Data Movement Instructions⚓︎
约 10129 个字 241 行代码 预计阅读时间 54 分钟
核心知识
MOV指令相关- 指令格式各字段含义
- 指令前缀:锁 / 段重写 / 操作数大小重写 / 地址大小重写
- 加载有效地址类指令
- 字符串相关指令
- 其他数据指令
上面三类指令太多了,这里不列出来了,复习时都要看的。
- 汇编器相关(MASM)的各种伪指令
MOV Revisited⚓︎
Machine Language⚓︎
- 机器语言(machine language) 是被微处理器用作控制运算的指令(长度 1-15 字节不等)的原生二进制码
- 有超过 10 万种机器语言的指令变体,但目前没有关于所有指令变体的完整列表
- 机器语言指令的某些位是已提供的,剩余的位由指令的具体变体决定
Processor Directive in MASM⚓︎
MASM 中的处理器伪指令(processor directive/pseudo-instruction) 告诉汇编器在汇编过程中启用哪些指令集、处理器类型以及相应的功能。它决定了:
- 什么 CPU 指令是合法的
- 默认的操作数 / 地址大小(16 位 / 32 位)
- 可用的寄存器和寻址模式
- 允许的语法
MASM 的处理器伪指令包括:
- 16 位:
.8086、.186、.286 - 32 位:
386、486、586、686 - 浮点:
.8087、.287、.387 - 特殊目的:
.MMX、.XMM
例子
处理器伪指令的功能:
-
验证指令合法性,比如:
-
基于默认操作数 / 地址大小生成正确的指令编码
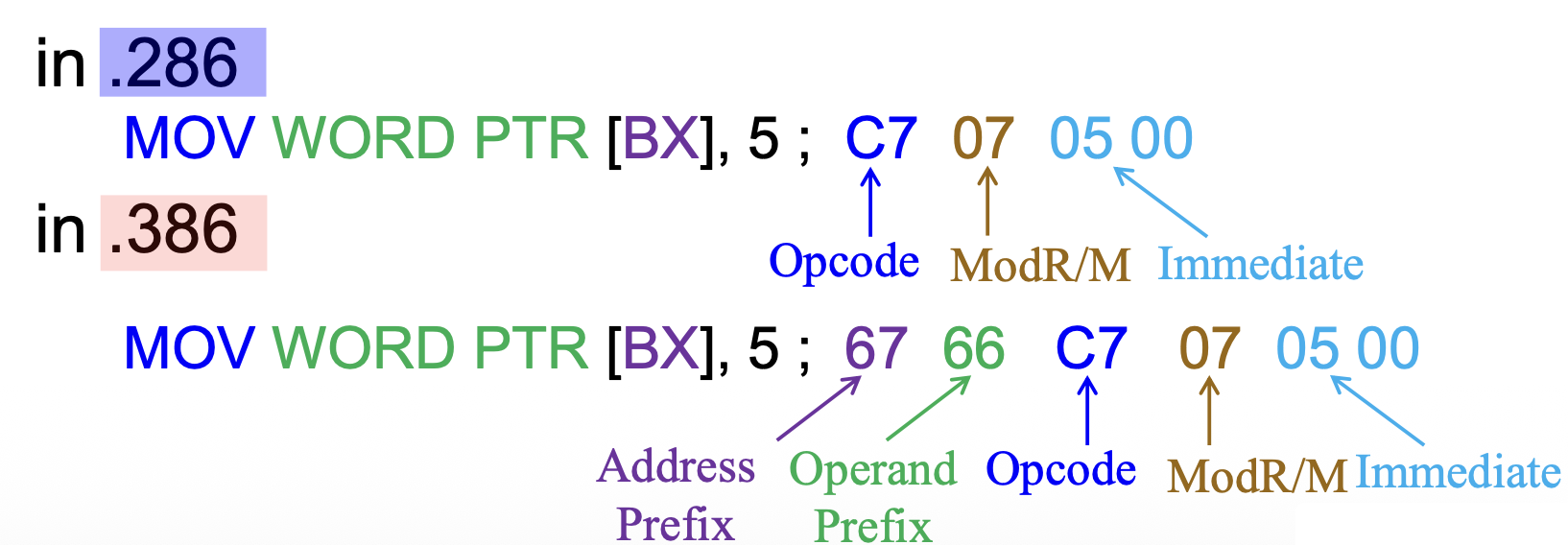
- 第二条指令中,操作数大小前缀
66H选择了非默认的操作数大小,而地址大小前缀67H改变了内存操作数的默认地址大小
- 第二条指令中,操作数大小前缀
Instructions Stored in Memory⚓︎
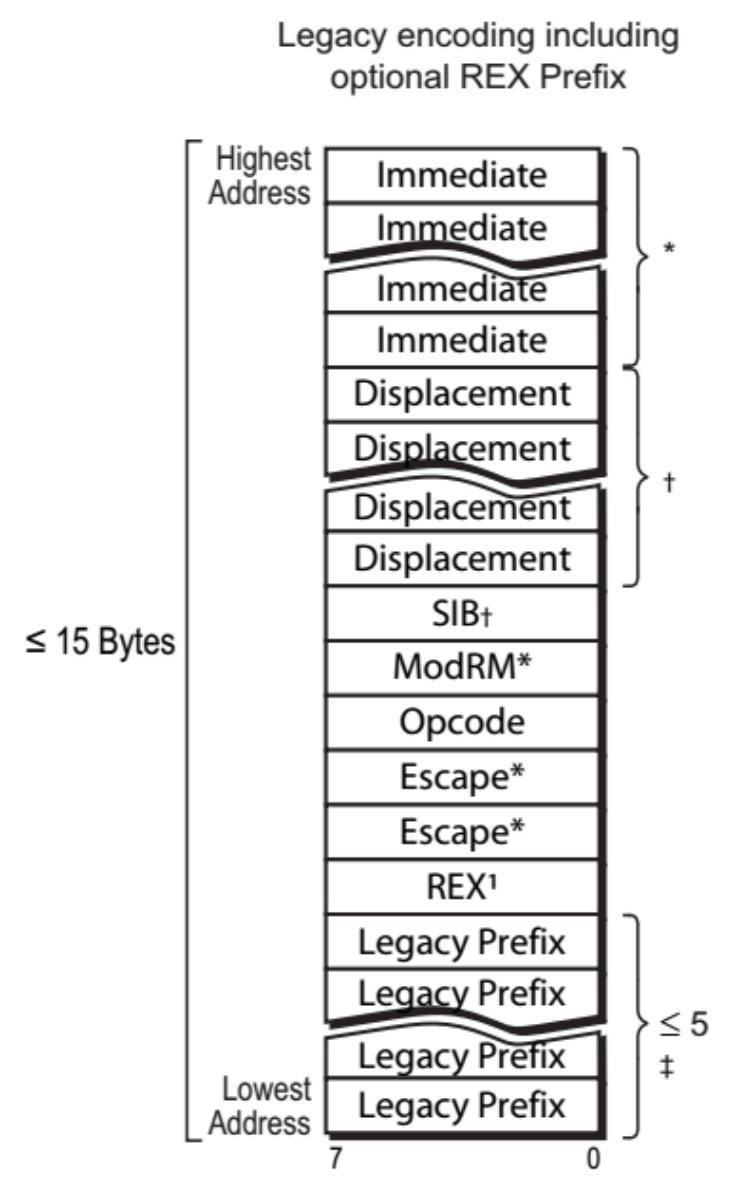
- 指令以小端序(little-endian) 存储在内存中,即指令的第一个字节存储在最低的内存地址上
- 总的指令长度不超过 15 个字节,超出限制的话就会触发一般保护异常(general-protection exception)
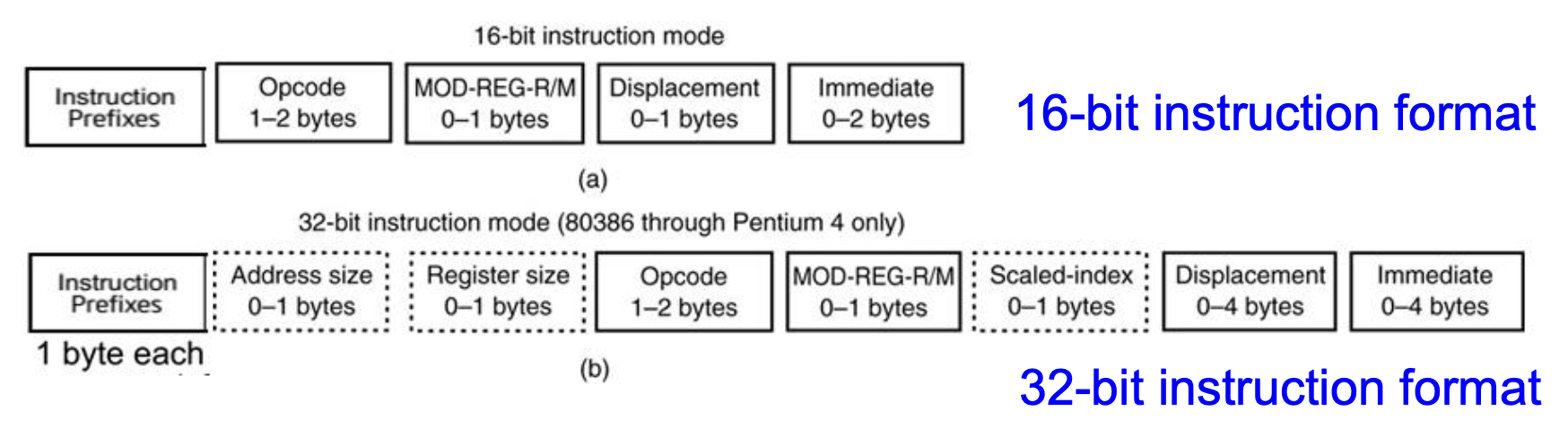
Instruction Formats⚓︎
图片展示了 16 位和 32 位的指令格式,下面就来讲解其中比较重要的一些字节或字段。
Byte 1: Opcode⚓︎
(无前缀的情况下
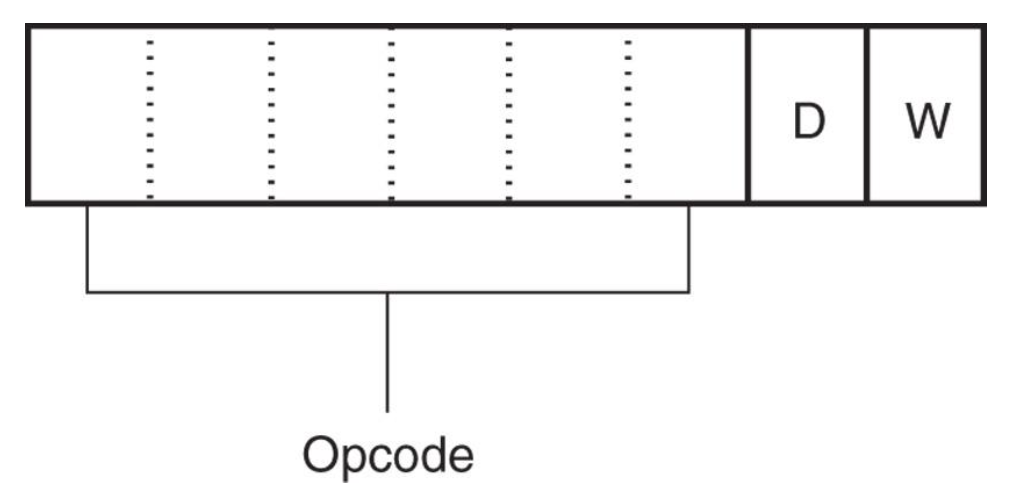
- 第一个字节的前 6 位是二进制操作码
-
剩余 2 位分别表示数据流的方向(D)和数据大小(W
) (字节或字)- 方向位 D
- D = 1:R/M 区域 -> REG 区域
- D = 0:REG 区域 -> R/M 区域
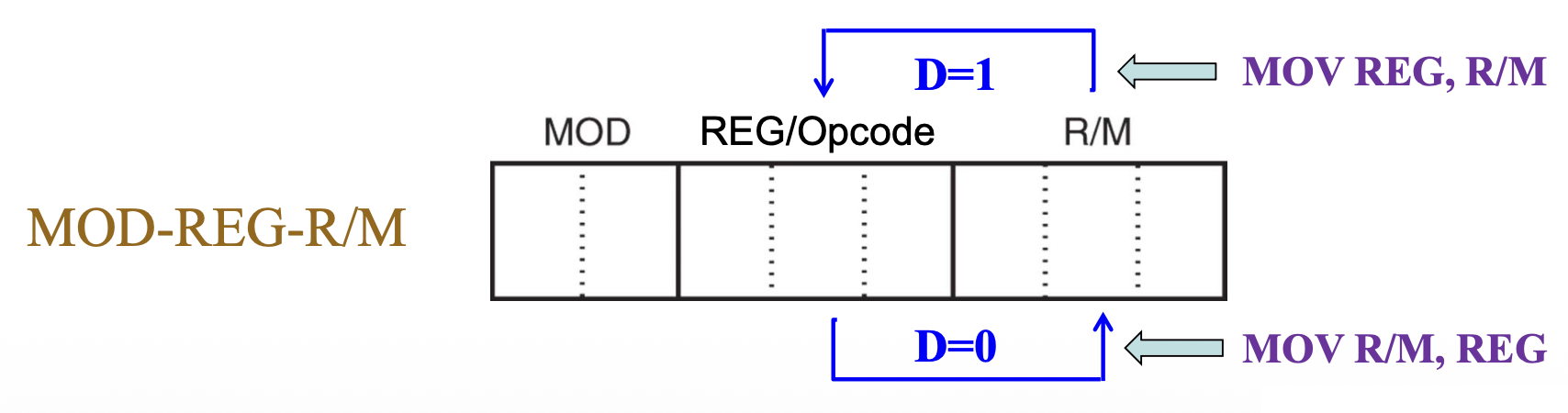
- 宽度位 W
- W = 1:字或双字
- W = 0:只能是字节
其中 W 位出现在大多数指令中,而 D 位主要出现在
MOV指令和其他一些指令中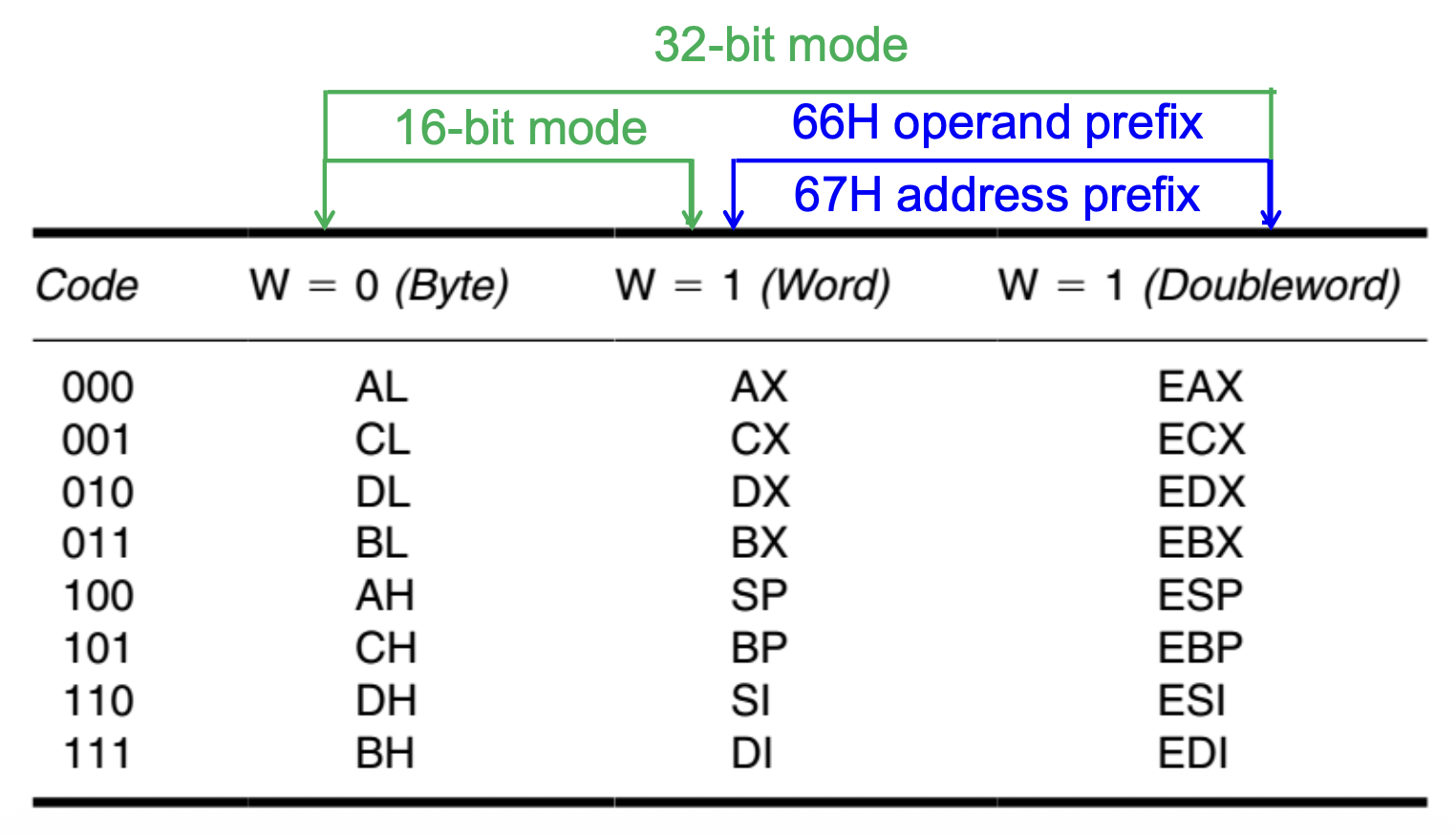
- 方向位 D
为何要设置方向位?
