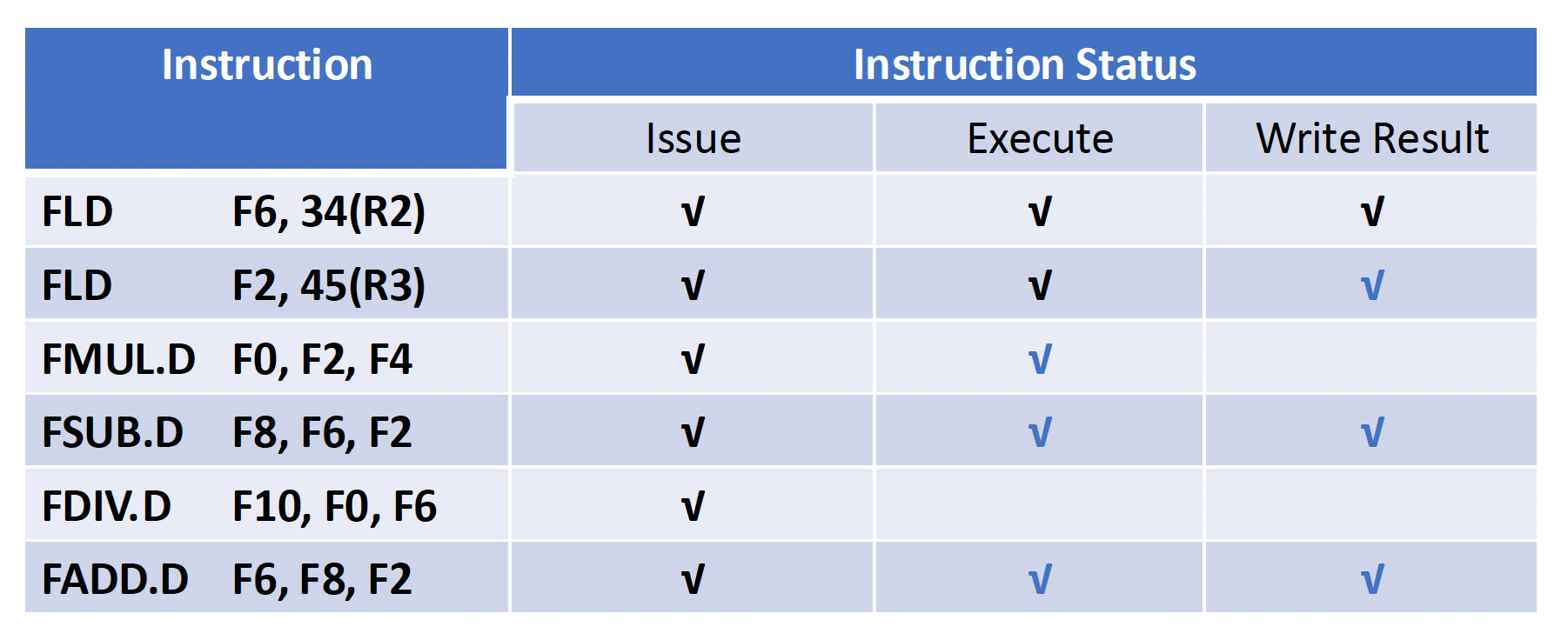
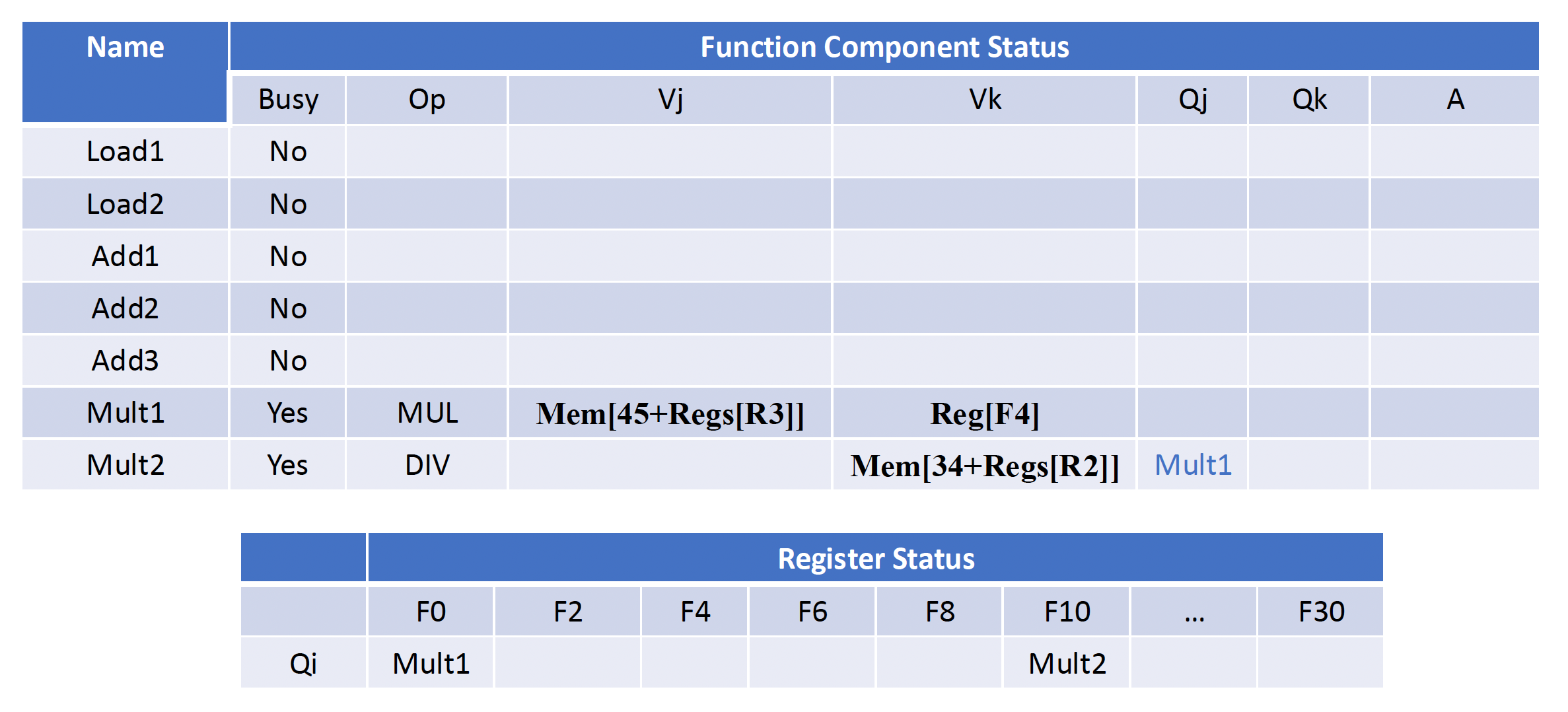
在用托马苏洛算法分析时,我们会用到以下表格:
- 指令状态表(instruction status table):仅用于帮助我们理解算法,实际上并不属于硬件的一部分
- 保留站表(reservation stattion table):保留每个已发射的运算的状态
- 寄存器状态表(register status table):包含结果需要被存储到寄存器的运算的保留站数量
每个保留站有 7 个字段:
- Op:在源操作数 S1 和 S2 上的操作
- Qj, Qk:产生对应源操作数的保留站。值为 0 表示源操作数已经在 Vj 或 Vk 上可用
- Vj, Vk:源操作数的值。注意对每个操作数而言,Q 字段或 V 字段中只有一个是有效的。对于加载,Vk 字段用于保留偏移字段
- A:保留加载或存储的内存地址计算信息。最开始指令的立即数字段会存在这里;经过地址计算后,有效地址会存在这里
- Busy:表明保留站以及对应的功能单元是否被占据
托马苏洛算法的优点
- 冒险检测单元的分布:该优势来自于分布的保留站和 CDB 的使用。如果多条指令等待相同的结果,且每条指令的其他操作数均以准备就绪,那么通过 CDB 对结果的广播,指令得以同时释放。