既然汇编语法已经区分了源操作数和目标操作数,并清楚地指定了数据流向的方向,那么为什么 MOD-REG-R/M 字节不直接在 REG 字段中编码目标操作数,在 R/M 字段中编码源操作数呢?
- 在 MOD-REG-R/M 字节中,当两个操作数都使用寄存器寻址时,固定目的操作数和源操作数的编码位置效果较好;然而,当涉及内存寻址时,情况变得复杂
- 由于指令中最多只有一个操作数使用内存寻址,Intel 设计了一个方向位来指示数据是流向 R/M(作为目的)还是从 R/M 流出(作为源
) ,这是一个更高效且更优雅的编码方案 - 在 RISC 架构(例如,RISC-V、ARM)中,由于不支持多种寻址模式,指令格式采用固定位置来表示源操作数和目的操作数,这样数据流向就内在地通过指令格式中操作数的位置来编码
Byte 2⚓︎
第二个字节包含以下字段:
-
MOD:长度为 2 位,用来指定所选指令的寻址模式
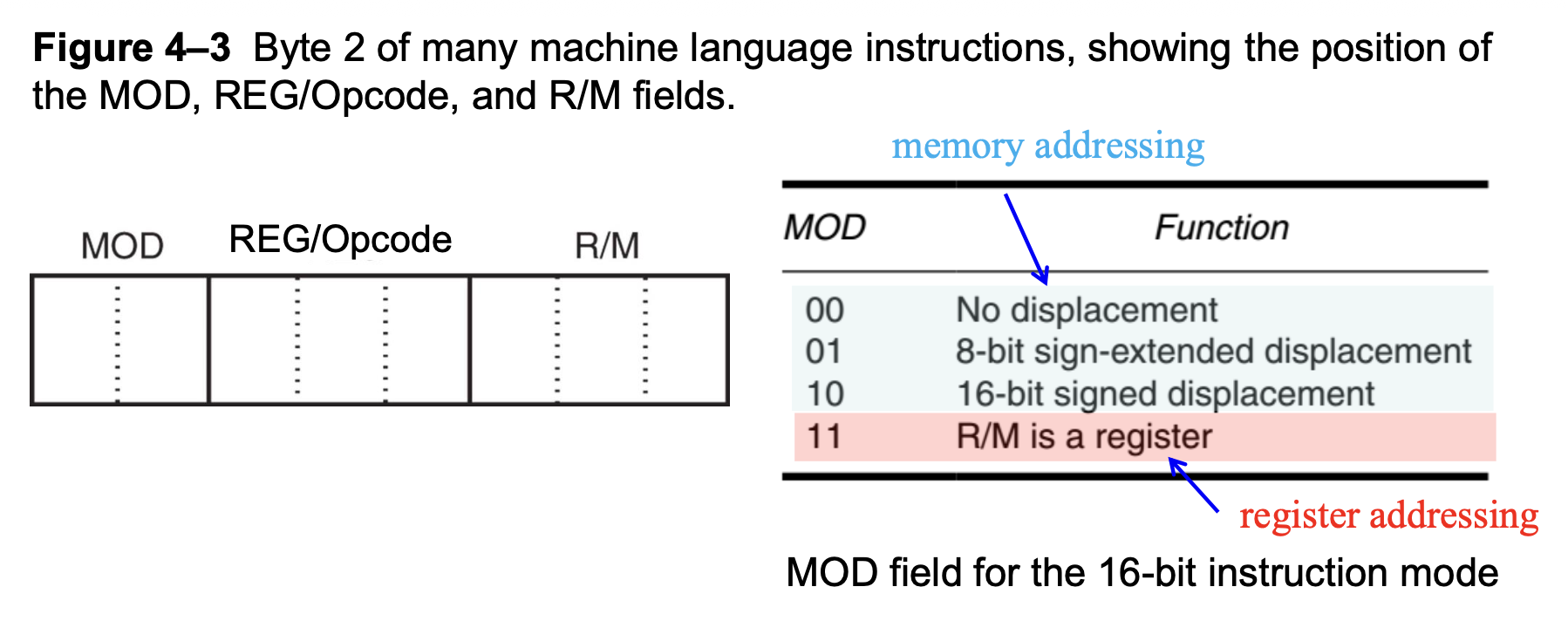
- 如果 MOD 字段包含 11,则选择的是寄存器寻址模式,此时 R/M 字段指定一个寄存器
- 如果 MOD 字段包含 00、01 或 10,则 R/M 字段选择上图所示的三种数据内存寻址模式之一(都是和偏移量相关的)
-
REG/Opcode:长度为 3 位,指明了寄存器编号或有关操作码信息
例子
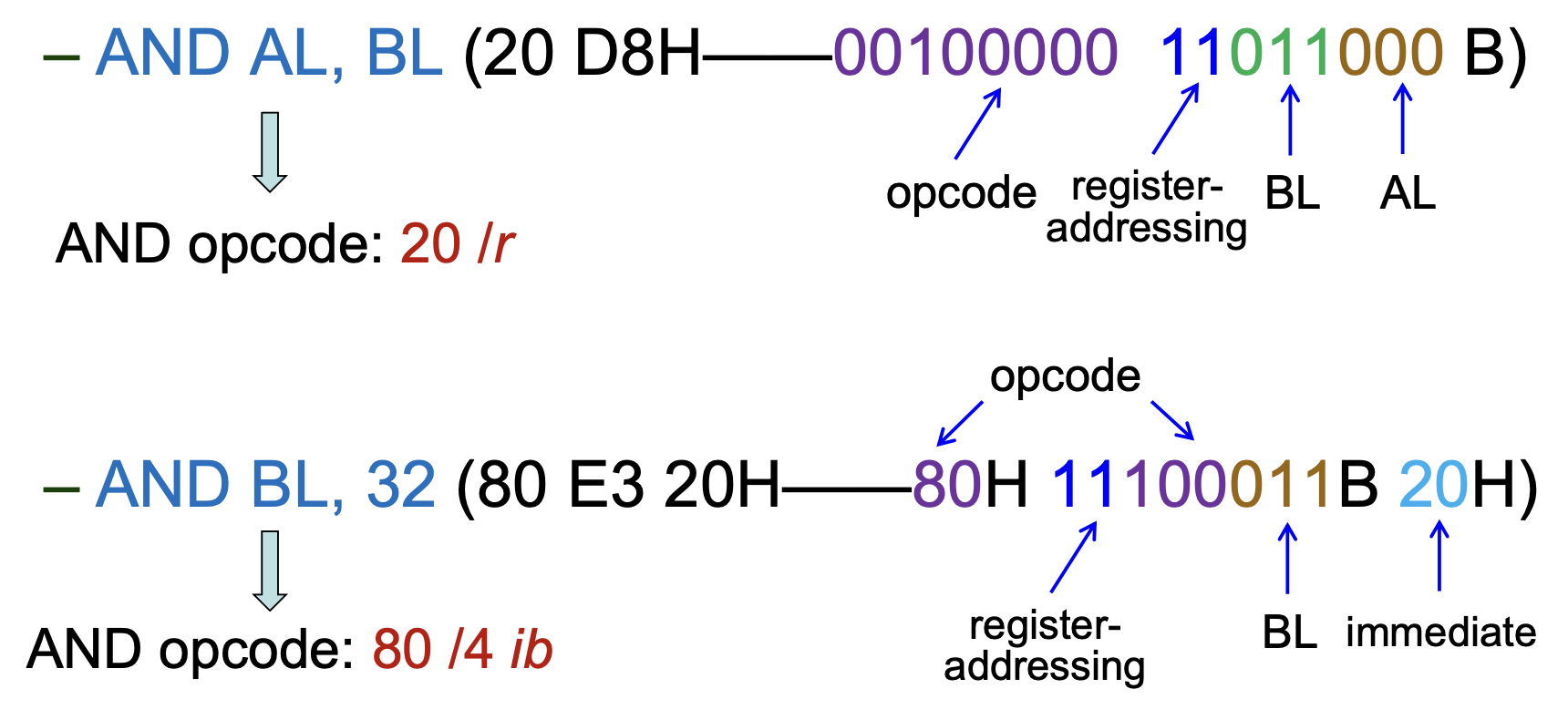
-
R/M:长度为 3 位,指明一个作为操作数的寄存器,或者和 MOD 字段结合来编码一种寻址模式
- 若 MOD 字段为 00、01、10,那 R/M 字段就有了新的含义
例子
下图展示了 16 位指令
MOV DL, [DI](8A15H)的机器码: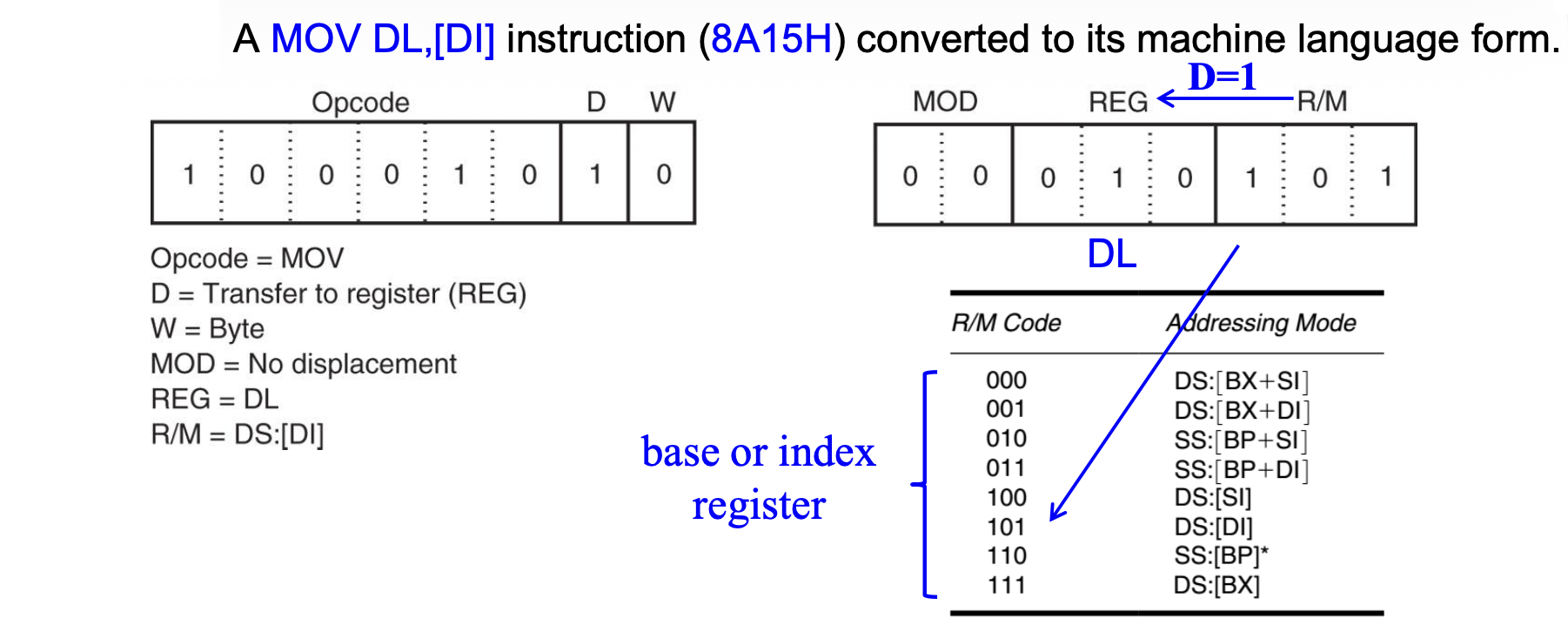
- Opcode = 100010,D = 1,W = 0,MOD = 00,REG/Opcode = 010(
DL) ,R/M = 101([DI]) -
若指令变成
8A5501H(多了01H的偏移量)
- 前面一个字节保持不变
- MOD 字段变为
01,用于 8 位偏移 - 于是指令变为
MOV DL, [DI+1]
-
当 R/M = 100 时,指令会新增一个叫做比例变址字节(scaled-index byte) 的额外字节,用于比例变址寻址
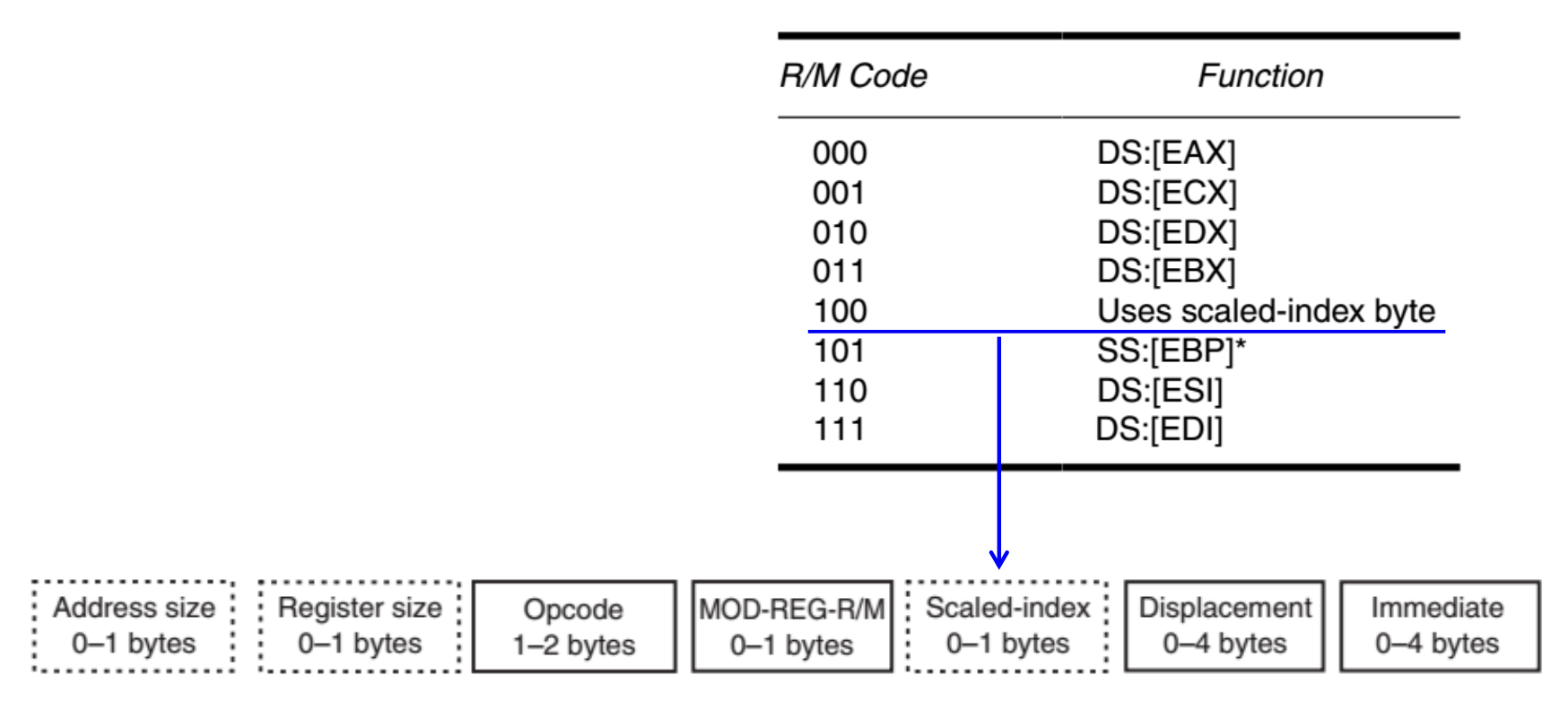
- 80386 之后的处理器有超过 32,000 中
MOV指令的变体 -
下图展示了当 80386 及以上版本使用 32 位地址时,指令中 R/M = 100 时比例变址字节的格式:
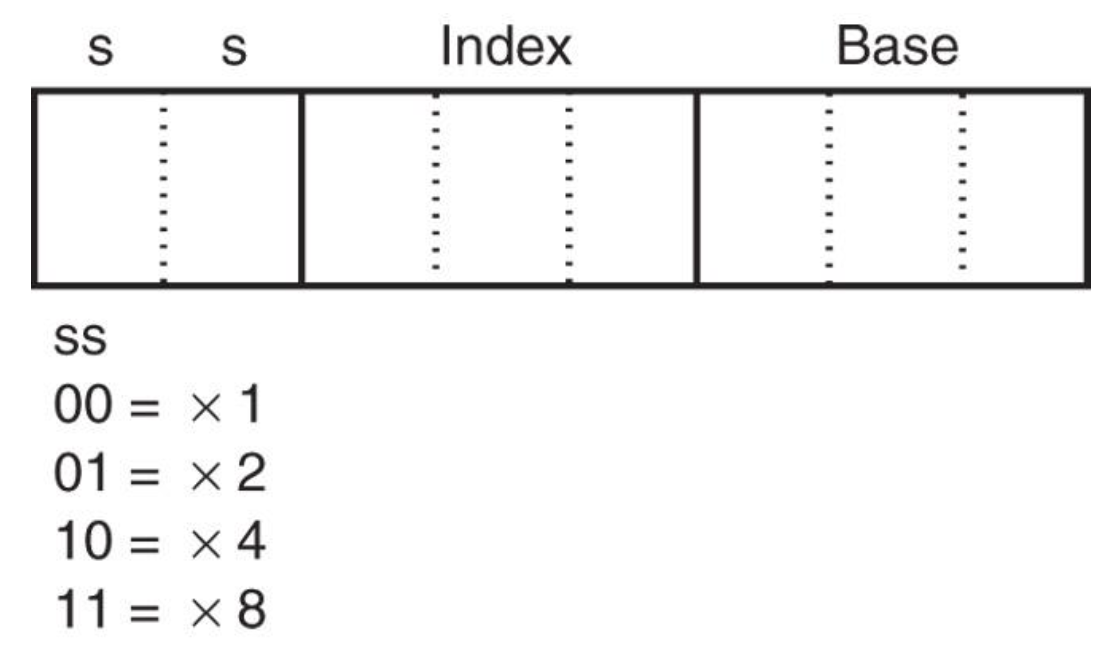
- 最左边两位表示比例因子(乘数)1x、2x、4x、8x
- 变址和基址字段值均为寄存器编号
例子

- 80386 之后的处理器有超过 32,000 中
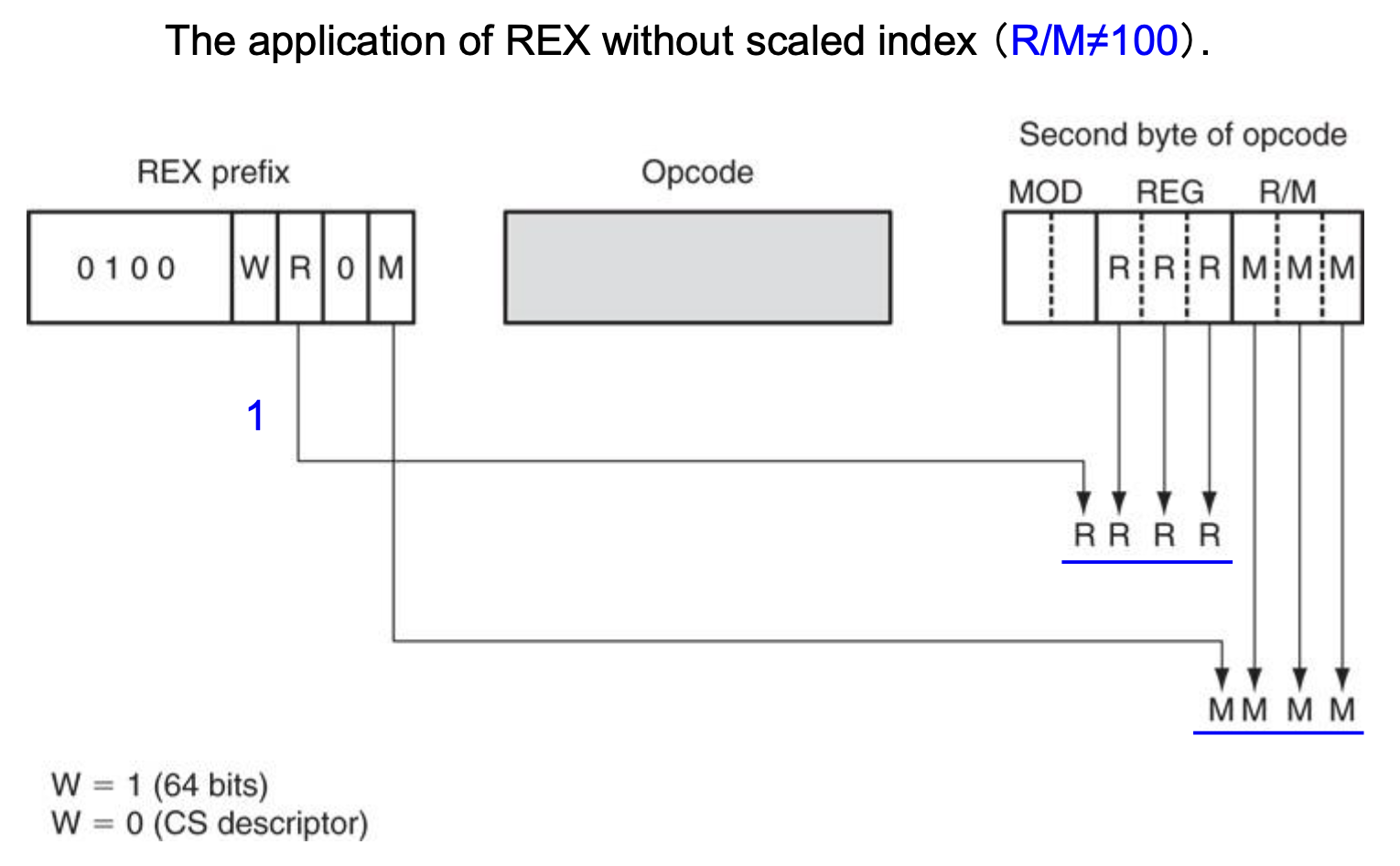
64-Bit Addressing Mode⚓︎
- 在 64 位模式下,添加了一个名为 REX(寄存器扩展)的前缀,用于启用操作数大小扩展和寄存器