- 消除因 WAW 和 WAR 冒险导致的停顿:该优势通过保留站重命名寄存器,以及在保留站存储可用操作数来实现的。
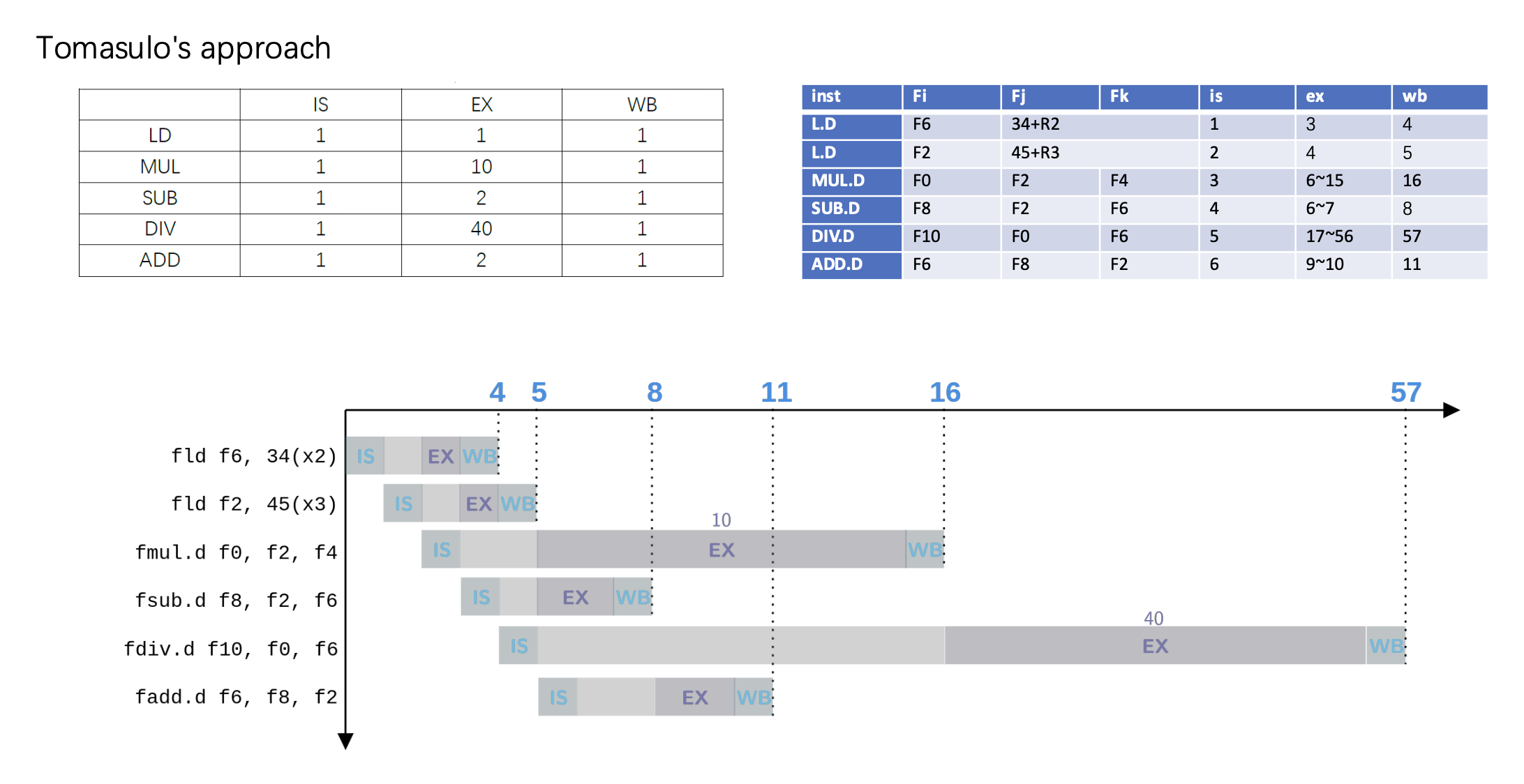
托马苏洛算法的具体步骤如下所示:
下面是一些采用托马苏洛算法的例子:
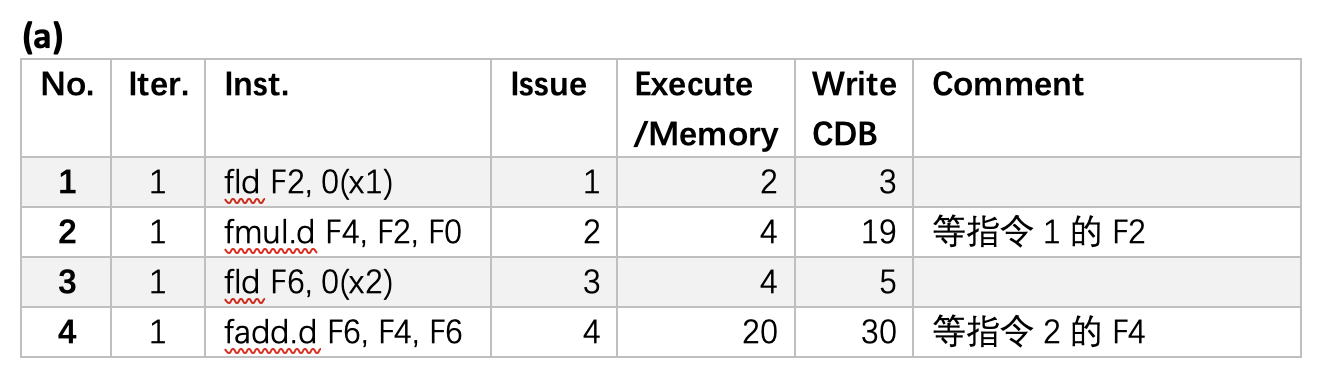
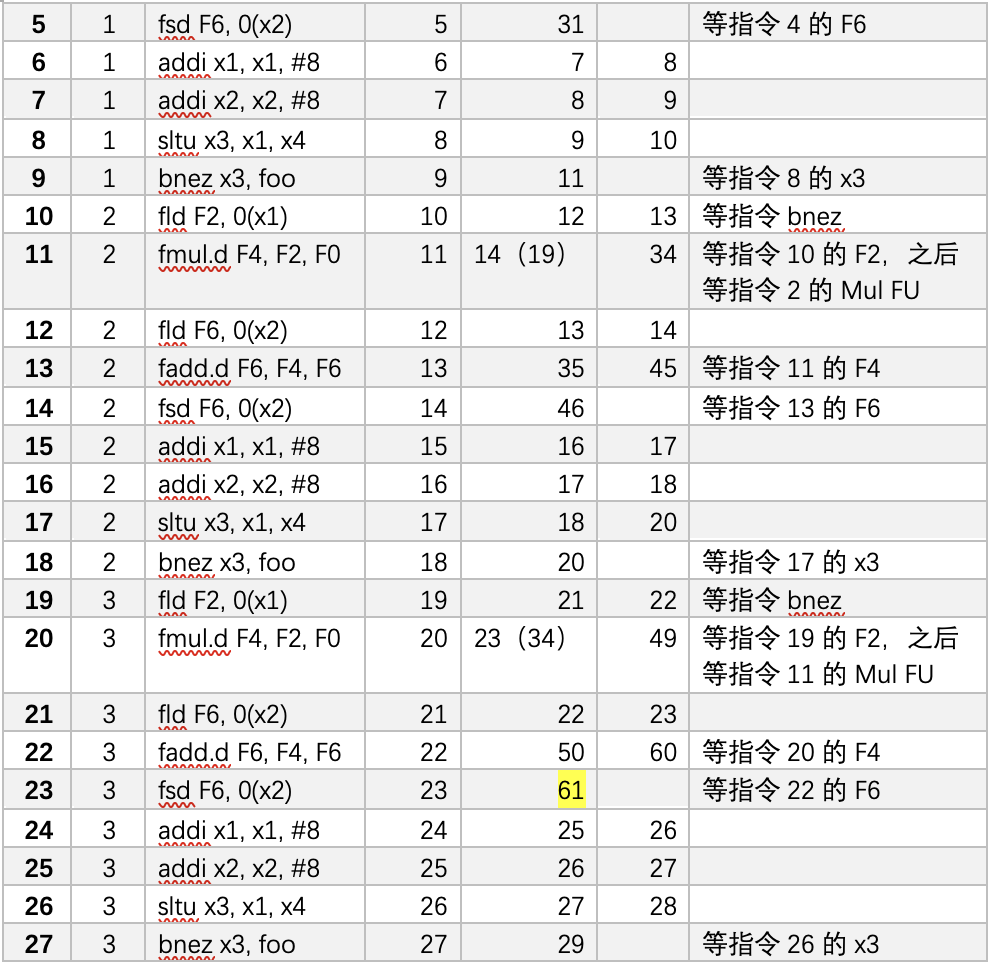
例子

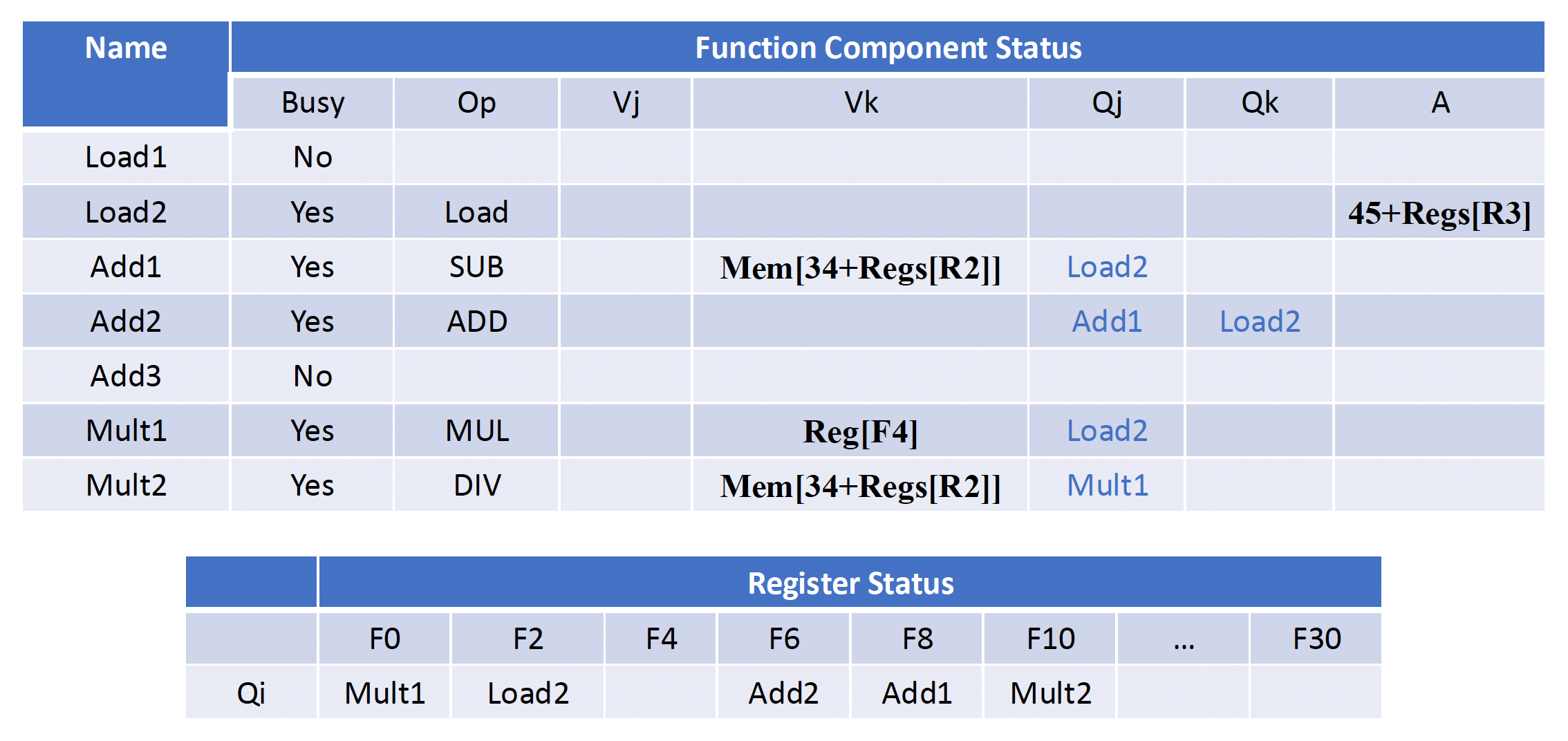
采用和例 1 相同的指令序列,展示当 fmul.d 指令准备写入结果时状态表的信息。

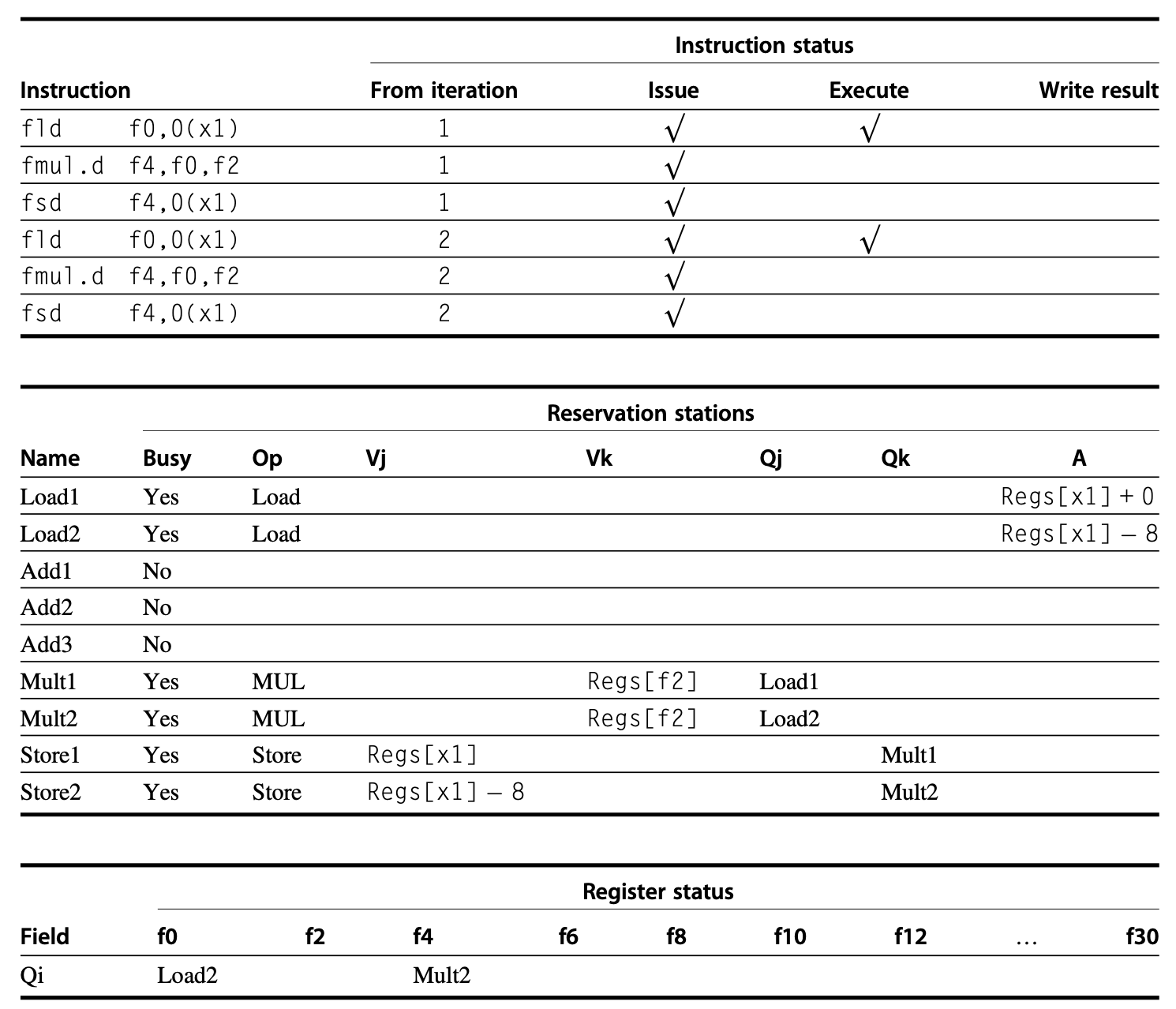
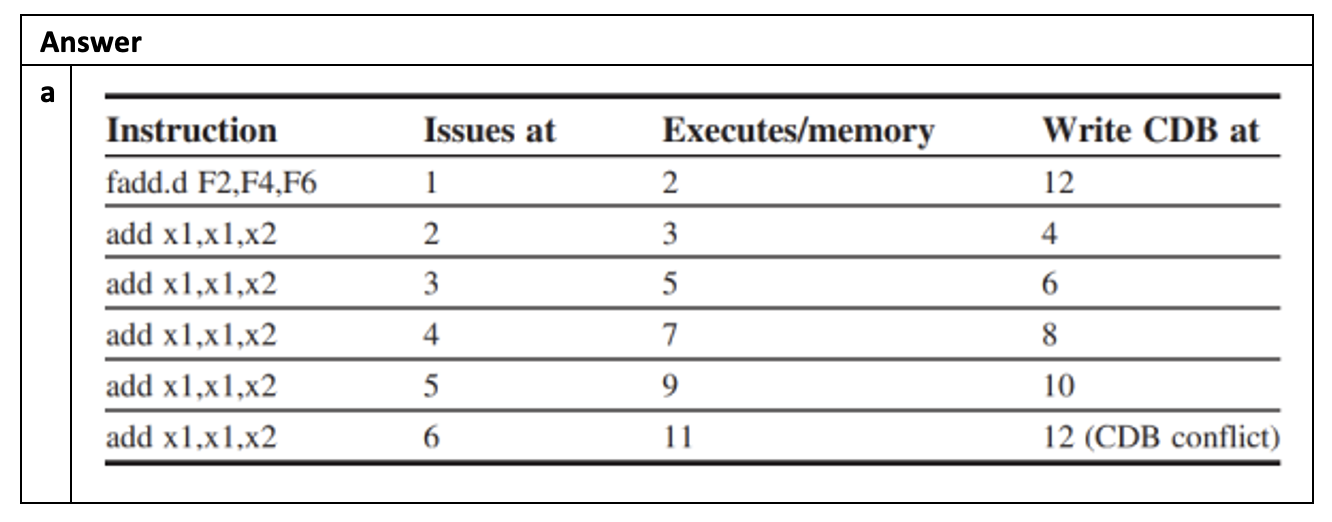
考虑下面的和循环相关的指令序列:
假设我们发射了两次连续迭代下的全部指令,但是没有运算是完成的,下图展示了此时的保留站、寄存器状态表以及加载和存储缓冲区内的信息:

托马苏洛算法的缺点
- 实现复杂,需要很多硬件:每个保留站必须包含一个关联的缓冲区,该缓冲区必须具备很快的运行速度以及复杂的控制逻辑。
-
性能还会受到 CDB 的限制:
- 每个 CDB 必须和保留站交互,并且对应要有用于复制关联标签匹配的硬件
- 每个时钟周期内能够完成的功能单元数被限制为 1 个!
-
如果访问不同地址的话,那么加载和存储就可以放心地被乱序执行,但如果访问相同地址的话,以下情况中的其中一种就会发生:
- 在程序顺序中,若加载在存储的前面,交换两者就会发生 WAR 冒险
- 在程序顺序中,若存储在加载的前面,交换两者就会发生 RAW 冒险
- 交换两个访问相同地址的存储指令会发生 WAW 冒险
为了检测这样的冒险,处理器必须计算和先前内存指令相关的数据内存地址。对于加载而言,先计算它的有效地址,如果发现和存储缓冲区中的任何一项匹配上的话,那就不要将这条加载指令送到加载缓冲区里,直到那条冲突的存储指令执行完毕。对存储的处理也是类似的,除了它要同时检查加载和存储缓冲区里的内容。
-
不精确的中断
- 只能实现基本块的部分重叠:在分支确定前,后续基本块无法开始执行(尽管可以被发射)
Hardware-Based Speculation⚓︎
当我们想要更大程度的 ILP 时,维持控制依赖将成为增长的负担。尽管前面介绍过的分支预测能够减小其带来的影响,但还是无法满足我们的需求,尤其是对多发射处理器。因此接下来将会介绍推测(speculation) 技术。使用推测后,处理器获取、发射并执行指令时,就好像分支预测始终是正确的一样;当然也需要有能够处理推测错误的机制。而本节基于动态调度扩展,带各位了解硬件推测(hardware speculation) 的原理。
硬件推测的三个关键思想为:
- 动态分支预测:用于选择需要执行的指令
- 推测:允许控制依赖前的指令得以执行(即具备撤销推测错误的指令序列的影响的能力)
- 动态调度:处理对不同基本块的调度
硬件推测遵循预测的数据值流来选择何时执行指令。这种执行程序的方法称为数据流执行(data execution):当操作数可用时,运算立即执行。
当指令不再是推测指令时,才允许该指令更新寄存器堆或内存,我们称这个步骤为指令提交(instruction commit)。
实现推测背后的关键思想是允许指令乱序执行,但强迫它们按顺序提交,以阻止任何不可更改的行为。所以在使用推测技术时,需要将完成执行的过程和指令提交分开来;并且需要额外的硬件缓冲区来保留已执行完毕的,但未提交的指令结果。这种缓冲区称为重排缓冲区(reorder buffer, ROB),逻辑上是一个 FIFO 的队列,而物理上是一块位于内存的缓冲区。由于 ROB 和存储缓冲区类似,所以之后就将存储缓冲区并到 ROB 里面了。
下图展示了实现推测技术后的,并采用托马苏洛算法的处理器的结构:
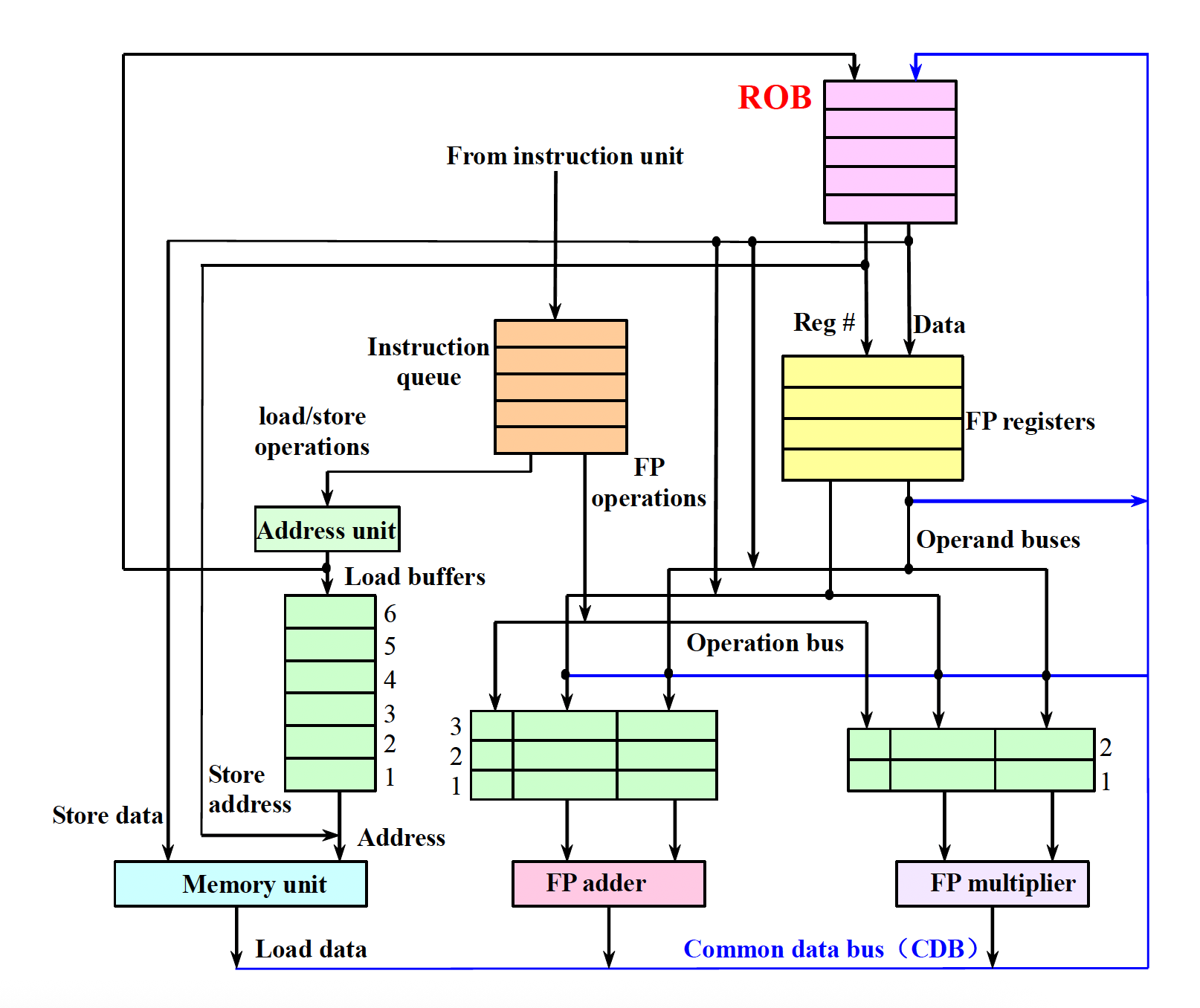
ROB 里的每一项包含了 4 个字段:
- 指令类型:表明该指令是分支指令(无目标结果
) ,存储指令(目标为内存地址) ,还是寄存器操作(ALU 运算和加载指令,目标为寄存器) - 目标字段:提供指令结果应该被写入的寄存器编号(ALU 运算和加载指令)或内存地址(存储指令)
- 值字段:保留指令结果的值,直到指令提交
- 准备字段:表明指令是否执行完毕,此时值已经准备好了
尽管保留站寄存器重命名的功能改由 ROB 负责,但保留站还会提供一个用于缓存从发射到开始执行前的操作。因为每条指令在提交前必须在 ROB 上有个位置,因此我们用 ROB 每项的编号来为结果打标签,而这个标签必须能被保留站追踪到。
现在,指令的执行分为四步:
- 发射:
- 从指令队列获取指令
- 若存在一个空的保留站以及一个空的 ROB 项,则发射该指令
- 如果操作数在寄存器或 ROB 上可用的话,那么将操作数也送到保留站内
- 更新控制项,表明缓冲区在使用了
- 为结果分配的 ROB 的项数也要送到保留站内,这样的话当结果被放在 CDB 上时,可以用这个数字来为该结果打标签
- 如果保留站或 ROB 满了,那么停止发射指令,直到有空余项为止
- 执行:
- 如果一个或多个操作数不可用的话,那么监控 CDB,等待操作数被计算出来
- 当某个操作的所有操作数都可用时,那就执行该操作
- 这一阶段可能需要多个时钟周期
- 写入结果:
- 当结果可用时,将其(以及 ROB 标签)写入 CDB,然后从 CDB 写到 ROB 以及其他等待该结果的保留站内
- 对于存储指令,如果存储值可用,那么将其写入到 ROB 项的值字段内;若不可用,那么监控 CDB 直到该值被广播
- 提交(commit):有以下三种情况
- 正常提交(当指令到达 ROB 头,且对应值在缓冲区内时
) :处理器用指令执行结果更新寄存器,并移除 ROB 内的指令 - 提交存储指令:和前一种情况类似,只是更新的东西变成了内存而非寄存器
- 错误预测的分支指令(即推测错误