R8-R15 - REX 不是一个单个的唯一值,而是占据一个范围(40h 到 4Fh
) ,并位于其它前缀之后,操作码之前 - 可用于扩展指令第二字节中的 REG 和 R/M 字段,以便引用寄存器
R8-R15(23+1=16) - REX 包含五个字段:高四位是 REX 前缀独有的,作为标识;低四位分为四个 1 位字段(W、R、X、B)

下图说明了 REX 对第二个字节中 REG 和 R/M 字段的修改:
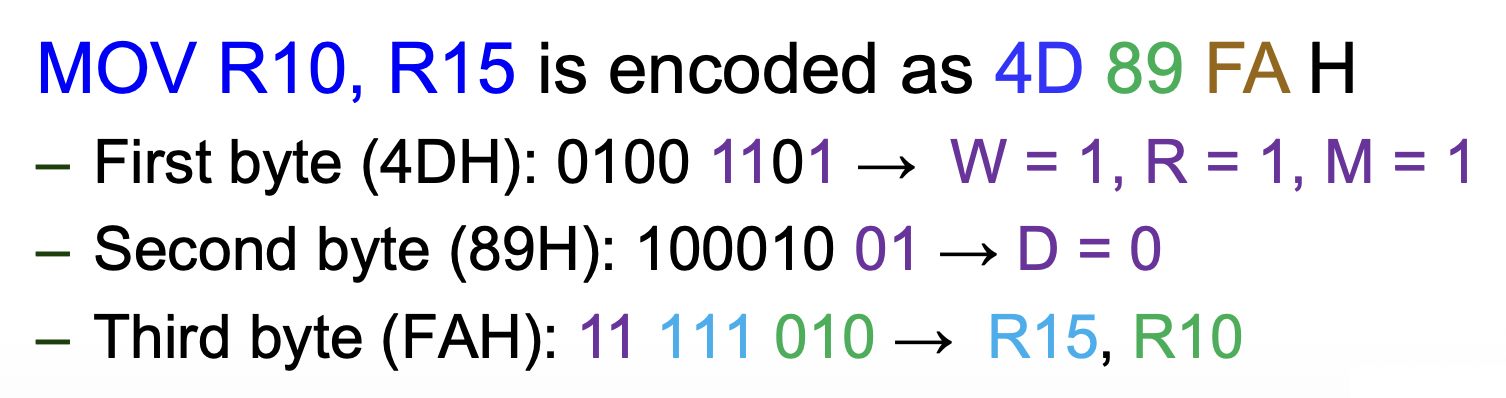
例子
下图展示了 REX 前缀对比例变址字节中变址和基址的修改:
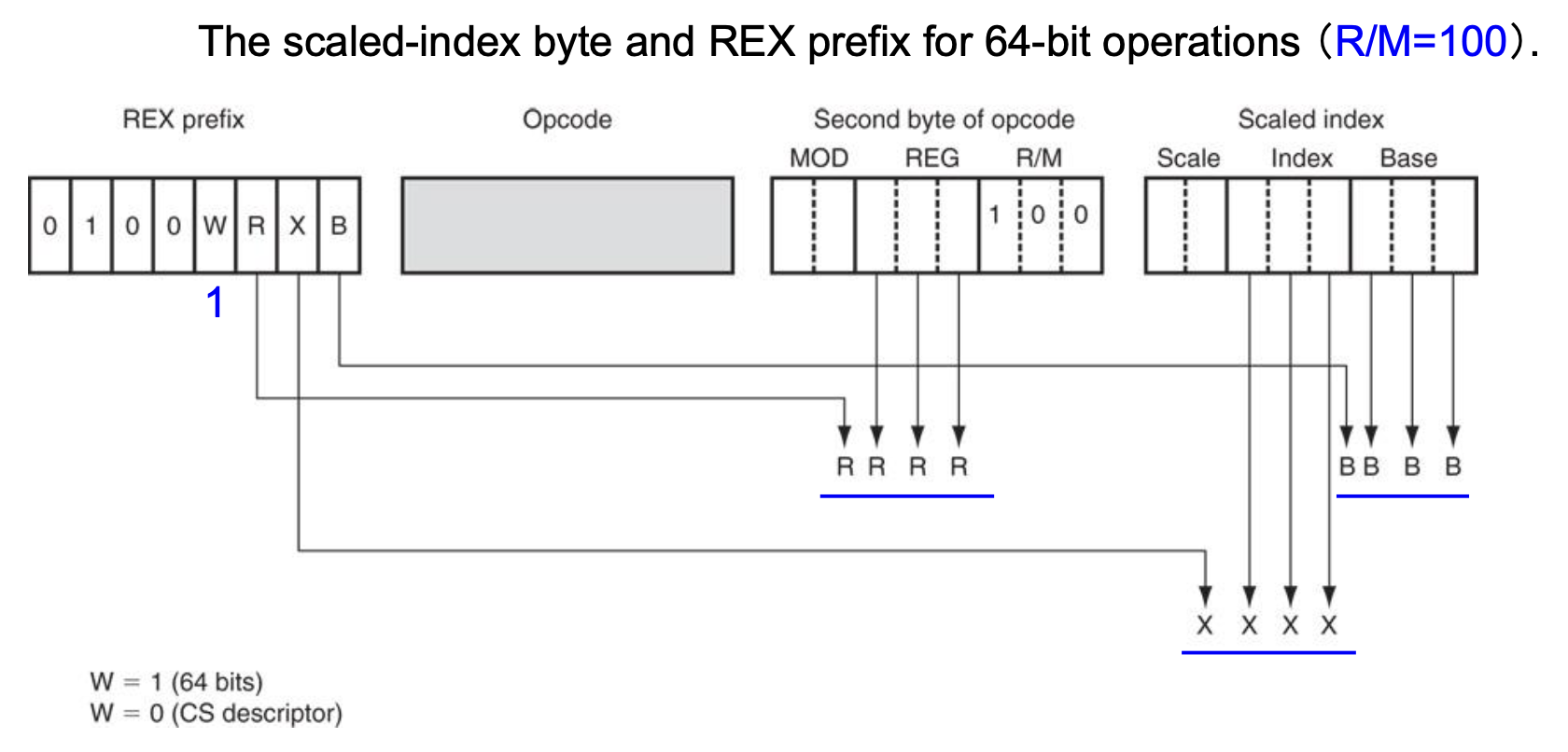
例子

Legacy Prefixes⚓︎
指令前缀分为四组,每条指令只能使用每个组中的一个前缀:
- 组 1(锁/重复前缀)
- 0xF0:
LOCK - 0xF2:
REPNE/REPNZ - 0xF3:
REP/REPE/REPZ
- 0xF0:
- 组 2(段重写前缀)
- 0x26:
ES段重写 - 0x2E:
CS段重写 - 0x36:
SS段重写 - 0x3E:
DS段重写 - 0x64:
FS段重写 - 0x65:
GS段重写
- 0x26:
- 组 3:操作数大小重写前缀(0x66)
- 组 4:地址大小重写前缀(0x67)
Lock Prefix⚓︎
LOCK 前缀会让某些类型的内存读 / 改 / 写指令执行原子操作,旨在使处理器在多处理器系统中独占(exclusive) 使用共享内存。该前缀只能与以下写入内存操作数的指令一起使用:
BTC, BTR, BTS ; 位测试指令(下一章介绍)
ADC, ADD, AND, DEC, INC, NEG, NOT, OR, SBB, SUB, XOR ; 加减,以及除移位外的常见位运算指令
CMPXCHG, CMPXCHG8B, CMPXCHG16B, XADD, XCHG ; 原子运算
如果将 LOCK 前缀与上面没提到的指令一起使用,将发生未定义的操作码异常(undefined opcode exception)(#UD
例子
Segment Override Prefix⚓︎
-
处理器可以自动根据以下规则选择默认段:
- 指令:CS
- 局部数据:DS
- 栈:SS
- 目标字符串:ES
-
程序员可以使用段重写前缀(segment override prefix) 来重写默认段,该前缀要放置在指令开头的字节上
- 唯一不能加前缀的指令是将代码段寄存器用于(存储)生成地址的跳转和调用指令
- 在指令前面附加额外的字节,以选择备用段寄存器
下面列举一些使用段重写前缀的例子:
| 汇编语言 | 访问的段 | 默认段 |
|---|---|---|
MOV AX, DS: [BP] |
数据段 | 栈段 |
MOV AX, ES: [BP] |
附加段 | 栈段 |
MOV AX, SS: [DI] |
栈段 | 数据段 |
MOV AX, CS: LIST |
代码段 | 数据段 |
MOV ES: [SI], AX |
附加段 | 数据段 |
LODS ES: DATA1 |
附加段 | 数据段 |
MOV EAX, FS: DATA2 |
FS | 数据段 |
MOV GS: [ECX], BL |