) :清除 ROB 里的内容,重新开始分支指令后的正确指令(撤回)- 错误的预测对处理器性能影响很大,因此需要着重考虑处理分支的各方面,包括预测精度、误预测检测的时延和误预测恢复时间。
- 处理器仅在准备提交时才会识别并处理异常。如果推测指令发起异常,那么该异常会被记录到 ROB 里。如果发生了分支误预测且指令还没被执行,那么异常就会随 ROB 里的其他内容被清除掉。但如果指令已经进入到 ROB 头,那么我们知道该指令不再是可推测的,且异常真的发生了,此时应尽快处理异常。因此结合 ROB 的托马苏洛算法具备了精确中断的能力。
- 正常提交(当指令到达 ROB 头,且对应值在缓冲区内时
下面展示了推测处理器的具体运行步骤:

例子
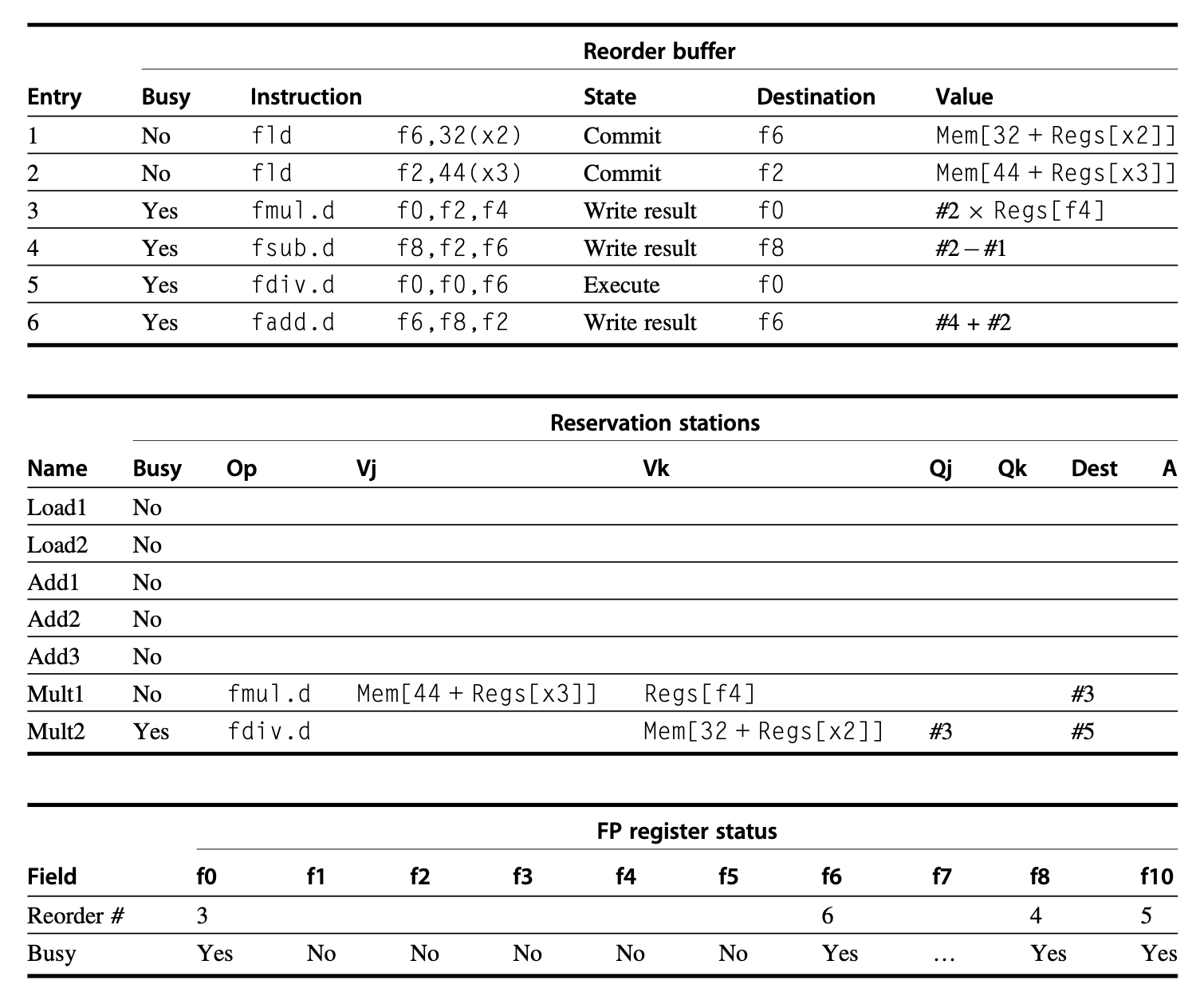
考虑在之前的例子中分析过的指令序列:
假设我们发射了两次连续迭代下的全部指令,且第一次迭代的 fld 和 fmul.d 指令已提交,且其他指令也已完成执行。此时的状态表如下所示:
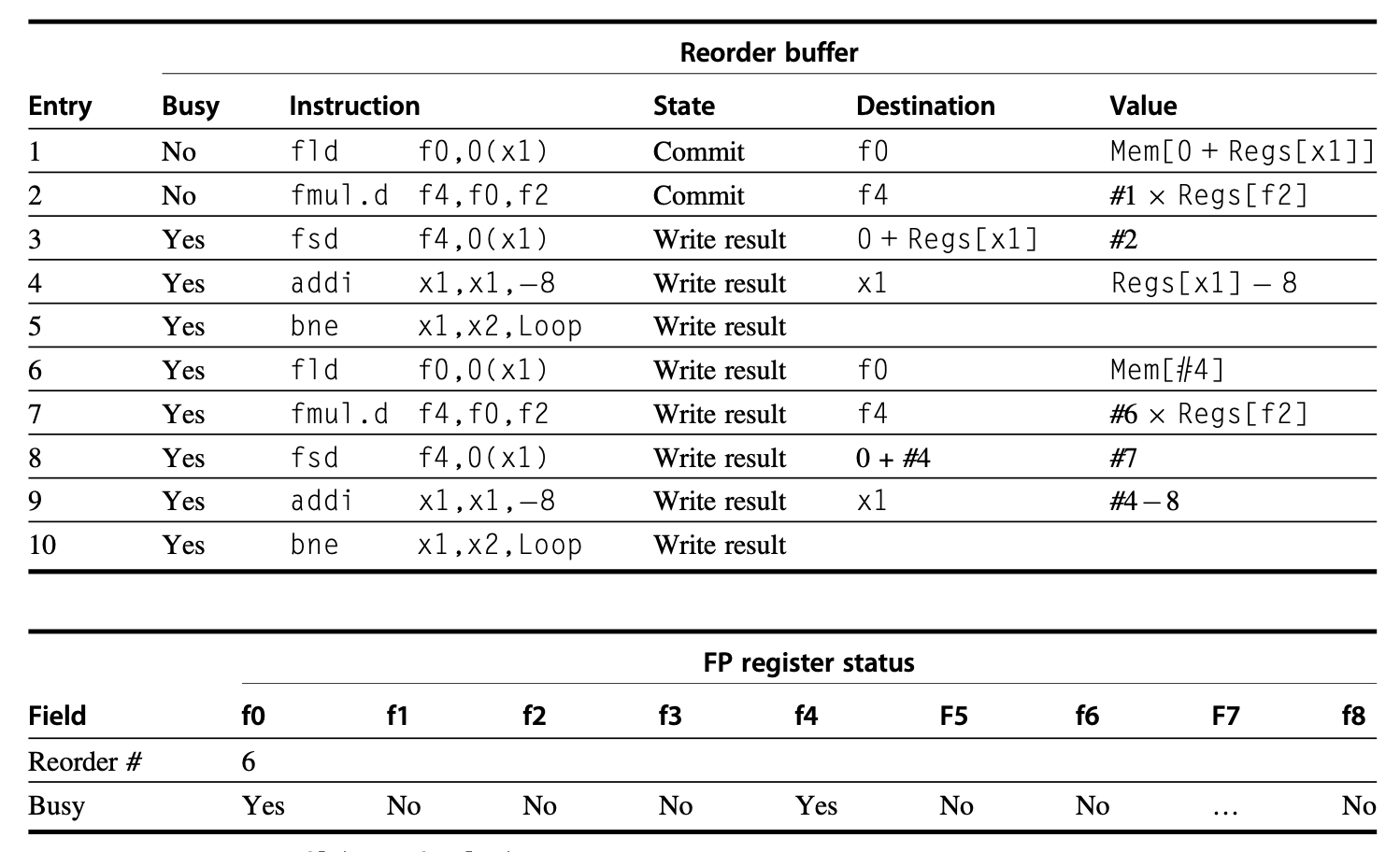

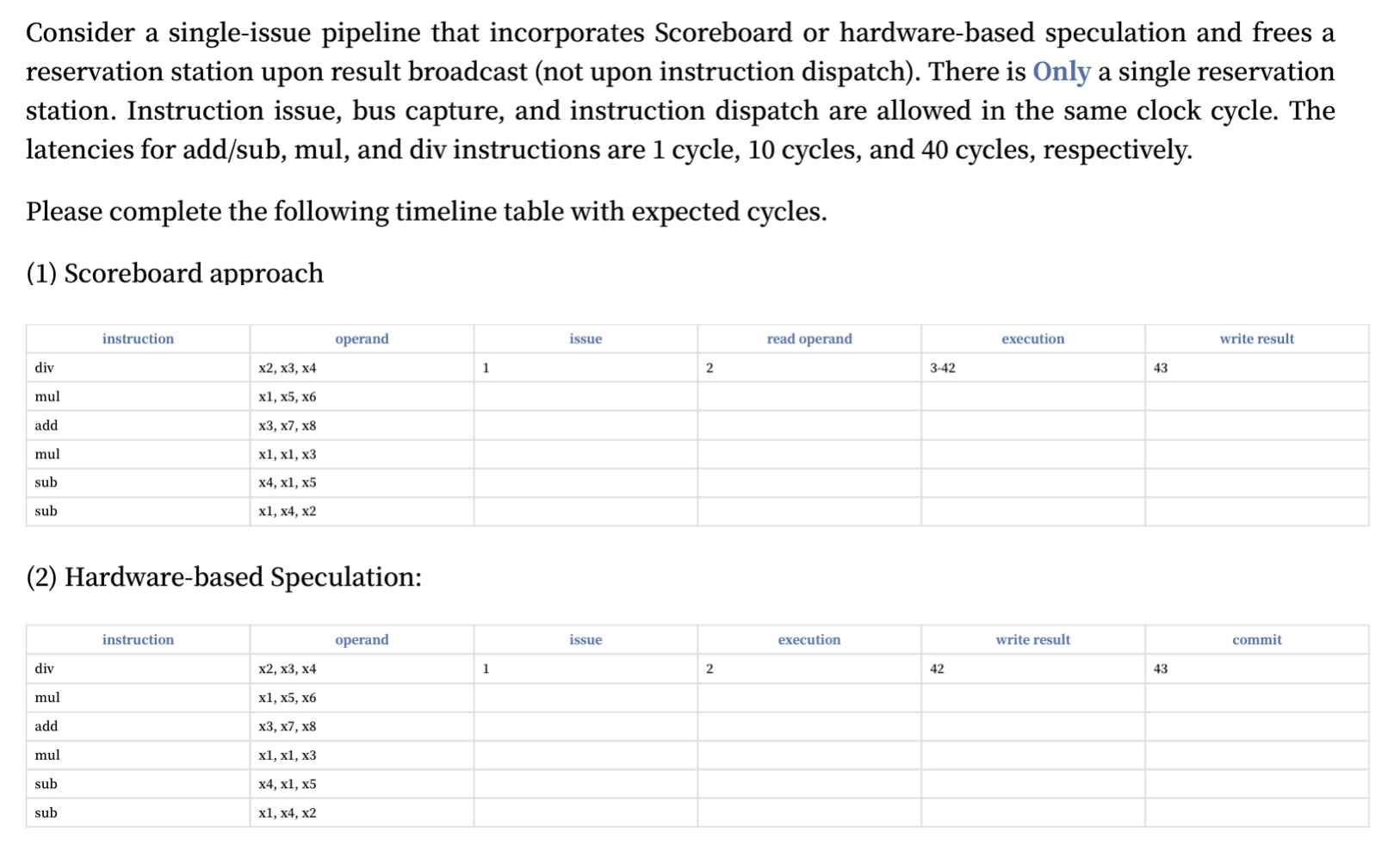
感觉题目怪怪的,反正我不太理解,答案也可能确实有些问题,请谨慎辨别。
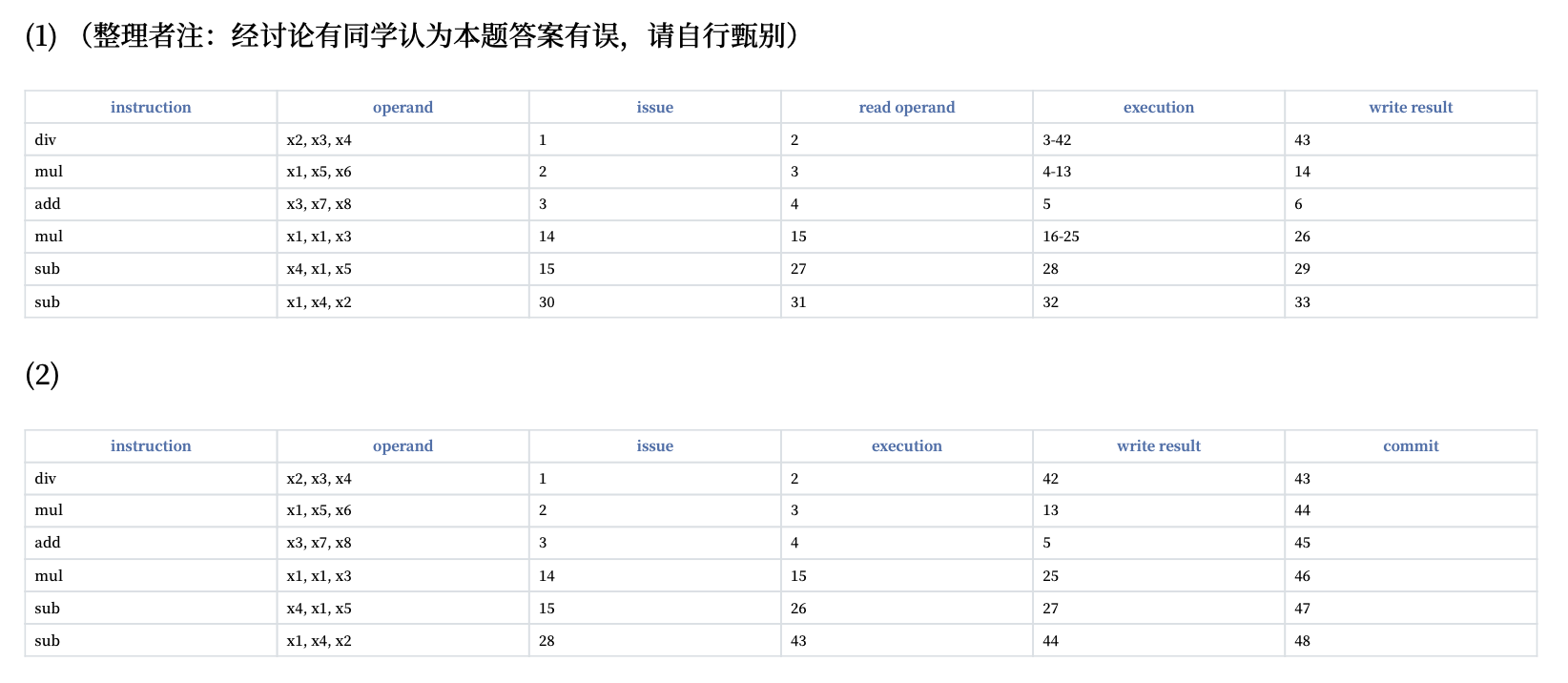
补充知识:内存消歧
如果存储指令后跟加载指令,那么可能存在 RAW 冒险的问题。所以,我们不能在知道存储地址和加载地址不冲突之前,就提前执行加载。
我们使用硬件支持的内存消歧来确定这一冲突是否存在:
- 需要一个缓冲区(ROB 就能起到这个作用)来跟踪所有未提交的存储指令(按程序顺序保存)
- 记录存储指令的地址和值(当它们可用时
) 。 - 按 FIFO 顺序提交存储指令。
- 记录存储指令的地址和值(当它们可用时
- 当发射加载指令时,记录当前存储指令队列的头部,以知道哪些存储指令在加载指令之前
- 当加载指令地址可用时,检查存储指令队列:
- 如果加载指令之前的任何存储指令正在等待其地址,则加载指令停顿
- 如果加载指令地址与之前的存储指令地址匹配(关联查找
) ,则存在内存 RAW 冒险- 如果存储指令需要的值可用,则返回该值
- 如果该值不可用,则返回 ROB 号作为源
- 否则,向内存发出请求
- 实际存储指令按序提交,因此无需担心 WAR/WAW 内存冒险
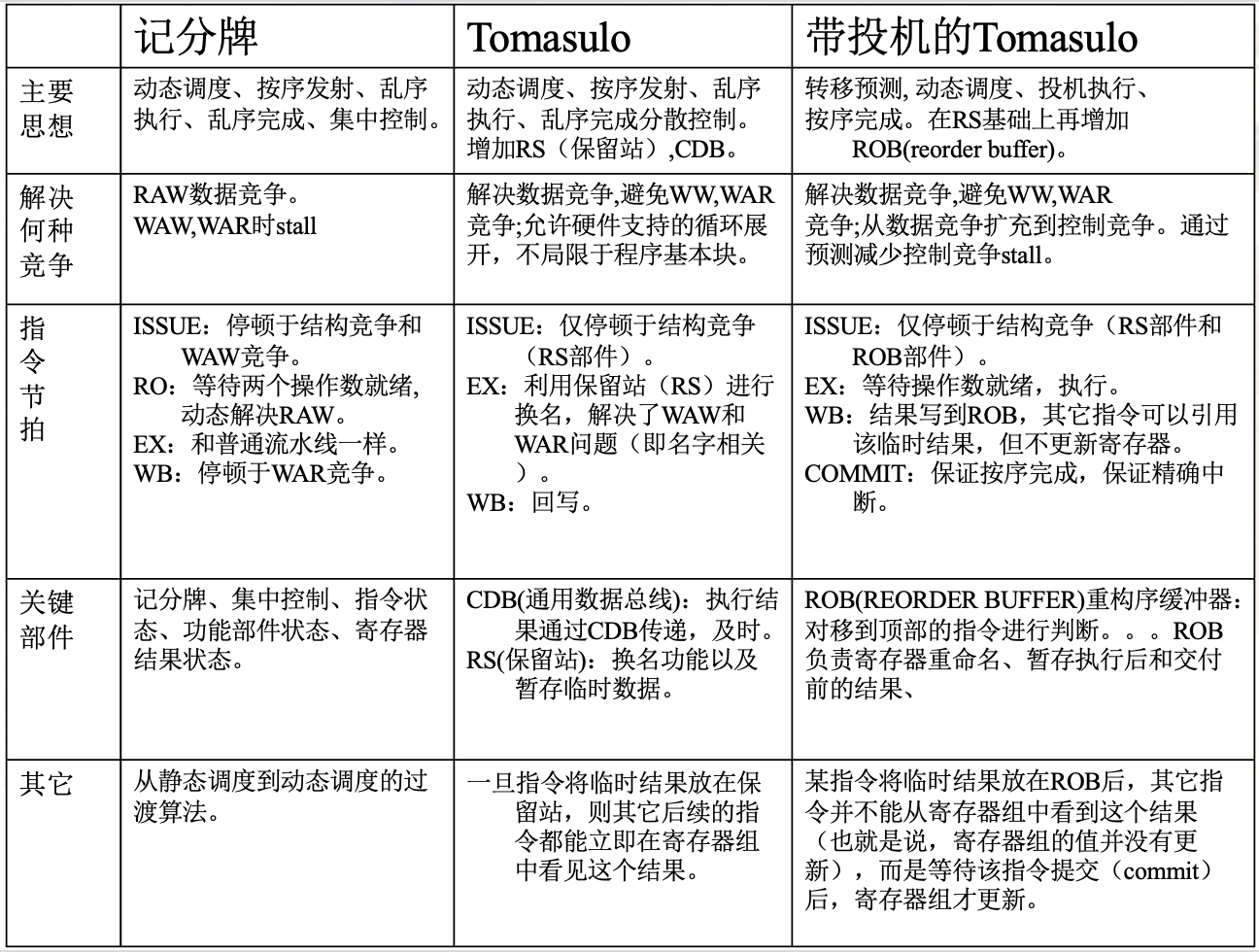
总结
Multiple Issue⚓︎
前面讲到的技术都是通过消除数据、控制停顿来提升 CPI 的。为了进一步提升性能,我们希望 CPI 降到 1 以下,这意味着需要在一个时钟周期内发射多条指令。所以本节我们就来讨论一下多发射处理器(multi-issue processor) 的设计,它包含以下几类:
- 静态调度超标量 (superscalar) 处理器
- VLIW(very long instruction word,超长指令字)处理器
- 动态调度超标量处理器
其中:
- 超标量处理器
- 在每个时钟周期内发射的指令数会变化
- 假设有一个最大上限 n,那么称这种处理器为 n 发射
- 既可用编译器实现静态调度,又可用托马苏洛算法实现动态调度
- 对于通用计算而言,该方法是目前最成功的方法
- VLIW 处理器
- 在每个时钟周期内发射固定量(4-16)的指令,并被格式化为一个大指令,或者一个固定的带有并行的指令包
- 在指令包内,指令间的并行会被显式表示
- 由编译器静态调度
- 它被成功用于数字信号处理和多媒体应用
下图比较了单发射以及各类多发射的示意图:
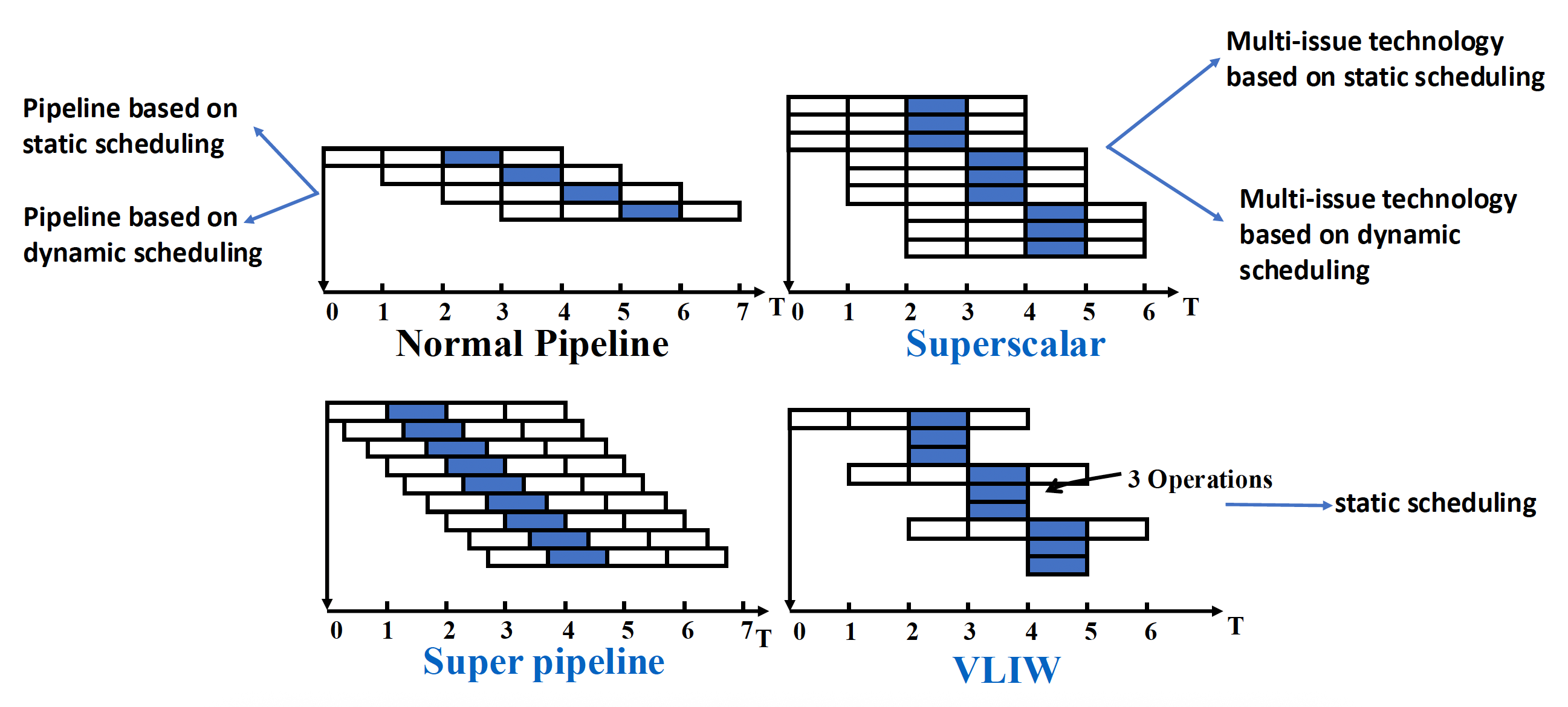
总结:5 类实现多发射处理器的基本方法
Using Static Scheduling⚓︎
先来考虑静态调度的超标量处理器:
- 在典型的超标量处理器中,每时钟周期可发射 1-8 条指令
-
指令按顺序流出,冲突检测(conflict detection) 便是在指令流出的时候进行的
- 在当前指令序列中没有数据冲突或闭冲突(close conflict)
-
例子:4 发射的静态调度超标量处理器
- 在 IF 阶段,处理器会接收 1-4 个来自取指元件的指令
- 在 1 个时钟周期内,有可能所有指令都可以流出,也有可能只流出部分指令
-
外发元件 (ongoing component) 会检测结构冲突和数据冲突,通常分为 2 个阶段实现