GS | 数据段 |
Operand-Size Override Prefix⚓︎
使用操作数大小重写前缀(operand-size override prefix) 来混合 16 位、32 位和 64 位数据:
- REX(REX.W)前缀可以指定 64 位操作数大小
- 66H 前缀指定 16 位操作数大小
- REX 前缀的优先级高于 66H 前缀
- 默认操作数大小由当前操作模式定义,但操作数大小重写前缀可以改变默认操作数大小
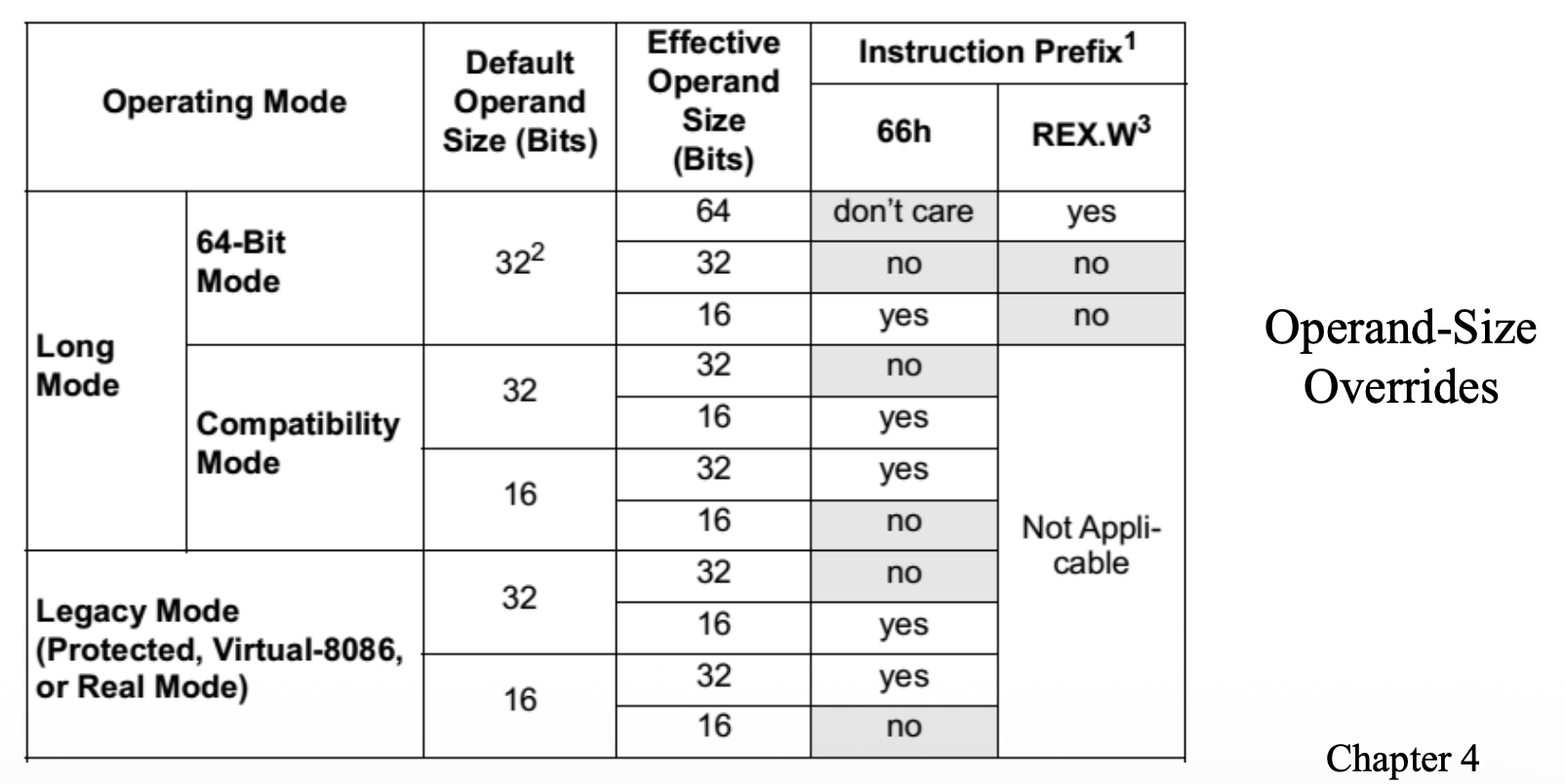
例子
64 位模式下:

因为默认操作数大小为 32 位,所以第二条指令里即便用了 DWORD PTR,也没有出现额外的指令前缀字节。
Address-Size Override Prefix⚓︎
内存操作数的默认地址大小同样由当前操作模式确定,但可以通过地址大小重写前缀(67H)来重写。
- 在 64 位模式下,地址默认为 64 位,但可以通过地址大小前缀重写为 32 位
- 在 32 位模式下,地址默认为 32 位,但可以通过地址大小前缀重写为 16 位
例子

Quiz
VEX Prefix (Vector Extensions)
- VEX 前缀以字节
C4H或C5H开始 - 可用于编码操作
YMM或XMM寄存器的指令 - 支持三个以上的操作数
- 支持非破坏性源操作数的指令语法编码
Escape Sequence / Opcode
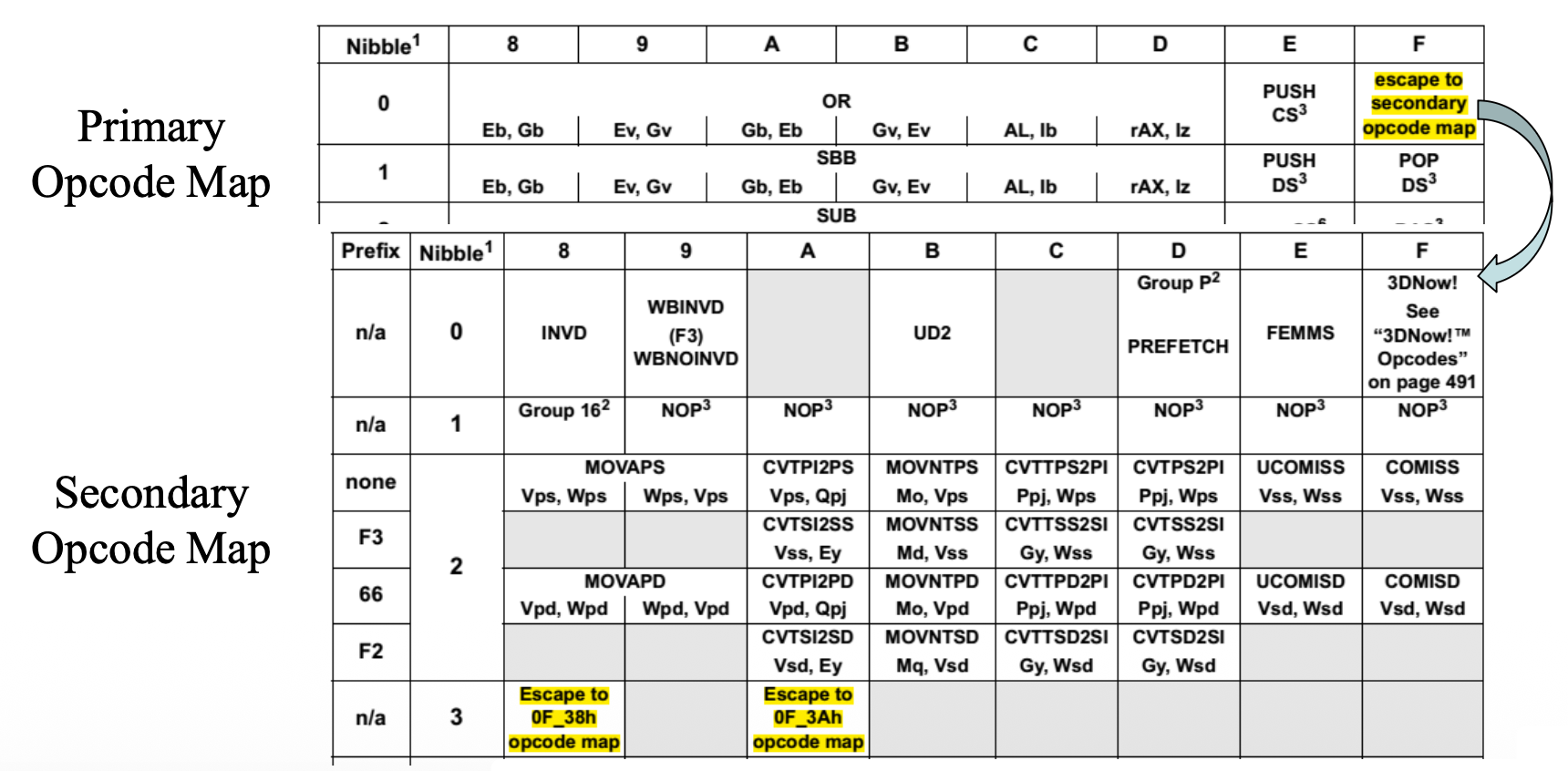
由于架构定义的指令超过 256 条,因此必须定义多个不同的操作码映射。具体做法是:通过使用一个转义操作码字节(0FH)或两字节的转义(0F38H,0F3AH)来扩展编码空间,以提供其他操作码。
Load Effective Address⚓︎
两种加载有效地址 (load effective address) 指令类型:
LEA:加载近指针(偏移量)LDS、LES、LFS、LGS、LSS加载远指针(段选择器和偏移量)
例子
考虑以下表示 (x, y) 坐标的结构体:
假如有以下函数:
-
MOV EDX, [EBX + 8*EAX + 4] -
LEA ESI, [EBX + 8*EAX + 4]
注:EBX 是数组(点)的基址,EAX 表示变量 i,8 是每个点的比例因子,4 是 y 的偏移量
LEA⚓︎
LEA 的作用是将操作数指定的数据的偏移地址加载到 16 位或 32 位寄存器中。
比较 LEA 与 MOV
LEA BX, [DI]将[DI]指定的偏移地址(此处就是DI值本身)加载到BX寄存器中MOV BX, [DI]将[DI]地址指向的内存位置存储的数据加载到寄存器BX中
SEG 和 OFFSET 指令返回内存位置的段和偏移值。
- 如果操作数是一个偏移量,那么
OFFSET执行和LEA相同的功能 OFFSET指令比LEA指令更高效MOV BX, OFFSET LIST需要 1 个时钟周期- 80486 微处理器中,
LEA BX, LIST需要 2 个时钟周期 - 原因:实际上第一条指令被汇编为立即数移动指令,效率更高(比如
MOV BX, 0x9)
思考
既然 OFFSET 已经能完成同样的任务,为什么还要有 LEA 指令?