- 阶段 1:在外发包 (outgoing package) 内执行冲突检测,选择那些能首先流出的指令
- 阶段 2:检查这些被选中的指令是否和正在执行的指令冲突
-
RISC-V 实现超标量的方法:
- 假设每时钟周期流出 2 条指令(64 bits
) :1 条整数指令 + 1 条浮点数指令- 这样的并行使得硬件的增加量不那么大
- 加载、存储、分支指令都属于整数指令
- 还假设浮点数指令的执行需要 2 个时钟周期
- 浮点数加载和存储指令会用到整数部分的硬件,这样会增加浮点数寄存器的访问冲突;缓解方法是增加浮点数寄存器的读 / 写端口
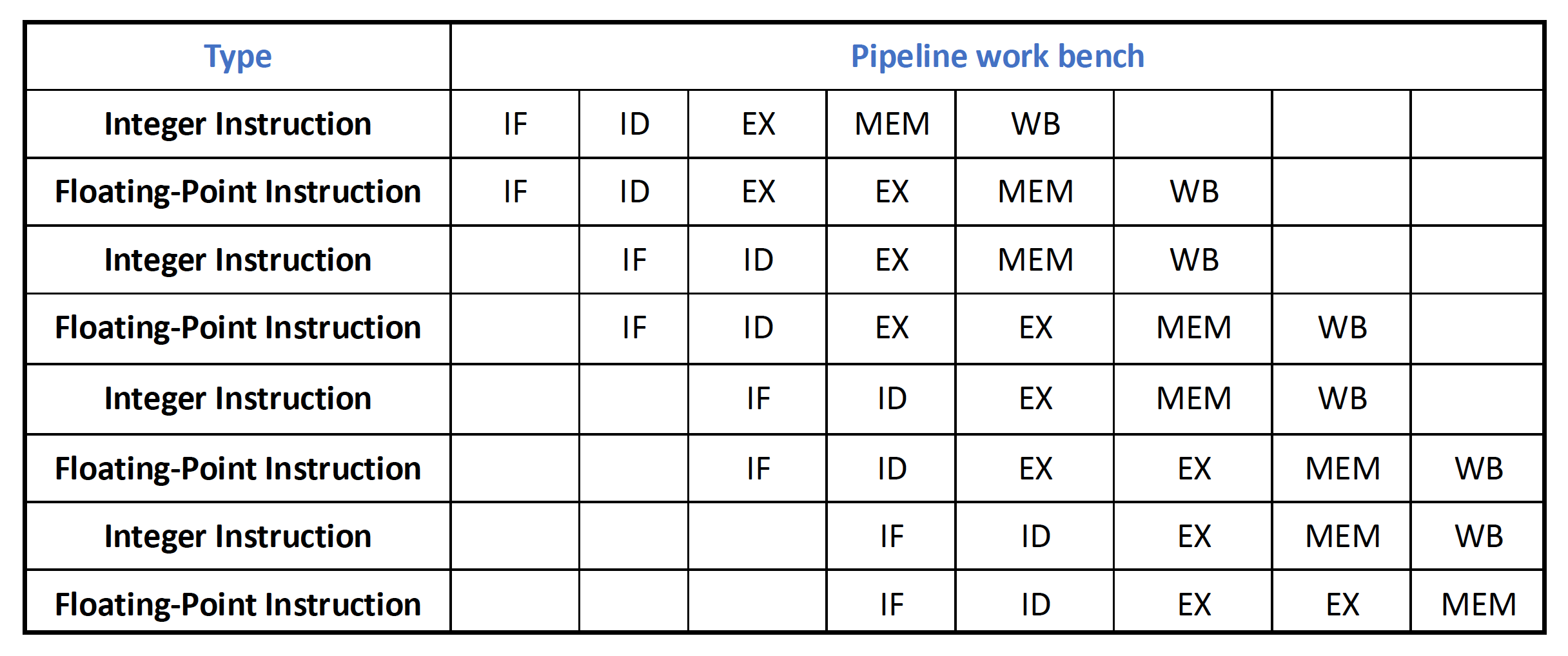
- 假设每时钟周期流出 2 条指令(64 bits
再来看 VLIW
- 采用多个独立的功能单元,将多个运算打包成一个非常长的指令,或者让指令包里的指令满足相同的约束
- 由于这两种方法没有本质区别,所以下面仅考虑前者
- 指令字被划分为多个字段,这些字段被称为运算槽(operation slot),它们能直接且独立地控制一个功能单元
- 所有的处理和指令排布都是由编译器完成的
- 由于 VLIW 的优势随着发射率的提升而增加,因此我们考虑更宽发射的处理器
为了让功能单元保持工作状态,需要让代码有足够多的并行,这点可通过前面介绍过的循环展开和代码调度来实现。如果展开得到的是直线代码(没有跳转
例子
假设我们有一个满足上述假设的 VLIW 处理器,请展示该处理器对循环 x[i] += s 进行展开后的结果。

VLIW 模型存在一些技术上和逻辑上的问题
- 技术问题:
- 代码规模的增加,有以下解决方案:
- 软件调度可通过大量的循环展开来提升并行
- 采取更聪明的编码方式
- 压缩内存里的指令,当需要将指令读到高速缓存时再解压
- 锁步(lockstep) 操作的局限:任何功能单元流水线的停顿会导致整个处理器的停顿,因为所有的功能单元必须保持同步
- 最新的处理器中,功能单元的运作更加独立,且编译器用于在发射时避免冒险,而硬件检查允许指令的不同步执行
- 代码规模的增加,有以下解决方案:
- 逻辑问题:二进制代码的兼容性不足,这使得在不同实现之间的迁移变得困难
- 在严格的 VLIW 方法中,代码序列同时利用到指令集定义和详细的流水线结构(包括功能单元及其时延
) ,所以不同的功能单元以及时延需要不同版本的代码
- 在严格的 VLIW 方法中,代码序列同时利用到指令集定义和详细的流水线结构(包括功能单元及其时延
Using Dynamic Scheduling and Speculation⚓︎
现在我们将动态调度、多发射和推测这三项技术结合起来,就可以得到一个和现代微处理器很像的微架构。为了便于后续讨论,我们仅考虑每时钟周期内发射两条指令的发射率。下图展示了带推测的多发射处理器的基本组织:
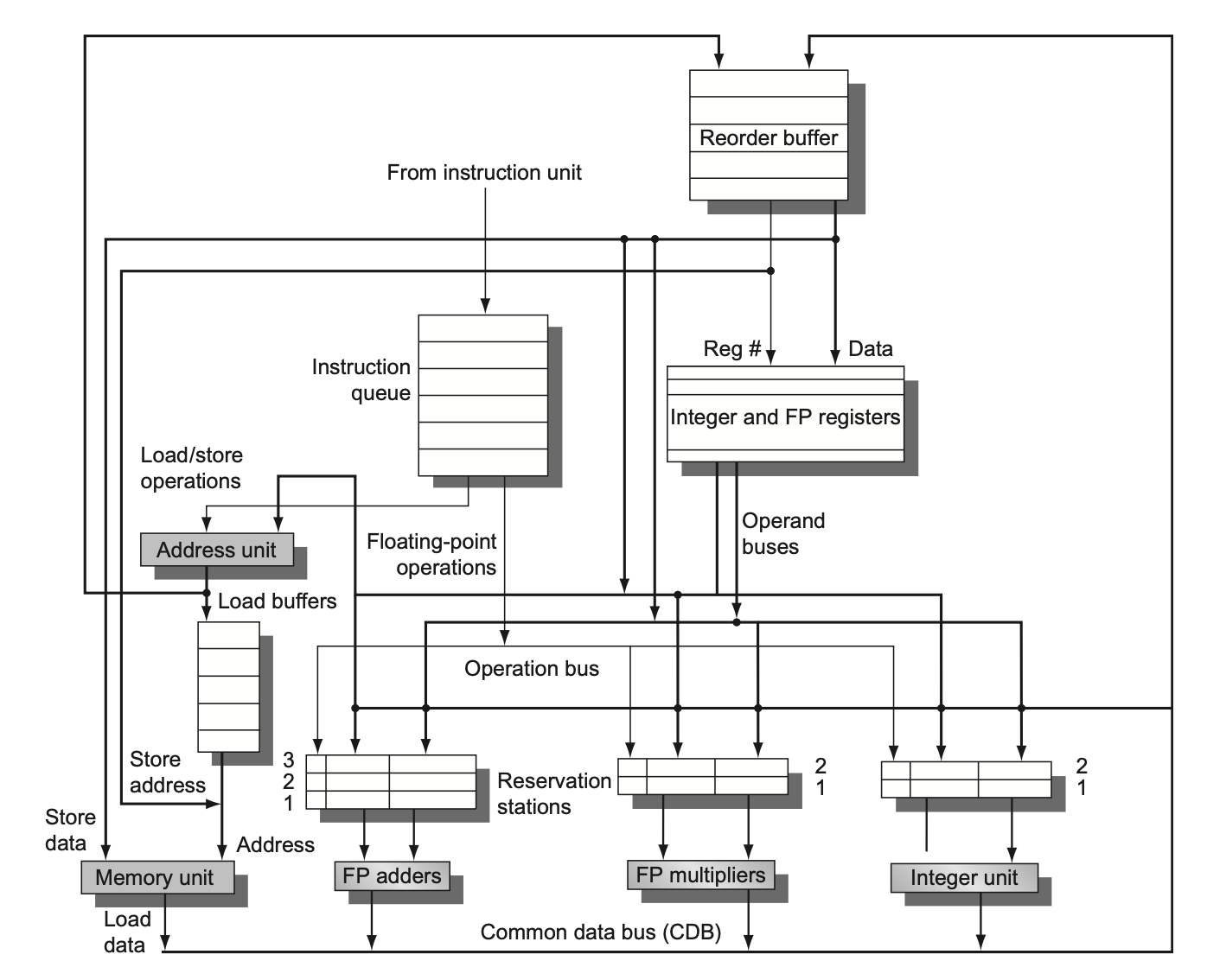
和之前的组织图的区别就是某些线路加粗了,用于支持多发射;元件没有任何变化。
在动态调度的处理器中,同一时钟周期内发射多条指令是很复杂的,一个很简单的原因是:多条发射的指令之间可能存在依赖关系。所以必须要为并行的指令更新流水线控制表,否则的话表格的内容就不对了或者依赖可能丢失了。
有两种不同的实现方法,但都是基于同一个观察:关键在于分配保留站和更新流水线表(pipeline tables)。
- 让上述步骤在半个时钟周期内完成,这样两条指令就能在一个时钟周期内被处理好
- 但这种方法很难扩展到更多的指令发射
- 建立立即处理两条或多条指令(包括指令间任何可能的依赖)的必要逻辑
在动态调度超标量处理器中,发射步骤是其中最基本的瓶颈之一,下面展示了发射的具体逻辑:

我们可以泛化上述细节,得到每时钟周期发射 n 条指令的基本策略:
- 为每个可能在下一个发射包中指令分配一个保留站和重排缓冲区。这一步可以在指令类型被确定前完成,具体来说可以用 n 个可用的 ROB 项按顺序为指令包里的指令预分配空间,并确保有足够多可用的保留站来发射整个包
- 分析发射包内所有指令的依赖关系
- 如果发射包内的某条指令依赖于发射包内前面的指令,那么使用被分配的 ROB 编码来更新依赖指令的保留站。否则的话就使用现有的保留站和 ROB 来更新正在发射的指令的保留站
而上述过程仅需一个时钟周期就能完成,因此相当复杂。
例子
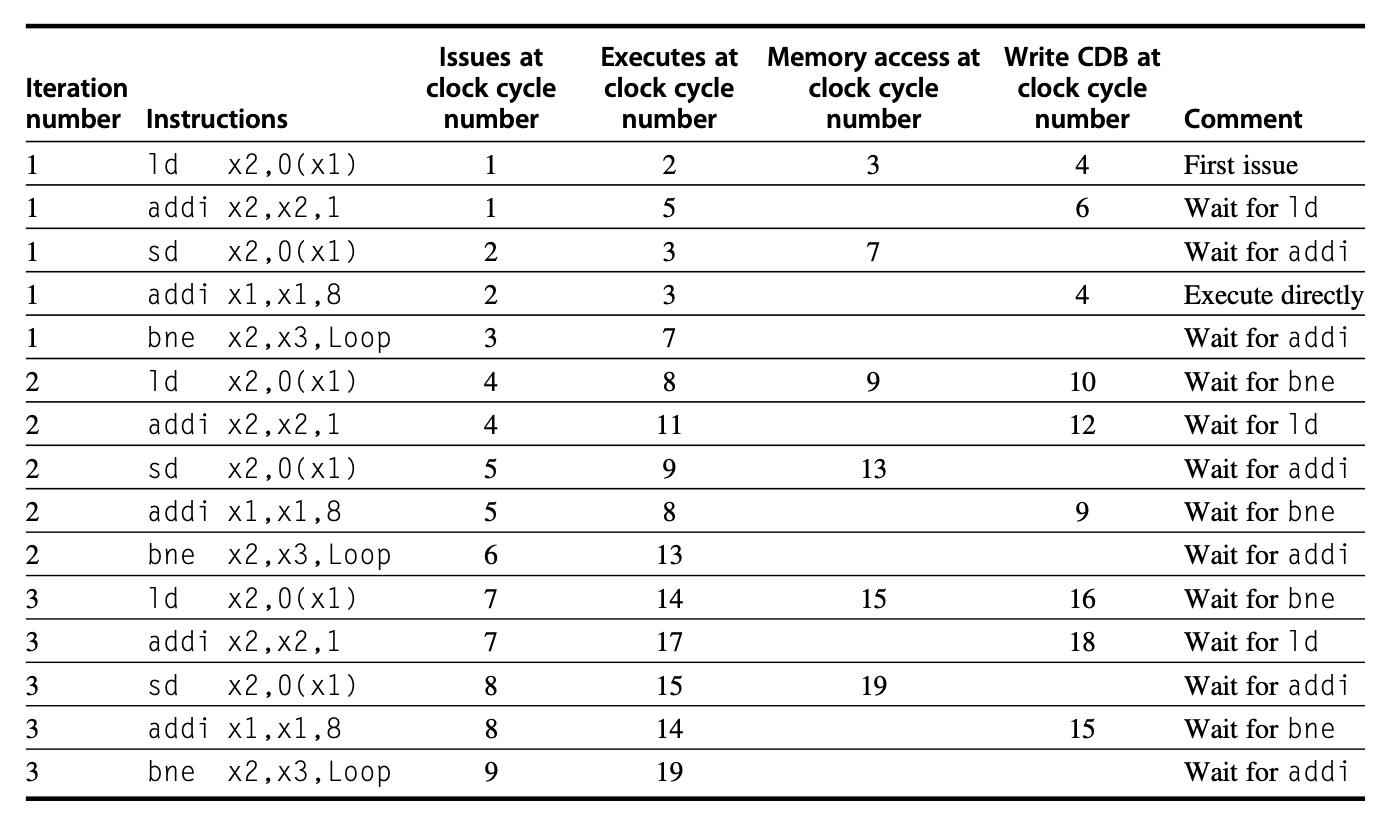
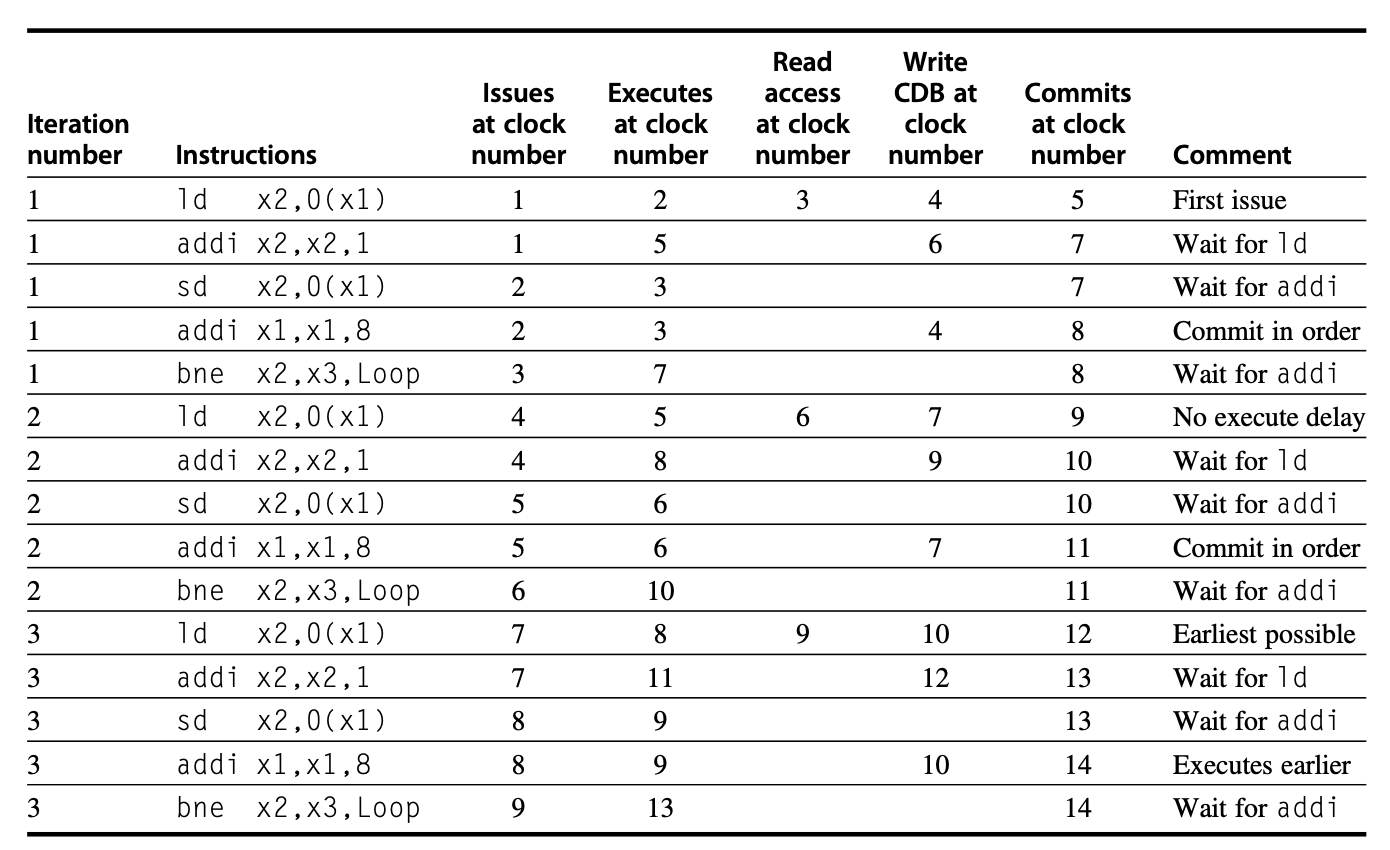

Figure 3.10 就是“使用托马苏洛算法的浮点数单元的基本结构”那张图
Advanced Techniques for Instruction Delivery and Speculation⚓︎
Increasing Instruction Fetch Bandwidth⚓︎
在高性能的流水线中,尤其是在多发射的情况下,仅靠分支预测还是不透的,还要能够传递一个高带宽的指令流(在最近的处理器中,每个时钟周期内需要传递 4-8 条指令
Branch-Target Buffers⚓︎
如果某条指令是一个分支指令,且我们已经知道下一个 PC 值了,那么分支的损失就减为 0 了。我们称用于存储分支后下一条指令的预测地址的分支预测缓存为分支 - 目标缓冲区(branch-target buffers),其大致结构如下所示:
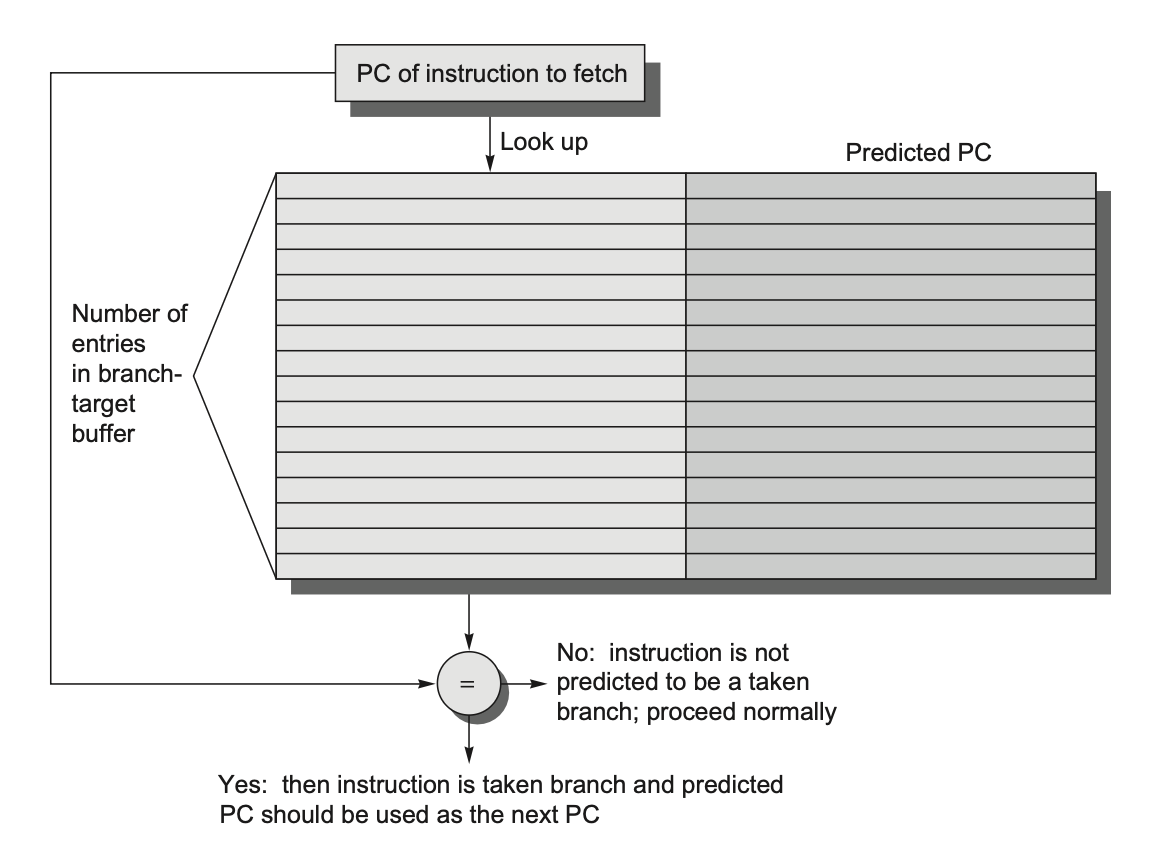
由于分支 - 目标缓冲区预测了下一条指令的地址,并且在译码指令前需要将其发送出去,因此我们必须知道取得的指令是否被预测为一个要跳转的分支。如果取得的指令的 PC 值和预测缓冲区的地址匹配上的话,那么对应的被预测的 PC 被用作下一个 PC。此外,我们仅需在分支 - 目标缓冲区内存储预测要跳转的分支就行了,因为不跳转的分支应该只获取下一条顺序指令就行了。
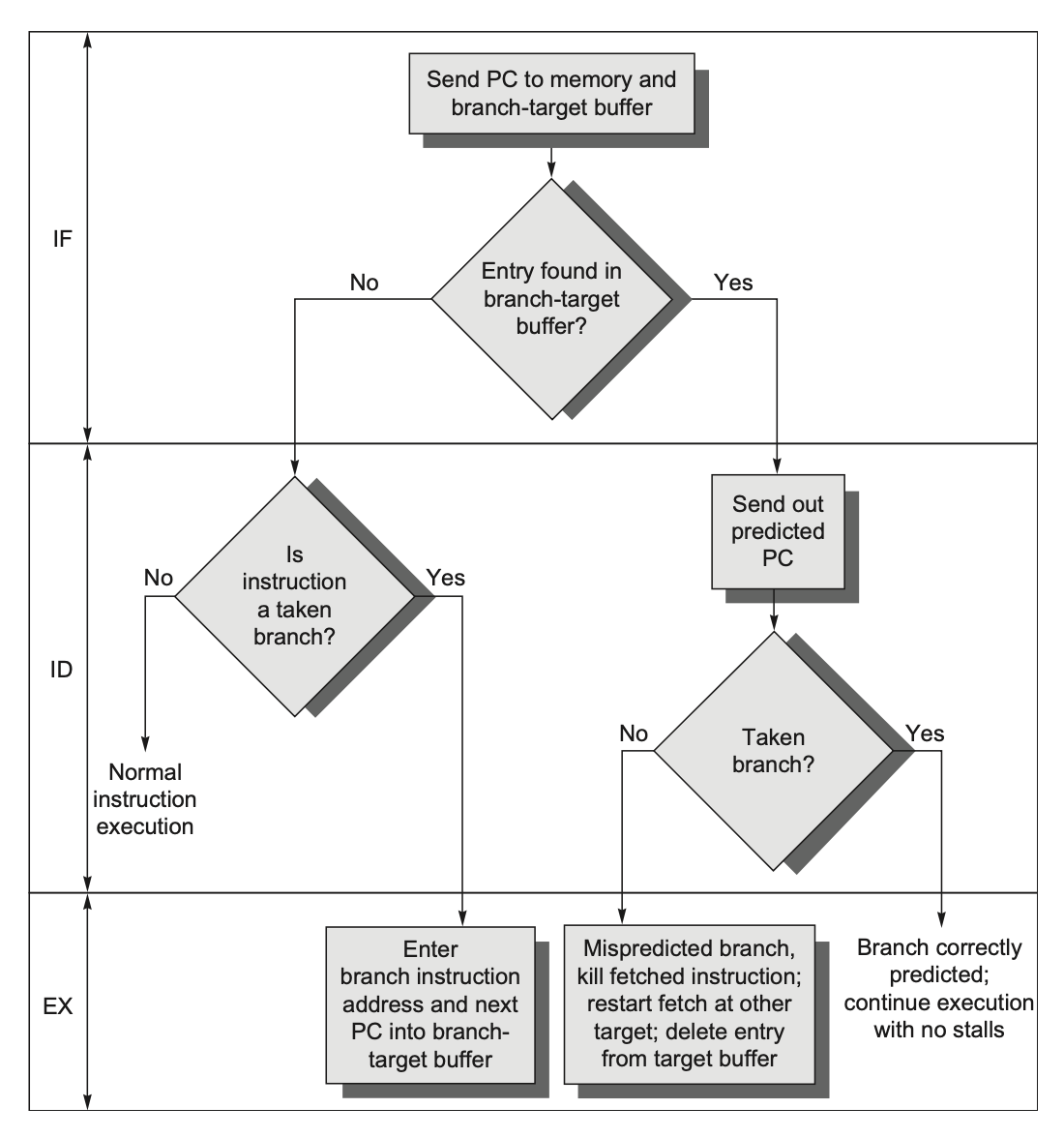
下面展示了分支 - 目标缓冲区在处理指令时的步骤:
而下表展示了分支预测时的各种情况:
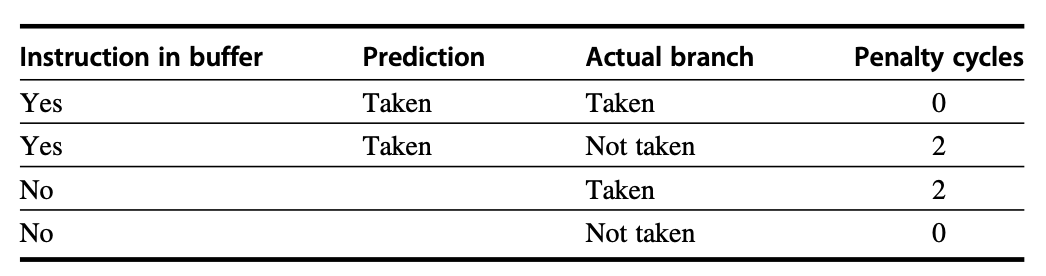
例子
确定分支 - 目标缓冲区的总的分支损失,假设损失情况同上表,并且遵循以下假设:
- 预测精度为 90%(缓冲区内的指令)
- 缓冲区的命中率为 90%(预测分支跳转)

Specialized Branch Predictors⚓︎
我们面对的下一个挑战是预测间接跳转(indirect jump),即目标地址在运行时变化的跳转。使用高级语言编写的程序会生成这种跳转,以进行间接的过程调用和 case 语句中。尽管过程返回能够用分支 - 目标缓冲区预测,但如果过程被多处调用,且一处地方的调用可能发生在不同的时间内,那么预测的精度就很低了。
为了克服这种问题,一些设计会采用一块较小的返回地址缓冲区,在栈上进行操作。这个结构会为最近的返回地址缓存,当调用过程时将返回地址压入栈内,返回时则将其弹出。如果这个缓存足够大的话,那么它能够完美预测返回地址。下图展示了不同大小的返回缓冲区下的性能:
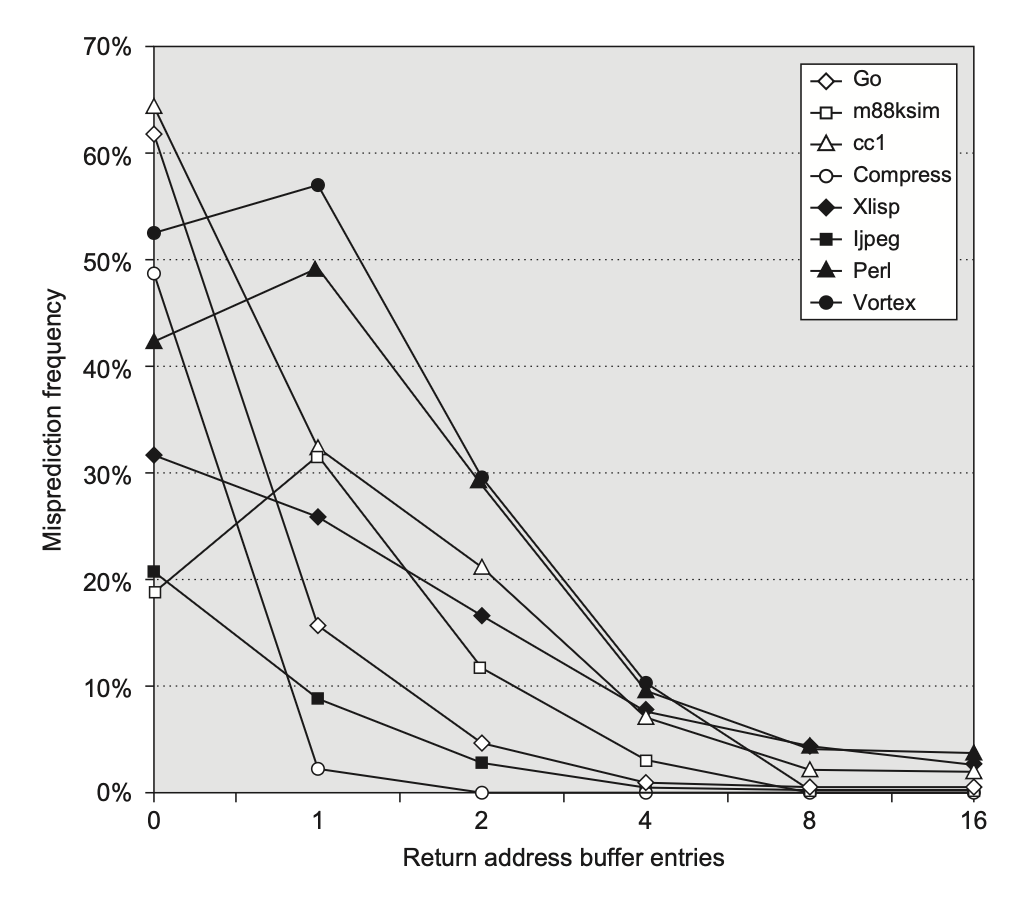
在大型服务器应用中,间接跳转也可能来自各种函数调用和控制传输,而预测这样的分支目标可不像过程返回那么简单,因此一些处理器会选择增加专门的预测器来实现所有的间接跳转。
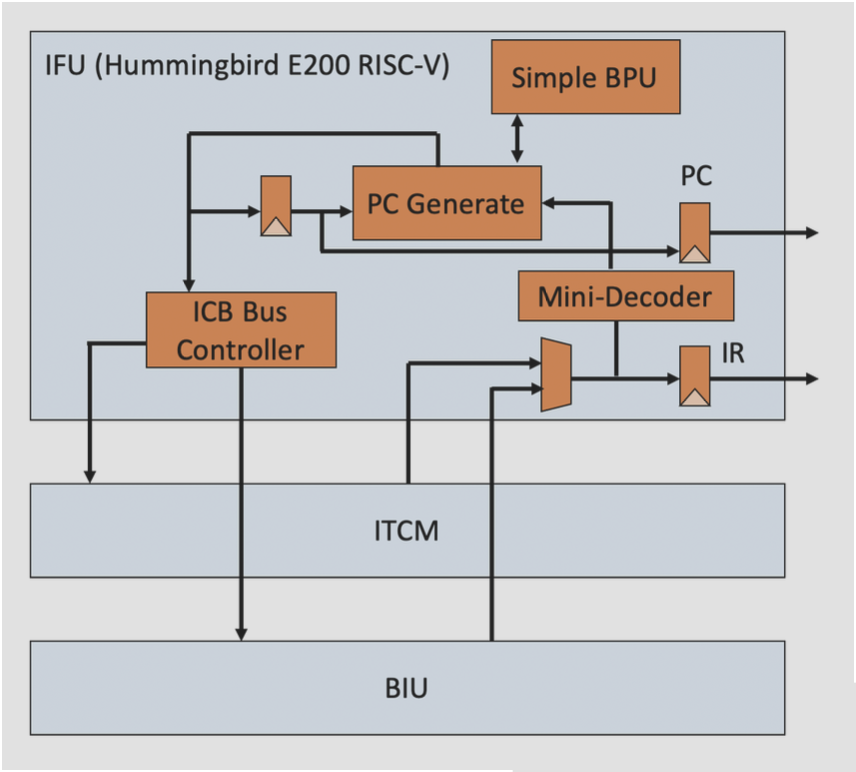
为了满足多发射处理器的需求,很多设计者选择实现一种集成指令获取单元(integrated instruction fetch units),作为向流水线提供指令的单独的自动单元。该单元会集成以下功能:
- 集成分支预测:分支预测器会作为指令获取单元的一部分,并持续预测分支,以驱动流水线的 IF 阶段
- 集成预获取:为了在单个时钟周期内传递多条指令,指令获取单元可能需要提前获取指令。该单元会自动管理指令预获取,将其集成到分支预测中
- 指令内存访问和缓冲区:指令获取单元通过预获取来隐藏高速缓存块交叉(
? )带来的成本。此外该单元还提供了缓冲区,用于为发射阶段提供指令
Implementation Issues and Extensions of Speculation⚓︎
Speculation Support: Register Renaming v.s. Reorder Buffers⚓︎
一种替代 ROB 的方案是使用一组更大规模的寄存器组,并结合寄存器重命名技术,该方法还建立在托马苏洛算法的基础上。在托马苏洛算法中,在执行的任意时间点上,架构可见的寄存器(architecturally visible registers) 的值被包含在寄存器组和保留站内。如果使用推测技术的话,那么寄存器之可能还会临时位于 ROB 内。
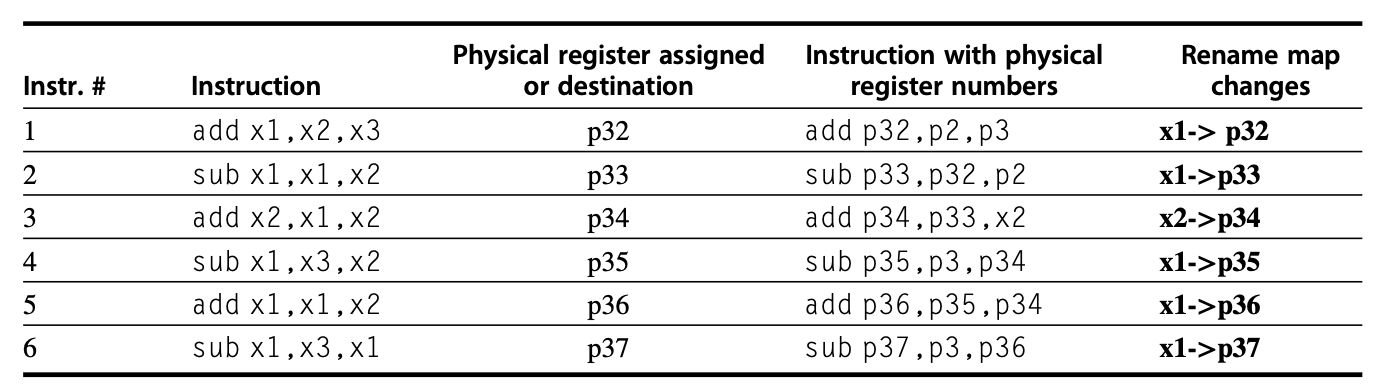
在指令发射的过程中,重命名进程会将架构寄存器的名称映射到物理寄存器的编号上,为其分配一个新的未使用的寄存器作为目标。通过该方法,WAW 和 WAR 冒险能够被避免,且推测恢复也能够被处理,因为保存指令目标的物理寄存器在指令提交前,尚未成为架构寄存器。重命名映射(renaming map) 是一种简单的数据结构,提供了与指定架构寄存器当前对应的物理寄存器编号,这是由托马苏洛算法中寄存器状态表执行的功能。