OFFSET 只能与像 LIST 这样简单的操作数一起使用,不能用于像 [DI]、[SI]、[BX+DI] 这样的操作数,例如:
LEA BX, [DI]->MOV BX, DILEA SI, [BX+DI]:这条指令将BX加到DI上,并将和存储在SI寄存器中;由这条指令生成的和是一个模 64K 的和
例子
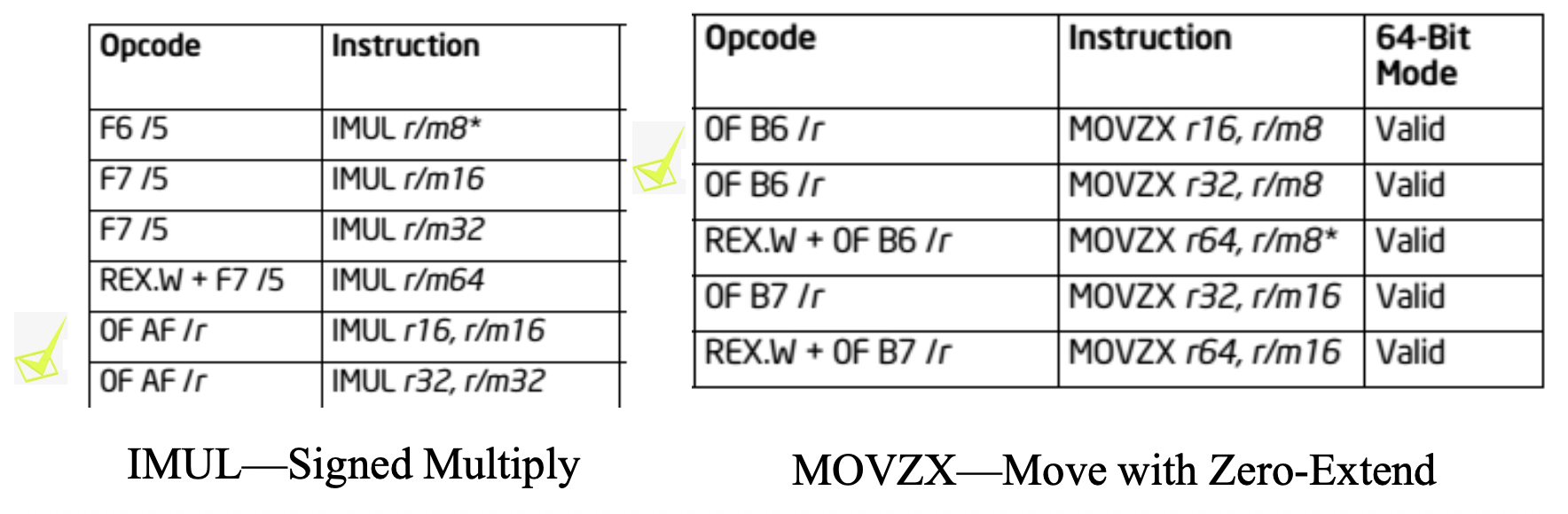
以下常见指令是在 8086 之后引入的,并且没有剩余的编码空间来为它们提供单字节操作码:
0F AF是IMUL r16, r/m16的操作码0F B6是MOVZX r16, r/m8的操作码
以下程序将 DATA1 的地址加载到 SI,DATA2 的地址加载到 DI,然后交换这两个内存位置的内容。
.MODEL SMALL ; select small model
0000 .DATA ; start data segment
0000 2000 DATA1 DW 2000H ; define DATA1
0002 3000 DATA2 DW 3000H ; define DATA2
0000 .CODE ; start code segment
.STARTUP ; start program
0017 BE 0000 R LEA SI, DATA1 ; address DATA1 with SI
001A BF 0002 R MOV DI, OFFSET DATA2 ; address DATA2 with DI
001D 8B 1C MOV BX, [SI] ; exchange DAT1 with DATA2
001F 8B 0D MOV CX, [DI]
0021 89 0C MOV [SI], CX
0023 89 1D MOV [DI], BX
.EXIT
END
LDS, LES, LFS, LGS, and LSS⚓︎
LDS 和 LES 从内存加载远地址。
- 先从内存中检索到的偏移地址加载到指定的 16 或 32 位寄存器中
- 再从内存中检索到的段地址或段选择器加载到
DS或ES中 - 32 位远指针:16 位段 + 16 位偏移
- 48 位远指针:16 位选择器 + 32 位偏移
例子
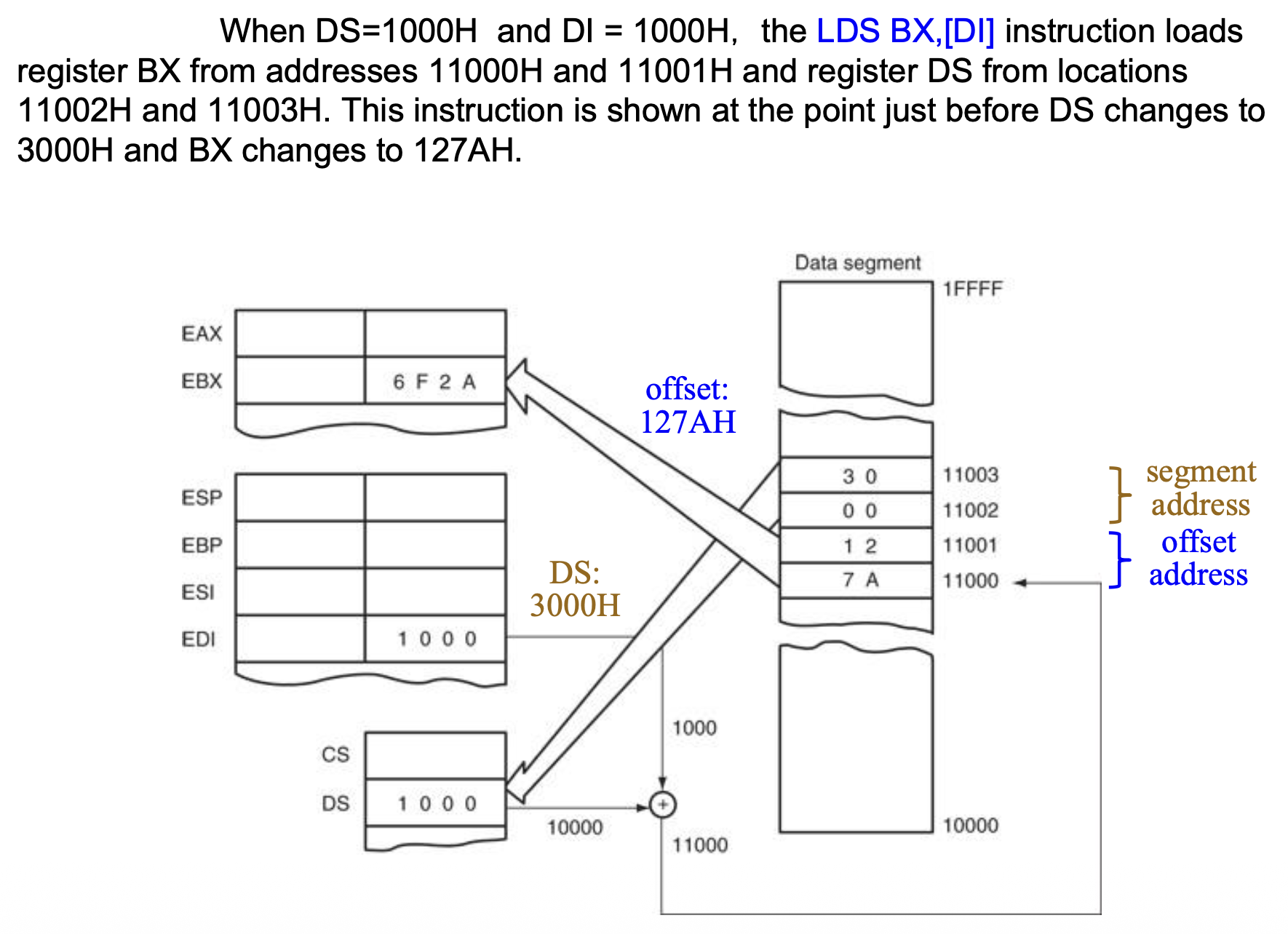
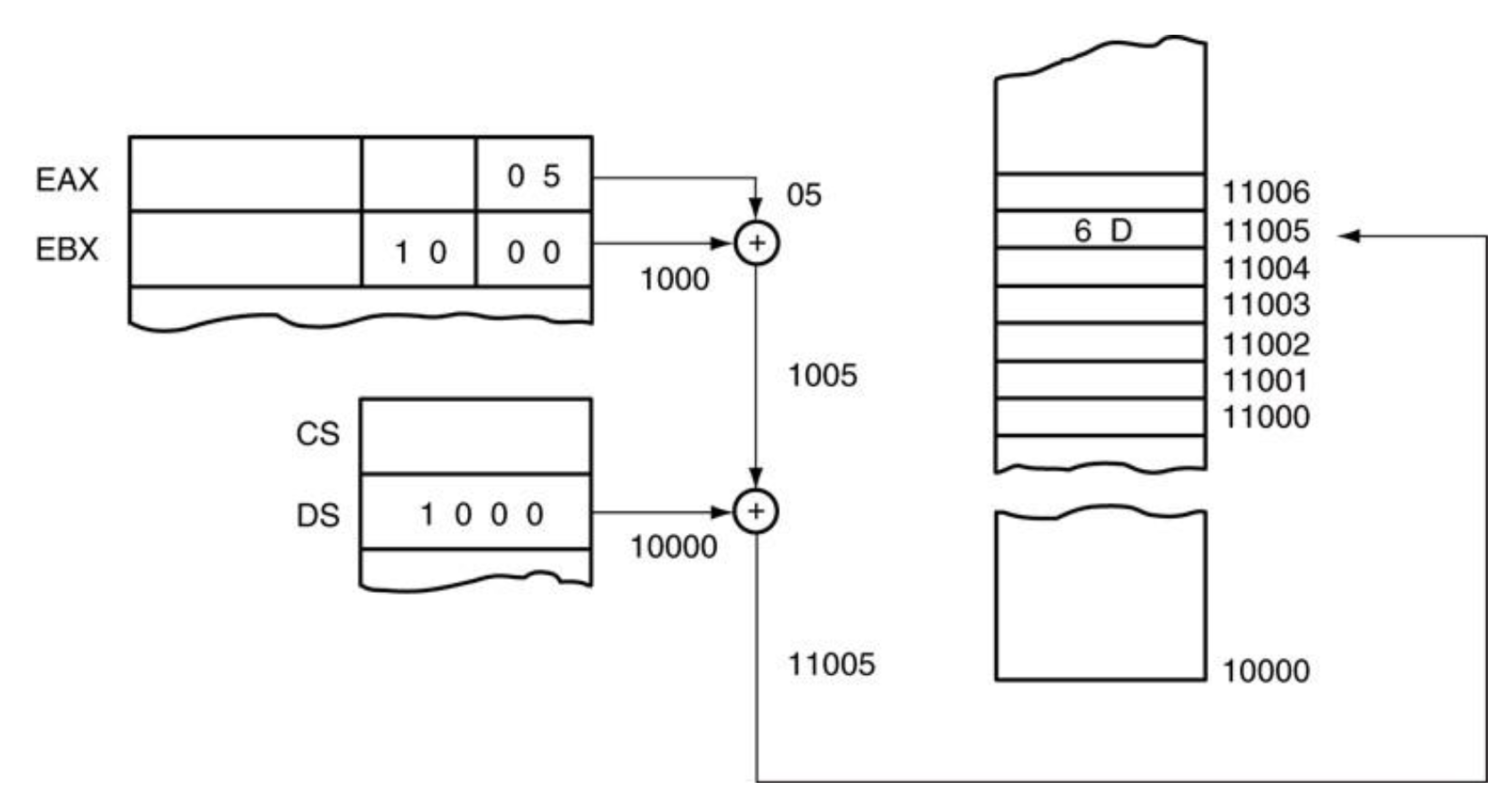
当 DS=1000H 且 DI=1000H 时,LDS BX,[DI] 指令从地址 11000H 和 11001H 加载寄存器 BX,从地址 11002H 和 11003H 加载寄存器 DS。下面展示了在 DS 变为 3000H 和 BX 变为 127AH 之前的情况:
在 80386 及以上版本中,增加了 LFS、LGS 和 LSS 指令。规则同 LDS 和 LES,但分别加载 DS、ES、FS、GS 或 SS 段寄存器。
例子
远地址可以通过汇编器存储在内存中,其中最有用的加载指令是 LSS 指令。下面通过使用 LSS 指令同时加载 SS 和 SP 来重新激活旧栈区:

这里用到了
CLI(禁用中断)和STI(启用中断)指令。
String Data Transfers⚓︎
- 字符串数据传输指令(string data transfer instructions):
LODS,STOS,MOVS,INS,OUTS - 字符串比较指令(string comparison instructions):
SCAS,CMPS
注:这些指令的前 2-3 个字母表明了指令的功能,并且 "S" 代表字符串。
-
每个指令都允许以单字节、字或双字的形式进行数据传输或比较,并隐式使用
DI/EDI,SI/ESI或同时使用两个寄存器来寻址内存DI/EDI带有额外段ES,不能被覆盖SI/ESI带有数据段DS,可以被覆盖
-
字符串指令执行效率高,因为它们支持自动重复操作并增加数组索引
-
方向标志(direction flag)
- D = 0:自动递增(低位 -> 高位)
- D = 1:自动递减(高位 -> 低位)
-
REP和CX/ECX:重复前缀(REP)使得指令可以重复 n 次,其中 n 是存储在CX/ECX中的值 -
可以使用的后缀:
B:字节W:字D:双字- 例如:
MOVSB:字节大小的MOVSLODSW:字大小的LODS
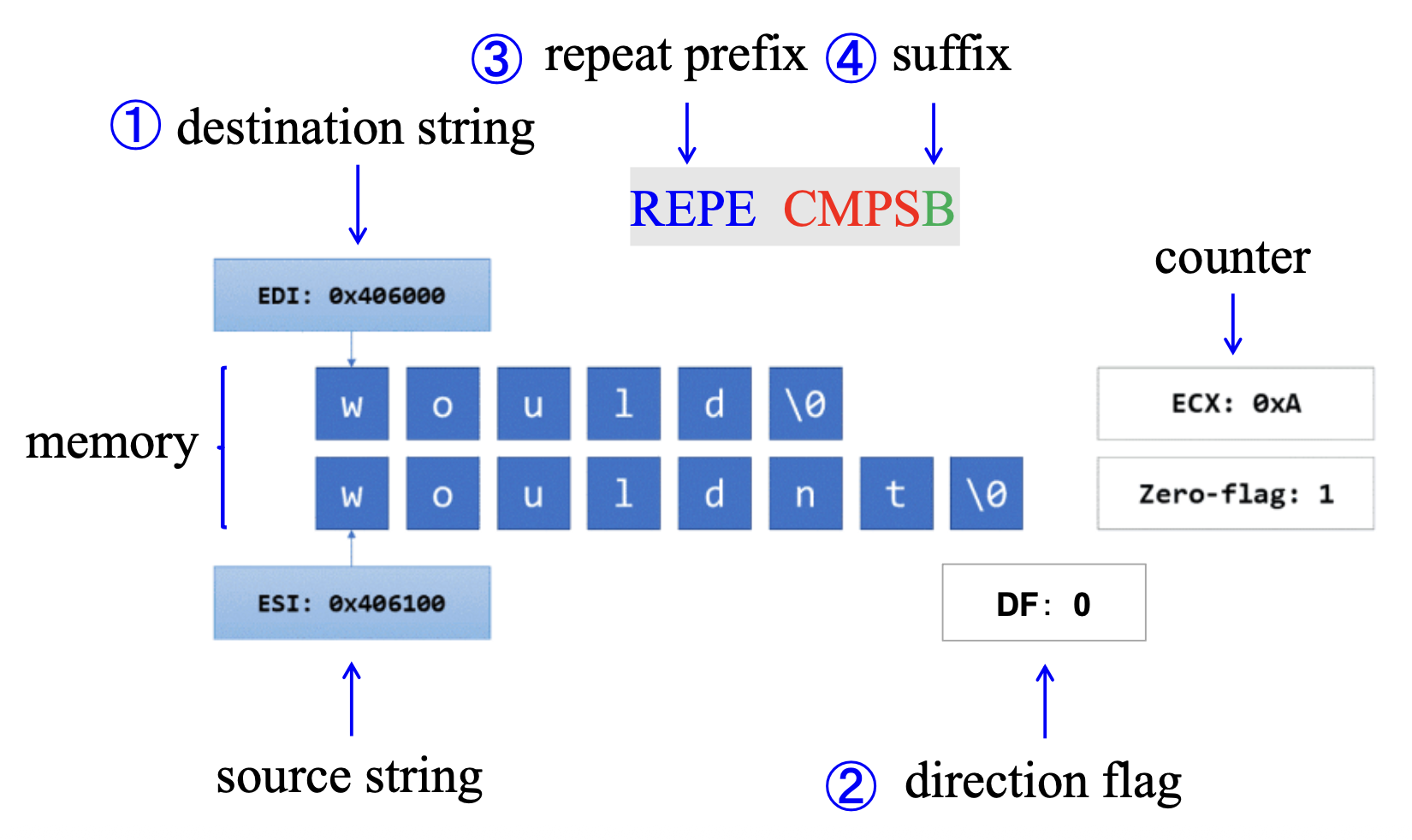
例子:字符串比较
DI and SI⚓︎
-
在执行字符串指令期间,内存访问通过
DI和SI寄存器进行DI偏移地址访问附加段(ES)中的数据(目标字符串)SI偏移地址访问数据段(DS)中的数据(源字符串)
-
在 32 位模式下操作时,使用
EDI和ESI寄存器代替DI和SI,此时字符串能使用整个 4G 字节保护模式地址空间中的任何内存位置
Direction Flag⚓︎
方向标志(direction flag)(D,位于标志寄存器中)在字符串操作期间选择 DI 和 SI 寄存器的自动增减操作。该标志仅与字符串指令一起使用。可以使用以下指令改变该标志:
CLD指令选择自动递增模式,清除 D 标志STD指令选择自动递减模式,设置 D 标志
Repeat Prefix⚓︎
字符串原语指令仅处理单个内存值或一对值。若添加了一个重复前缀(repeat prefix),则指令会使用 CX 或 ECX 作为计数器,重复执行指令,从而达到使用单个指令来处理整个数组的目标。下面列举了可用的重复前缀:
REP:当ECX > 0时重复REPZ,REPE:当ZF = 1且ECX > 0时重复REPNZ,REPNE:当ZF = 0且ECX > 0时重复
示例:拷贝一个字符串
在以下示例中,MOVSB 将 10 个字节从 string1 移动到 string2。当 MOVSB 重复执行时,ESI 和 EDI 会自动增加,此行为受方向标志控制。
cld ; clear direction flag
mov esi, OFFSET string1 ; ESI points to source
mov edi, OFFSET string2 ; EDI points to target
mov ecx, 10 ; set counter to 10
rep movsb ; move 10 bytes
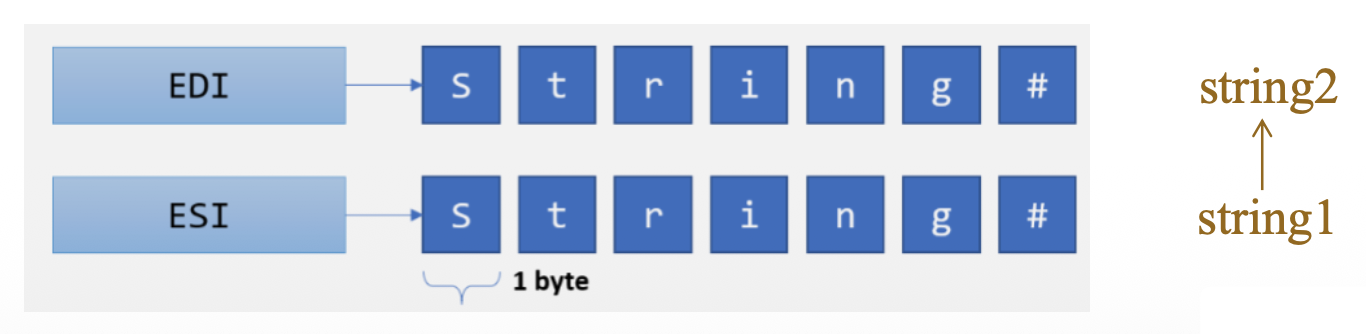