相比 ROB 方法,重命名方法的优势在于它稍微简化了指令的提交,因为它记录了架构寄存器编号和物理寄存器编号之间的不再是推测的映射关系,并且释放了存储架构寄存器旧值的物理寄存器。但是寄存器重命名让释放寄存器变得更复杂——物理寄存器对应一个架构寄存器,直到架构寄存器被重写,而这会导致重命名表指向任何地方。所以如果物理寄存器并不作为源,且没有被分配到对应的架构寄存器,那么该寄存器需要被重新声明和分配。而更简单的做法是让处理器等待其他指令写入相同的架构寄存器提交,这种做法为最近的大多数超标量处理器使用。
虽然架构处理器在一直变化,但大多数情况下我们无需担心这个问题。但像操作系统这样的进程则必须知道特定架构寄存器内的东西。
通过寄存器重命名实现指令多发射和通过 ROB 实现指令多发射的方法类似:
- 发射逻辑需要保留足够多的物理寄存器,用于完整的发射包。
- 发射逻辑需要确定发射包内存在的依赖关系。如果依赖关系不存在的话,那么寄存器重命名结构用于确定物理寄存器,保存现在或将来指令依赖结果。当发射包内不存在依赖关系时,来自先前发射包内的结果以及寄存器重命名表就会有正确的寄存器编号。
- 如果一条指令依赖于包内先于该指令的某条指令,那么需要用一个预保留的寄存器来更新该发射指令的信息。
The Challenge of More Issues per Clock⚓︎
只有当采用了精确的分支预测和推测时,我们才会考虑增大发射率,否则的话会因为要解决分支问题而很难扩大发射率。而增大发射率会使发射阶段以及提交阶段(实际上是发射的对偶)更加复杂。下面展示了在一个时钟周期内发射 6 条指令的情况:
在一个时钟周期内,这些指令的依赖关系必须被检测出来,必须为其赋予物理寄存器,并且指令必须用物理寄存器编码被重写。不难看出,这里的工作量可不小,这也就是为什么在过去几十年里发射率的提升十分缓慢。
How Much to Speculate⚓︎
推测带来的一大好处是能够隐藏那些导致流水线停顿的事件,比如高速缓存失效。但推测的缺点是消耗时间和能量,并且错误推测的恢复会降低性能。另外,为了从推测中获取更高的指令执行率,处理器必须有额外的资源,这就需要更多的芯片面积和电源。最后,如果推测导致异常发生的话(而且不用推测就不会发生异常
为了维持推测的优势,大多数带推测的流水线仅允许低成本的异常事件在推测模式下被处理,如果发生了高成本的异常事件,那么处理器会一直等待,直到在处理事件前,导致事件发生的指令不再是推测出来的为止。尽管这会降低某些某些程序的性能,但它避免了在其他程序上的显著的性能损失。
Speculating Through Multiple Branches⚓︎
同时在多条分支上推测会为以下情况带来好处:
- 非常高的分支频率
- 显著的分支集群
- 功能单元的长时延
Challenge of Energy Efficiency⚓︎
相信大多数人的第一感觉是:使用推测会降低能效 (energy efficiency),因为如果推测错误的话,它就会通过以下方式来消耗过多的能量:
- 推测出来的指令结果没有用,处理器做了无用功,浪费能量
- 撤销推测,恢复处理器到继续执行合适地址上的指令,这会消耗额外的能量
然而,如果推测降低的执行时间能够超过它带来的平均功耗的话,那么总的能量消耗反而是降低的。
Address Aliasing Prediction⚓︎
地址别名预测(address aliasing prediction) 是一种用于预测两条存储指令,或者一条存储指令和一条加载指令是否访问的是相同的地址的技术。如果访问的是不同的地址,那么两者可以安全地交换;否则的话指令就必须按顺序访问内存地址(期间可能需要等待一些时间
地址别名预测还是值预测(value prediction) 的一种简单而限制的形式,它尝试预测指令生成的值,如果足够准确的话,就能够消除数据流限制,以达到更高的 ILP 率。
Cross-Cutting Issues⚓︎
Hardware v.s. Software Speculation⚓︎
下面来比较硬件推测和软件推测之间的优劣:
- 为了扩展推测,推测必须有消除内存访问歧义的能力。在基于硬件的方法中,这种能力在编译时很难实现;但是通过硬件,能够在运行时动态实现,可以在运行时将加载指令移到存储指令前面。如果该方法使用不当的话,恢复的开销反而会盖过带来的好处。