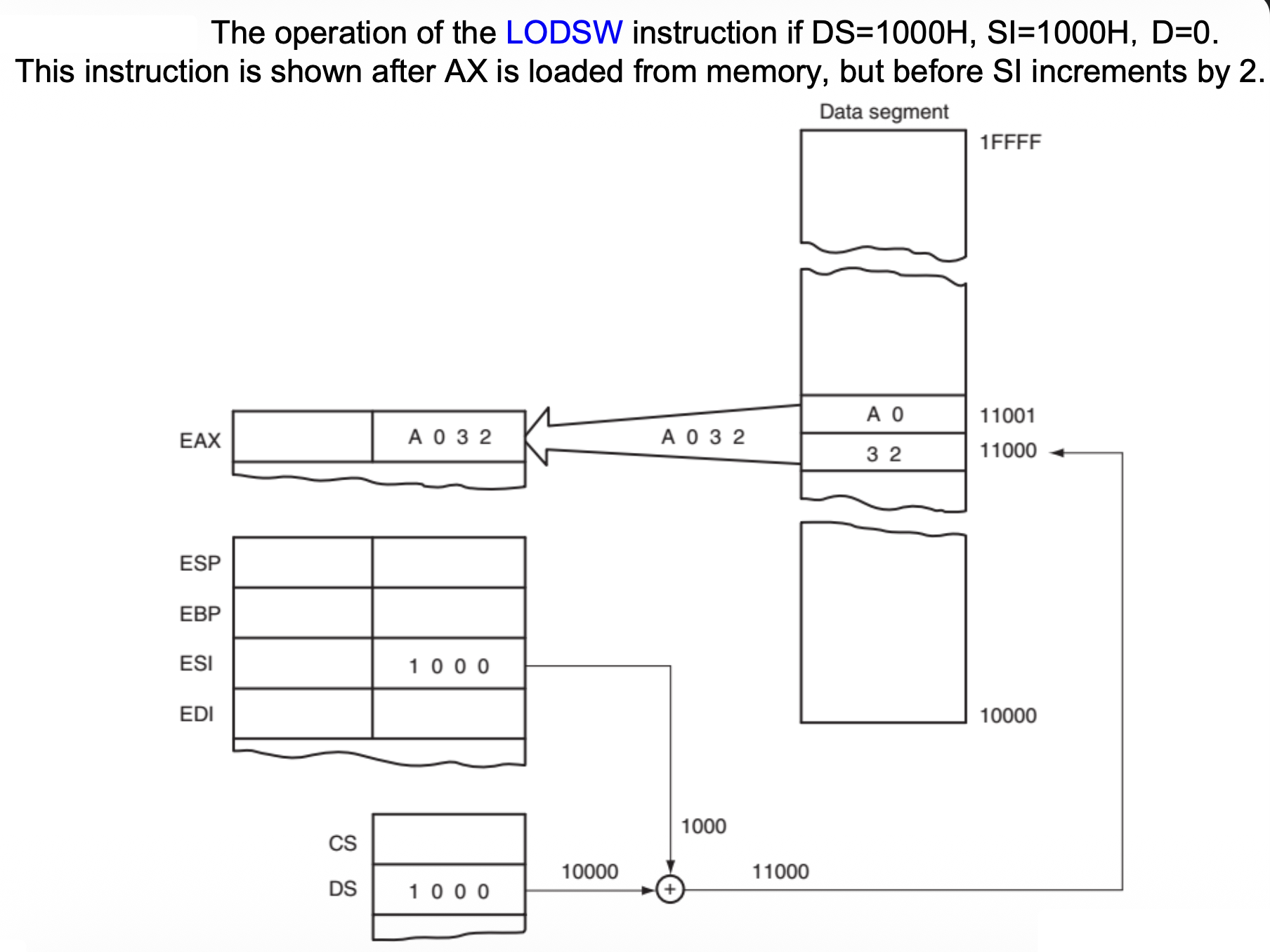
LODS⚓︎
LODS 从源位置 DS:SI 传输一个字节、字或双字到 AL、AX 或 EAX(隐式操作数(implicit operands),即在操作数或操作码中未明确提及的操作数
LODSB:DS:SI/ESI\(\pm\) 1LODSW:DS:SI/ESI\(\pm\) 2LODSD:DS:SI/ESI\(\pm\) 4
例子
下面展示了当 DS=1000H,SI=1000H,D=0 时 LODSW 指令的操作,对应在 AX 从内存加载后,但在 SI 增加 2 之前的时间节点:
STOS⚓︎
STOS 将一个字节、字或双字从 AL、AX 或 EAX 存储到目标位置 ES:DI 上。
STOSB:ES:DI/EDI\(\pm\) 1STOSW:ES:DI/EDI\(\pm\) 2STOSD:ES:DI/EDI\(\pm\) 4
当与 REP 前缀一起使用时,STOS 指令可用于将单个值填充到字符串或数组的所有元素中。
- 如果
CX值为 0,字符串指令终止,程序继续执行 - 如果
CX的值为 100,并执行REP STOSB指令,微处理器将自动重复STOSB100 次
注意
重复前缀(REP)可被添加到除 LODS 型指令外(防止寄存器中的数据被覆盖)的任何字符串数据传输指令中。
例子
以下代码将 string1 中的每个字节初始化为 0FFh
MOVS⚓︎
MOVS 从 DS:SI 传输一个字节、字或双字到 ES:DI,并且更新 SI 和 DI
MOVSB: (DS:SI和ES:DI)\(\pm\) 1MOVSW(DS:SI和ES:DI)\(\pm\) 2MOVSD(DS:SI和ES:DI)\(\pm\) 4
该指令是唯一一个可以实现内存到内存传输(memory-to-memory transfer) 的合法指令。
例子
传输两个双字内存块:
- C++ 版本:
void TransferBlocks(int blockSize, int* blockA, int* blockB) {
for (int a = 0; a < blockSize; a++) {
*blockB = *blockA++;
blockB++;
}
}
-
内联汇编:
void TransferBlocks(int blocksize, int* blockA, int* blockB) { _asm{ push es ; save registers push edi push esi push ds ; copy DS into ES pop es mov esi, blockA ; address blockA mov edi, blockB ; address blockB mov ecx, blocksize ; load count rep movsd ; move data pop esi pop edi pop es ; restore registers } }
INS⚓︎
INS 指令将一个字节、字或双字数据从 I/O 设备传输到附加段内存位置。
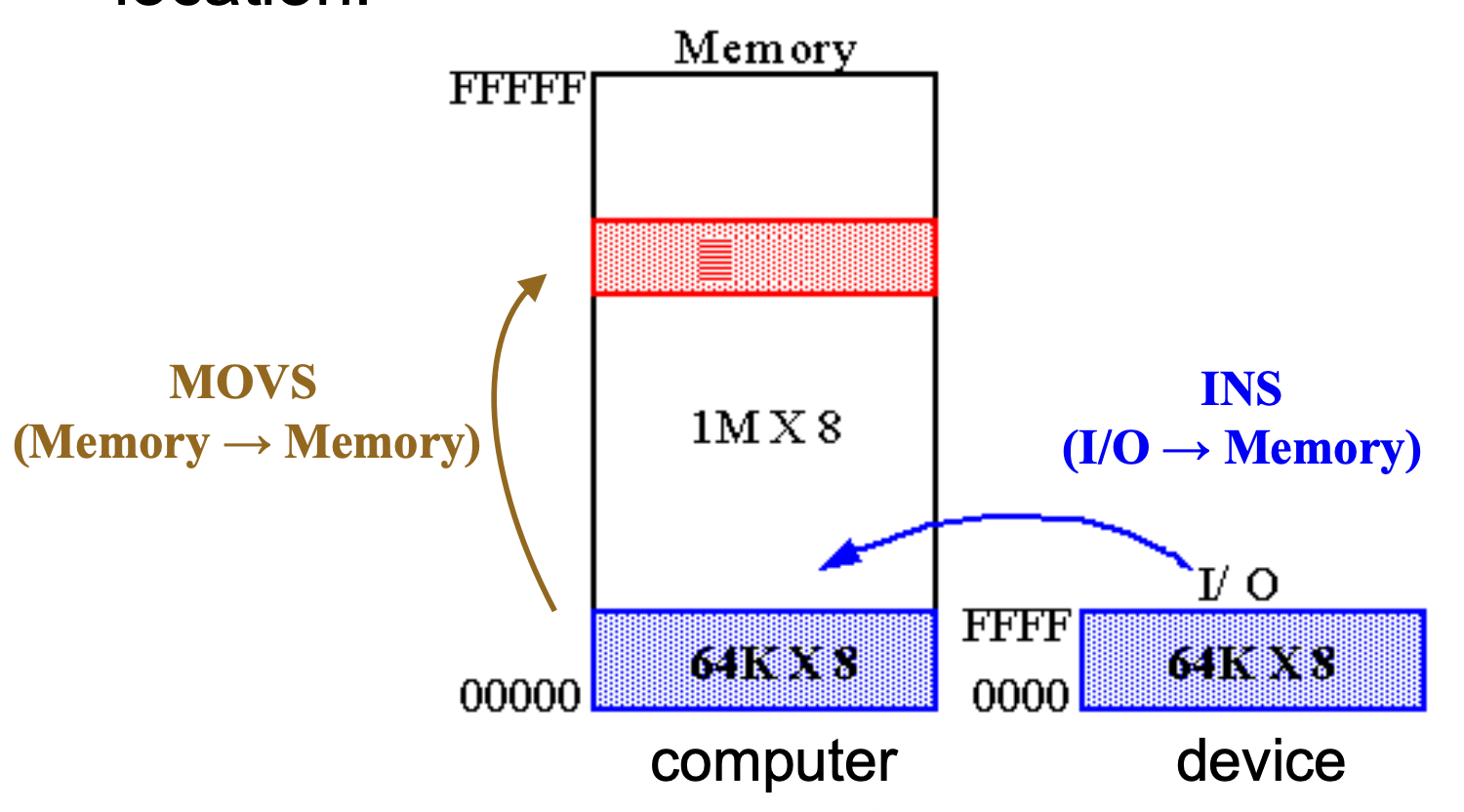
- 使用
DX或EDX作为源操作数来指定 I/O 地址或 I/O 端口 - 目标操作数是由
ES:DI或ES:EDI寻址的内存位置 -
指令的两种形式:
-
显式操作数形式(explicit-operands form):允许显式指定源操作数和目的操作数
- 例如,
INS WORD PTR [DI], DX
- 例如,
-
无操作数形式(no-operands form) 提供了
INS指令的字、字和双字版本的“简短形式”INSB:输入 8 位 I/O 数据,并将其存储在由DI索引的内存位置INSW:输入 16 位 I/O 数据,并将其存储在字大小的内存位置INSD:输入 32 位 I/O 数据,并将其存储在双字大小的内存位置- 这些指令可以使用
REP前缀重复使用,允许将整个输入数据块从 I/O 设备存储到内存中
-
例子
以下指令序列从 I/O 设备(其 I/O 端口为 03ACH)输入 50 字节的数据,并将数据存储在额外段内存数组 LISTS 中:
OUTS⚓︎
OUTS 指令将一个字节、字或双字数据从数据段内存地址传输到 I/O 设备中。
- 源操作数是一个由
DS:SI或DS:ESI寻址的内存位置 - 目标操作数(I/O 地址或 I/O 端口)包含在
DX寄存器中,与INS指令相同
同样存在两种形式的指令:
-
显式操作数形式:允许显式指定源操作数和目的操作数,例如
OUTS DX, WORD PTR [SI]- 源操作数应为
DS:SI或DS:ESI,而目的操作数必须是DX
- 源操作数应为
-
无操作数形式:提供了
OUTS指令的字节、字和双字版本的“简短形式”OUTSB:将SI索引的字节数据输出到 8 位 I/O 设备OUTSW:将字大小的内存数据输出到 16 位 I/O 设备OUTSD:将双字大小的内存数据输出到 32 位 I/O 设备
注意
在 64 位模式下,没有 64 位的输出;但有 64 位的内存地址,位于 RDI。
例子
以下指令序列将数据从数据段内存数组(ARRAY)传输到 I/O 地址为 3ACH 的 I/O 设备中:
Miscellaneous Data Transfer Instructions⚓︎
XCHG⚓︎
XCHG 指令是一种具有双输出的罕见指令。它的作用是将寄存器的内容与任何其他寄存器或内存位置交换,但不能和段寄存器交换,或者交换内存到内存的数据。
- 交换的数据可以是字节、字、双字或四字,并且可以使用除立即寻址以外的任何寻址模式
- 当使用内存寻址模式和汇编器时,哪个操作数寻址内存无关紧要,例如
XCHG AL, [DI]与XCHG [DI], AL相同 - 其中使用 16 位
AX寄存器与另一个 16 位寄存器进行XCHG操作,是最有效的交换;此指令占用 1 个字节的内存 - 该指令不会改变任何标志位
下表展示了各种 XCHG 指令的形式:
| 汇编语言 | 操作 |
|---|---|
XCHG AL, CL |
交换 AL 和 CL 的内容 |
XCHG CX, BP |
交换 CX 和 BP 的内容 |
XCHG EDX, ESI |
交换 EDX 和 ESI 的内容 |
XCHG AL, DATA2 |
交换 AL 和数据段内存位置 DATA2 的内容 |
XCHG RBX, RCX |
交换 RBX 和 RCX 的内容(64 位模式) |
另外,XCHG 对于实现进程同步中的信号量(semaphore) 很有用。
例子
LAHF and SAHF⚓︎
-
LAHF指令将EFLAGS寄存器的低 8 位传输到AH寄存器-
AH := EFLAGS(SF:ZF:0:AF:0:PF:1:CF)- 包括:符号标志(
SF) 、零标志(ZF) 、辅助进位标志(AF) 、奇偶标志(PF)和进位标志(CF) EFLAGS的保留位(第 1、3 和 5 位)被分别设置为 1、0 和 0
- 包括:符号标志(
-
如果
CPUID.80000001H:ECX.LAHF - SAHF[bit 0] = 1,则LAHF指令在 64 位模式下可用
-
-
SAHF指令将AH寄存器对应位(分别对应位 7、6、4、2 和 0)的值传输给EFLAGS寄存器的SF、ZF、AF、PF标志- 忽略
AH寄存器的第 1、3 和 5 位,直接将EFLAGS寄存器中的这些位分别设置为 1、0 和 0 - 如果
CPUID.80000001H:ECX.LAHF - SAHF[bit 0] = 1,则SAHF指令在 64 位模式下可用
- 忽略
XLAT⚓︎
XLAT(表查找转换(table look-up translation))指令
-
使用隐式操作数
AL,BXAL作为输入时表示的是相对表([BX])的偏移量,而作为输出时将该位置的表内容([BX + AL])复制到AL寄存器中seg:[BX]是表的基址;默认段为DS,它可能被段前缀重写
-
该指令等价于
MOV AL, [seg:BX + AL],但需要注意[seg:BX + AL]不是一个合法的内存操作数,只有XLAT会接受它 - 该指令常用于将一种格式的数据翻译成另一种格式,下面以“把菜单中食物的索引转换为食物的价格”为例:
- 首先,为包含价格的表预留 256 字节
- 然后,使用该表的地址加载
DS:BX,并将食物的索引放入AL上 - 接着
XLAT把表中的索引转换为价格
例子
假设一个 7 段 LED 显示器查找表存储在地址 TABLE 的内存中。XLAT 指令使用查找表将 AL 中的 BCD 数字转换为 AL 中的 7 段编码。
TABLE DB 3FН, 06H, 5BH, 4FH ; lookup table (7-segment code)
DB 66H, 6DH, 7DH, 27H
DB 7FH, 6FH
LOOK: MOV AL, 5 ; load AL (BCD number) with 5 (a test number)
MOV BX, OFFSET TABLE ; address lookup table
XLAT ; convert
下图展示了上述示例程序在 TABLE = 1000H,DS = 1000H,以及 AL 的初始值为 05H(BCD)时的操作。转换后,AL = 6DH。
IN and OUT⚓︎
输入和输出端口
如屏幕、显示器、键盘、鼠标、硬盘和网络等外部设备通过输入端口(input ports) 和输出端口(output ports) 连接到数据总线。每个输入或输出端口都有一个唯一的地址,就像内存中的每个字节单元都有一个唯一的地址一样。
-
输出端口
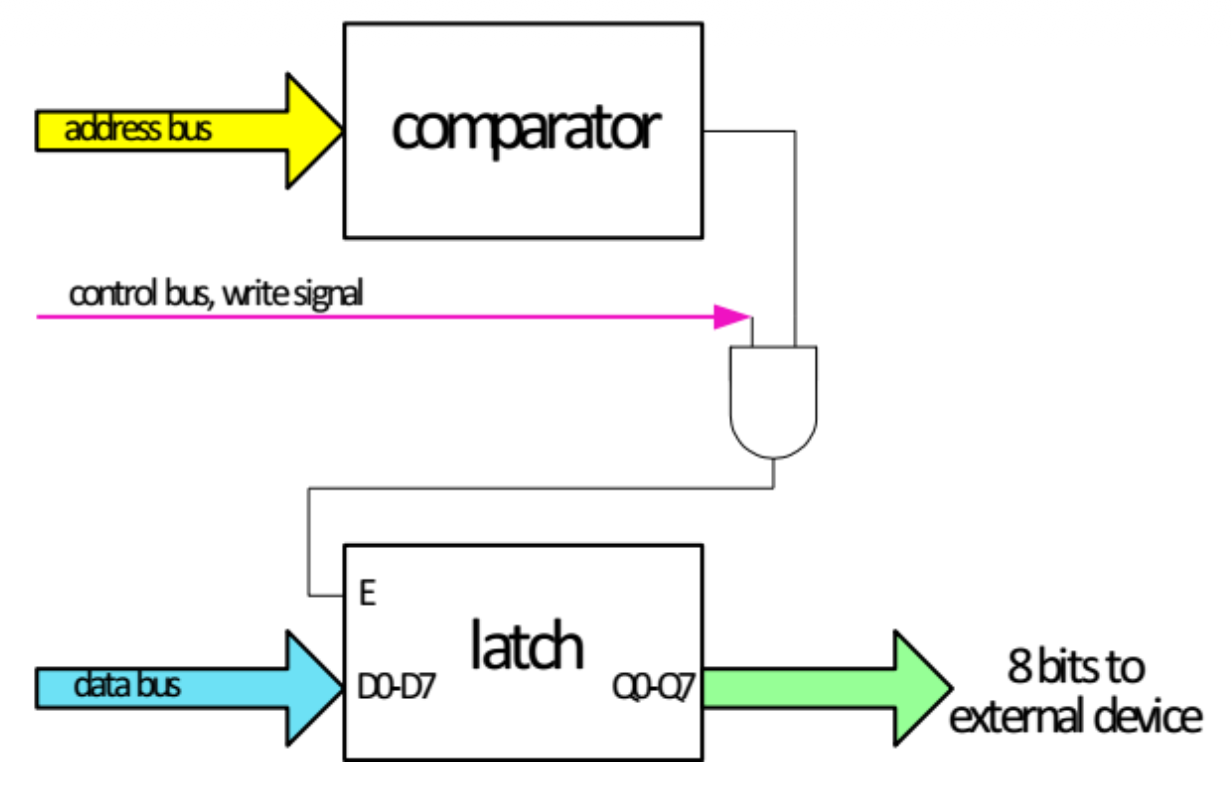
- 输出端口有一个比较器(comparator),该比较器比较固定地址与地址总线上的值
- 如果地址等于端口地址,且控制总线上有写信号,锁存器(latch) 将存储数据总线上的值
-
输入端口
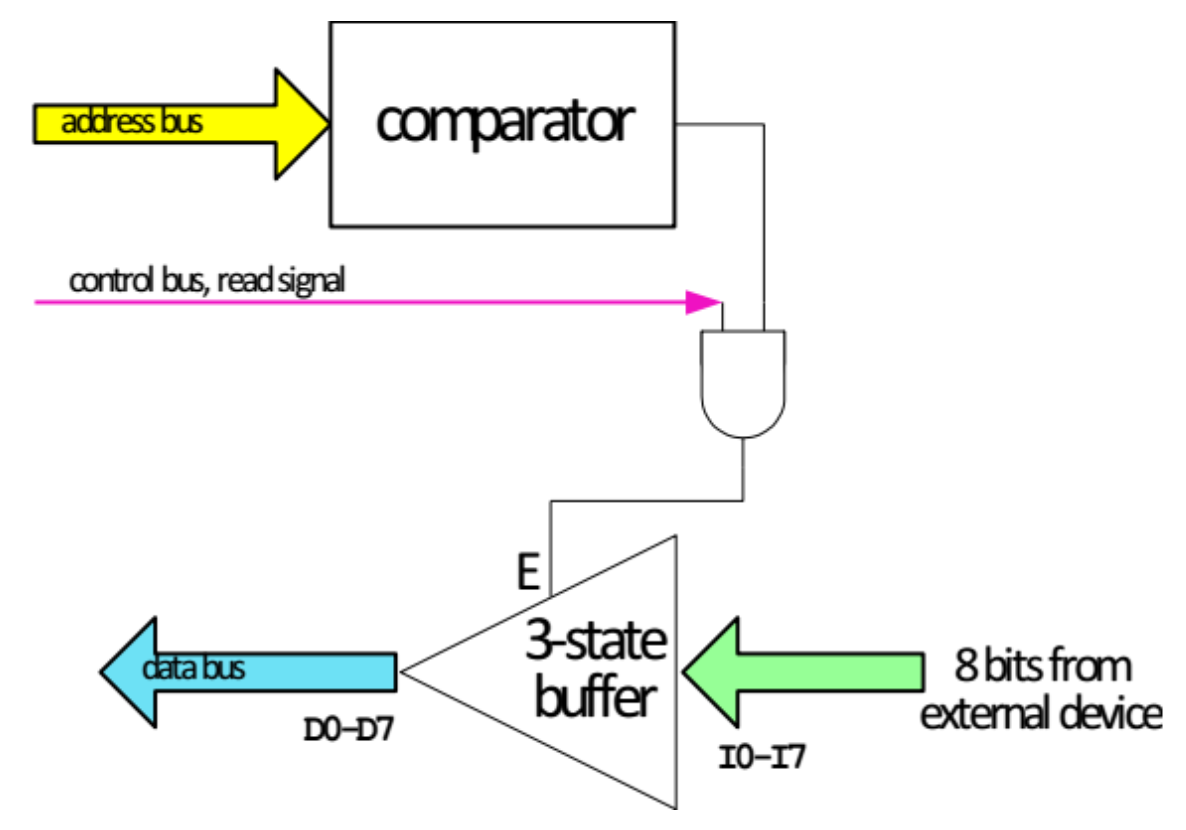
- 每个来自外部设备的输入都经过一个三态缓冲器(three-state buffer) 到达数据总线
- 当地址总线等于输入端口的固定地址,且控制总线上有读信号时,三态缓冲器被启用
IN 和 OUT 指令执行 I/O 操作。
-
仅允许
AL、AX或EAX的内容在 I/O 设备和微处理器之间传输IN:将外部 I/O 设备的数据传输到AL、AX或EAX,例如IN AL, 19HOUT:将AL、AX或EAX的数据传输到外部 I/O 设备,例如,OUT 32H, AX
-
不会改变任何标志位
- 在 I/O 操作期间,端口地址出现在地址总线(address bus) 上
- I/O 设备(端口)的寻址方式分为以下两类:
- 固定端口寻址(fixed-port addressing):使用 8 位 I/O 端口地址在
AL、AX或EAX之间进行数据传输,例如IN AL, 12H,OUT 25H, AX- 端口号是紧随指令操作码之后的字节立即值(
00h至FFh)
- 端口号是紧随指令操作码之后的字节立即值(
- 可变端口寻址(variable-port addressing):在
AL、AX或EAX与 16 位端口地址之间进行数据传输,例如IN AL, DX,OUT DX, AX- I/O 端口号存储在寄存器
DX(0000h至FFFFh)中,可以在程序执行过程中改变
- I/O 端口号存储在寄存器
- 固定端口寻址(fixed-port addressing):使用 8 位 I/O 端口地址在
例子
下图展示了 OUT 19H, AX 指令的执行过程(将 AX 的内容传输到 I/O 端口 19H
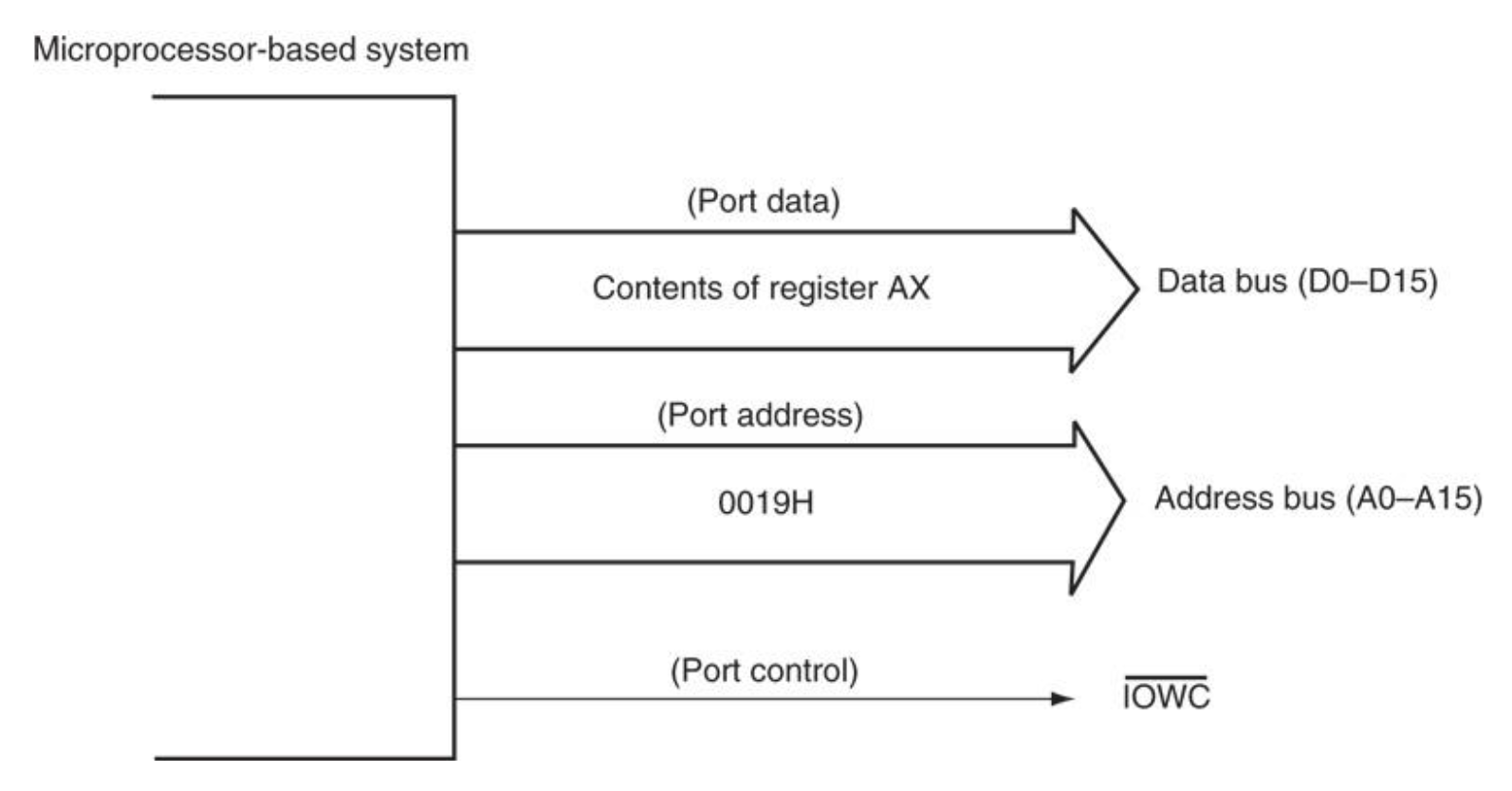
OUT指令中使用的源寄存器决定了端口的大小(8 位、16 位或 32 位)
下表展示了各种形式下的 IN 和 OUT 指令:
| 汇编语言 | 操作 |
|---|---|
IN AL, p8 |
8 位数据从 I/O 端口 p8 输入到 AL |
IN AX, p8 |
16 位数据从 I/O 端口 p8 输入到 AX |
IN EAX, p8 |
32 位数据从 I/O 端口 p8 输入到 EAX |
IN AL, DX |
8 位数据从 I/O 端口 DX 输入到 AL |
IN AX, DX |
16 位数据从 I/O 端口 DX 输入到 AX |
IN EAX, DX |
32 位数据从 I/O 端口 DX 输入到 EAX |
OUT p8, AL |
8 位数据从 AL 输出到 I/O 端口 p8 |
OUT p8, AX |
16 位数据从 AX 输出到 I/O 端口 p8 |
OUT p8, EAX |
32 位数据从 EAX 输出到 I/O 端口 p8 |