- 对于大多数整数程序而言,基于硬件的推测在控制流不可预测时,以及基于硬件的分支预测先于基于软件的分支预测完成时表现更好。
- 基于硬件的推测能够维护一个完全精确的异常模型,即便对于推测指令而言也是如此。最近基于软件的方法也能做到这一点。
- 基于编译器的方法具备能够观察更长的代码序列的能力,从而可能得到比纯用硬件实现更好的代码调度。
- 基于硬件且没有动态调度的推测不要求不同的代码序列对同一架构上的不同实现取得良好的性能表现(?看不懂)
- 基于硬件的推测的主要缺点还是过于复杂,需要额外的硬件资源
有些设计者会尝试将这两种方法结合起来,但有时反而会造成不太好的结果。
Speculative Execution and the Memory System⚓︎
支持推测执行和条件指令的寄存器可能会产生非法的地址,从而影响到处理器的性能,这在没有推测执行的处理器中是不会发生的。因此,内存系统必须识别出推测执行的指令和条件执行的指令,镇压住对应的异常。而且,我们不能让这样的指令导致高速缓存的停顿或失效,因此处理器必须和非阻塞的高速缓存匹配。
Multithreading: Exploiting Thread-Level Parallelism to Improve Uniprocessor Throughput⚓︎
注
这里主要介绍的是单处理器上的多线程。若想了解多处理器上的多线程,请前往第 5 章。
多线程 (multithreading)技术是一种利用线程级并行 (thread-level parallelism, TLP),通过隐藏并行性来提高吞吐量的方法。它实际上是一项跨领域的技术,与流水线、超标量、GPU 和多处理器都有关联。
一个线程(thread) 就像一个进程,有自己的状态和 PC,但多个线程共享同一个进程的地址空间,因而可以轻松访问其他线程的数据。所以多线程允许单个处理器在不进行进程切换的情况下,通过快速切换线程来隐藏流水线和内存延迟。
下面介绍一些主要的硬件多线程方法:
-
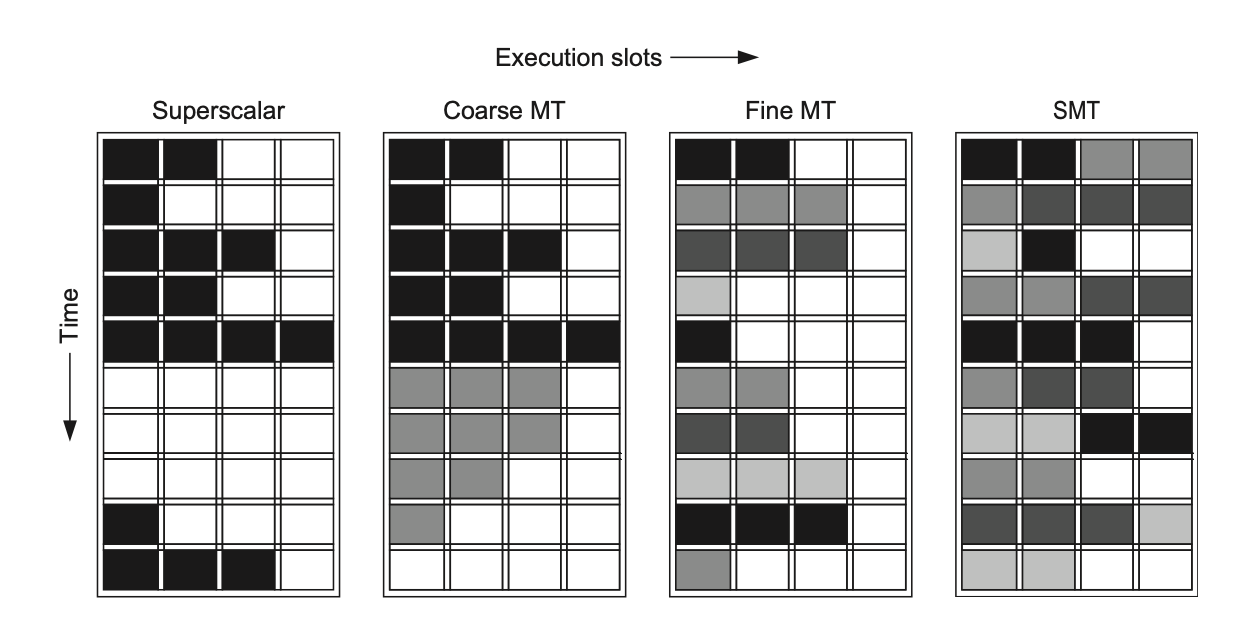
细粒度多线程(fine-grained multithreading):
- 在每个时钟周期在线程之间切换,交错执行来自多个线程的指令
- 通常采用轮询(round-robin) 方式,跳过任何停顿的线程
- 优点:可以隐藏短停顿和长停顿造成的吞吐量损失,因为当一个线程停顿时,可以执行来自其他线程的指令
- 缺点:会减慢单个线程的执行速度,因为即使一个线程准备好执行而没有停顿,其指令的执行也会被其他线程的指令延迟
-
粗粒度多线程(coarse-grained multithreading)
- 作为细粒度多线程的替代方案
- 只有当一个线程遇到高成本停顿(如二级或三级缓存缺失)时,才会切换到另一个线程
- 优点:避免了频繁的线程切换开销,并且在不减慢任何一个线程执行速度的情况下,隐藏了长延迟事件
- 缺点:
- 受限于其克服吞吐量损失的能力,特别是对于较短的停顿
- 由于流水线启动成本,当一个线程停顿并切换到新线程时,流水线可能会有一段空闲时间
-
同时多线程(simultaneous multithreading, SMT)
- 最常见的实现方式
- 是细粒度多线程的一种变体,它在多发射、动态调度处理器上实现时自然产生
- SMT 利用线程级并行来隐藏处理器中长延迟事件,从而增加功能单元的利用率
- 关键点:SMT 中的关键在于寄存器重命名和动态调度,允许来自独立线程的多条指令被执行,而无需考虑它们之间的依赖关系;依赖关系的解决由动态调度能力处理
- SMT 允许处理器在同一时钟周期内执行来自多个不同线程的指令
- 有效性分析:
- 研究表明,SMT 在多程序工作负载中可以带来性能提升,但实际实现通常只支持 2 到 4 个上下文的取指和发射,而不是理论上的无限或更多
- SMT 带来的性能提升通常是适度的
- 总的来说,SMT 在积极的推测处理器中可以提高性能,并以低能耗的方式实现
下图展示了 4 类在超标量处理器上使用功能单元的执行槽 (execution slots):
Fallacies and Pitfalls⚓︎
谬误
- 如果我们能够保持工艺一致的话,那么预测相同指令集架构下的两个不同版本的性能和功耗是比较容易的一件事。
- 有着更低 CPI 或更快时钟频率的处理器总是跑得更快。
- 即使采用了相同的 ISA,在不同的环境下设计出来的处理器在性能和能耗上的表现也有不小差异
陷阱
- 有时更大、更简单会带来更好的表现。
- 有时更聪明的设计相比更大、更简单的设计更好。
- 只要我们用到正确的技术,那么总是有大量可用的 ILP。
评论区