OUT DX, AL |
8 位数据从 AL 输出到 I/O 端口 DX |
OUT DX, AX |
16 位数据从 AX 输出到 I/O 端口 DX |
OUT DX, EAX |
32 位数据从 EAX 输出到 I/O 端口 DX |
注:
p8= 8 位 I/O 端口号(0000H到00FFH) ,DX= 存储在寄存器DX中的 16 位 I/O 端口号(0000H到FFFFH) 。
例子
下面是一个点击电脑中扬声器的程序。扬声器(仅在 DOS 中)通过访问 I/O 端口 61H 进行控制。如果先设置该端口最低两位(11
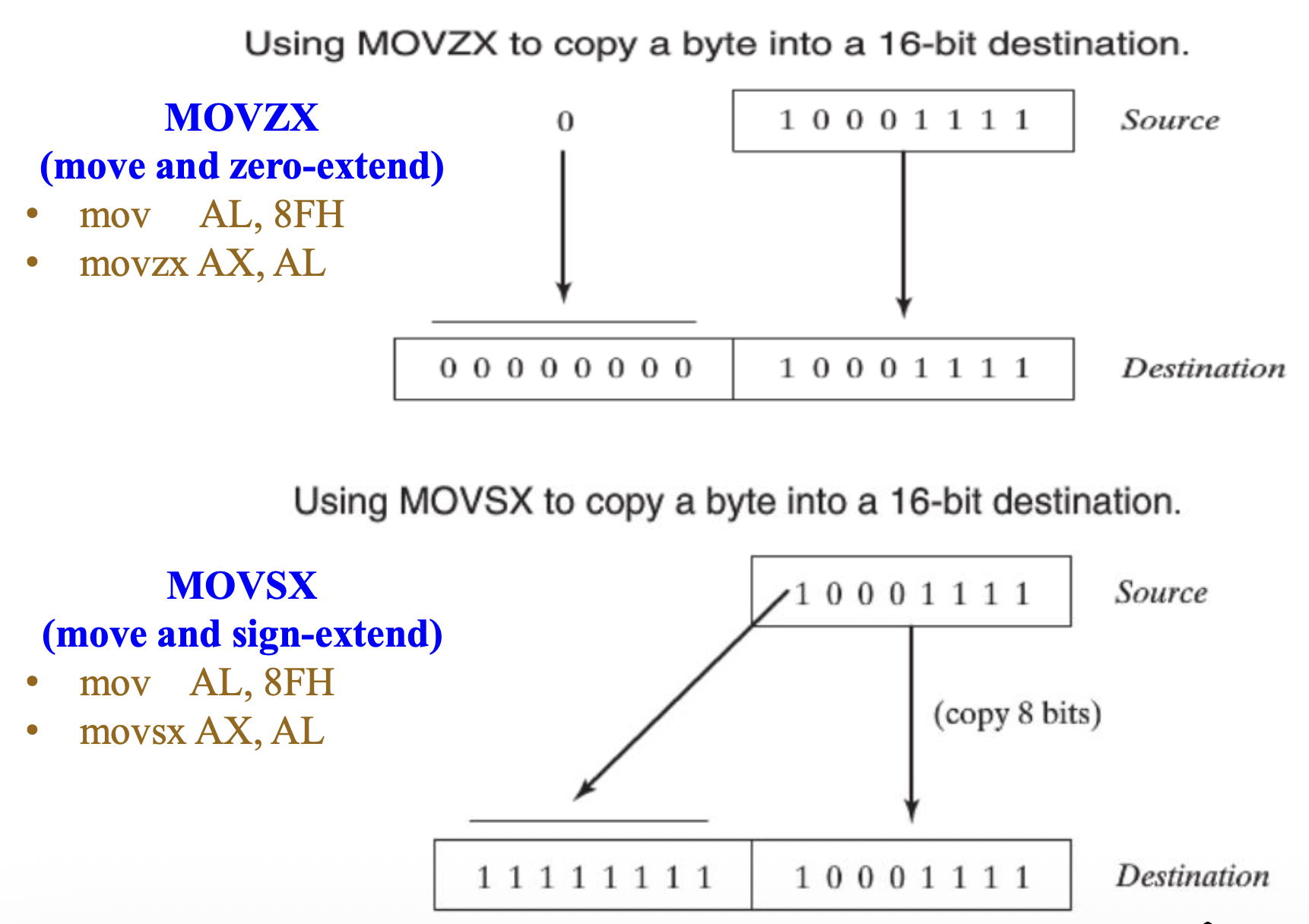
MOVSX and MOVZX⚓︎
MOVZX(移动和零扩展(move and zero-extend))和 MOVSX(移动和符号扩展(move and sign-extend))指令存在于 80386 及之后的处理器的指令集中。下图展示了这两条指令的操作细节:
下表展示了各种形式下的 MOVZX 和 MOVSX 指令:
| 汇编语言 | 操作 |
|---|---|
MOVSX CX, BL |
将 BL 进行符号扩展到 CX 中 |
MOVSX ECX, AX |
将 AX 进行符号扩展到 ECX 中 |
MOVSX BX, DATA1 |
将 DATA1 处的字节数据进行符号扩展到 BX 中 |
MOVSX EAX, [EDI] |
将由 EDI 地址的数据段内存位置处的字数据进行符号扩展到 EAX 中 |
MOVSX RAX, [RDI] |
将地址 RDI 处的双字数据进行符号扩展到 RAX 中(64 位模式) |
MOVZX DX, AL |
将 AL 进行零扩展到 DX 中 |
MOVZX EBP, DI |
将 DI 进行零扩展到 EBP 中 |
MOVZX DX, DATA2 |
将 DATA2 处的字节数据进行零扩展到 DX 中 |
MOVZX EAX, DATA3 |
将 DATA3 处的字数据进行零扩展到 EAX 中 |
MOVZX RBX, ECX |
将 ECX 进行零扩展到 RBX 中 |
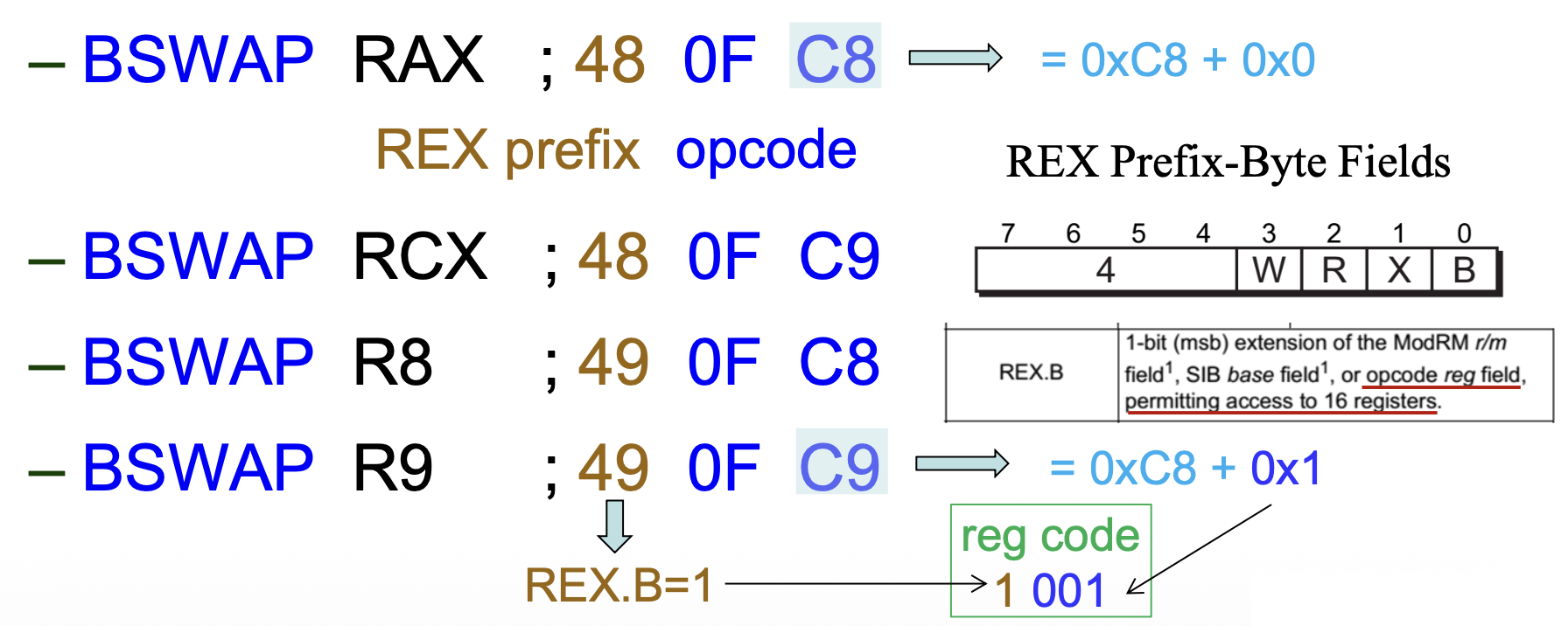
BSWAP⚓︎
BSWAP(字节交换(byte swap))指令反转 32 位或 64 位寄存器操作数的字节顺序,可用于在大小端形式之间转换数据。
-
32 位:取出 32 位寄存器的内容,将第一个字节与第四个字节交换,第二个字节与第三个字节交换
-
64 位:位 7:0 与位 63:56 交换,位 15:8 与位 55:48 交换,位 23:16 与位 47:40 交换,位 31:24 与位 39:32 交换
- 注意:64 位模式下的指令的默认操作数大小为 32 位,需要使用
REX前缀来访问额外的 64 位寄存器(R8-R15)
- 注意:64 位模式下的指令的默认操作数大小为 32 位,需要使用
| 指令 | 操作码 | 描述 |
|---|---|---|
BSWAP reg32 |
0F C8 + rd |
反转一个 32 位寄存器中的字节顺序 |
BSWAP reg64 |
REX.W + 0F C8 + rd |
反转一个 64 位寄存器中的字节顺序 |
例子
在上表“操作码”列中,+ rd 表示操作码字节低 3 位用于编码无 modR/M 字节的寄存器操作数,例如:
注意
对 16 位寄存器应用 BSWAP 指令的结果是未定义的。所以要想交换 16 位寄存器的字节,请使用 XCHG 指令。例如要交换 AX 寄存器的字节,请使用 XCHG AL, AH 指令。
CMOV⚓︎
CMOVcc 类型的指令在 EFLAGS 寄存器(CF、OF、PF、SF 和 ZF)的状态标志处于指定状态(或条件)时执行移动操作。每条指令都与一个条件码(condition code, cc) 相关联,以指示正在测试的条件。
- 只有在条件为真时才移动数据
- 如果条件不满足,则不执行移动,并且继续执行
CMOVcc指令之后的指令 - 目标操作数仅限于 16 位、32 位或 64 位寄存器,但源操作数可以是 16 位、32 位或 64 位寄存器或内存位置
- 由于这是一条新指令,除非在程序中添加了
.686开关,否则汇编器无法使用它
下表罗列了各种条件移动指令:
| 汇编语言 | 测试的标志位 | 操作 |
|---|---|---|
CMOVB |
C = 1 |
如果低于则移动 |
CMOVAE |
C = 0 |
如果高于或等于则移动 |
CMOVBE |
Z = 1 or C = 1 |
如果低于或等于则移动 |
CMOVA |
Z = 0 and C = 0 |
如果高于则移动 |
CMOVE 或 CMOVZ |
Z = 1 |
如果相等则移动,或如果为零则移动 |
CMOVNE 或 CMOVNZ |
Z = 0 |
如果不相等则移动,或如果不为零则移动 |
CMOVL |
S != O |
如果小于则移动 |
CMOVLE |
Z = 1 or S != O |
如果小于或等于则移动 |
CMOVG |
Z = 0 and S = O |
如果大于则移动 |
CMOVGE |
S = O |
如果大于或等于则移动 |
CMOVS |
S = 1 |
如果有符号(负数)则移动 |
CMOVNS |
S = 0 |
如果无符号(正数)则移动 |
CMOVC |
C = 1 |
如果进位则移动 |
CMOVNC |
C = 0 |
如果无进位则移动 |
CMOVO |
O = 1 |
如果溢出则移动 |
CMOVNO |
O = 0 |
如果无溢出则移动 |
CMOVPE 或 CMOVPE |
P = 1 |
如果奇偶校验成立则移动,或如果奇偶校验为偶数则移动 |
CMOVNP 或 CMOVPO |
P = 0 |
如果无奇偶校验则移动,或如果奇偶校验为奇数则移动 |
这类指令的设计目的在于避免分支:
-
当 CPU 看到分支(比如
JNE)时,它将猜测分支是否会被执行,然后开始推测性地执行指令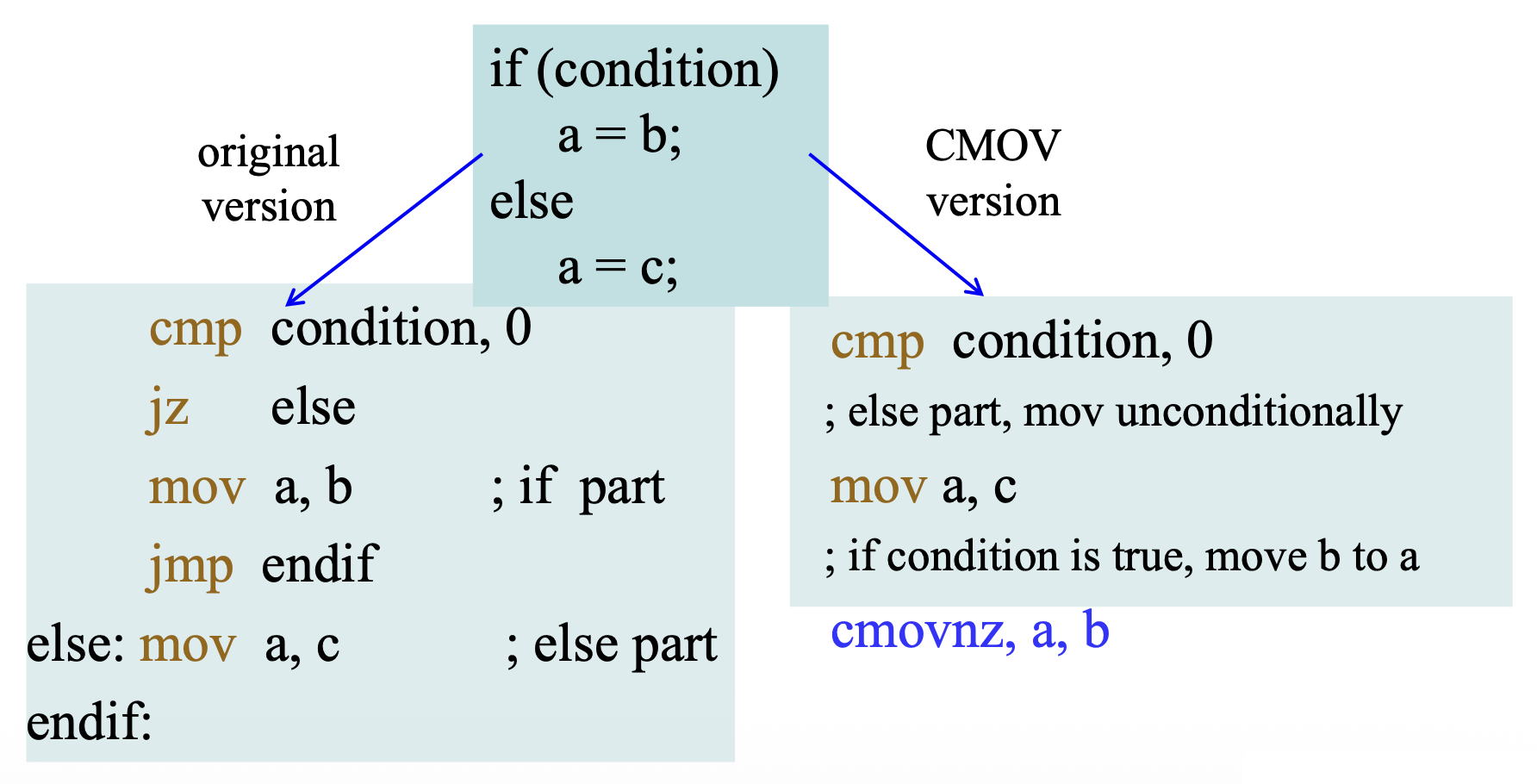
-
如果猜测错误,会有性能损失,因为 CPU 必须丢弃任何先前通过推测执行的工作,然后开始获取和执行正确的路径
-
而对于条件移动(例如
CMOVE eax, edx) ,CPU 不需要猜测哪段代码将被执行,从而避免了预测错误的分支成本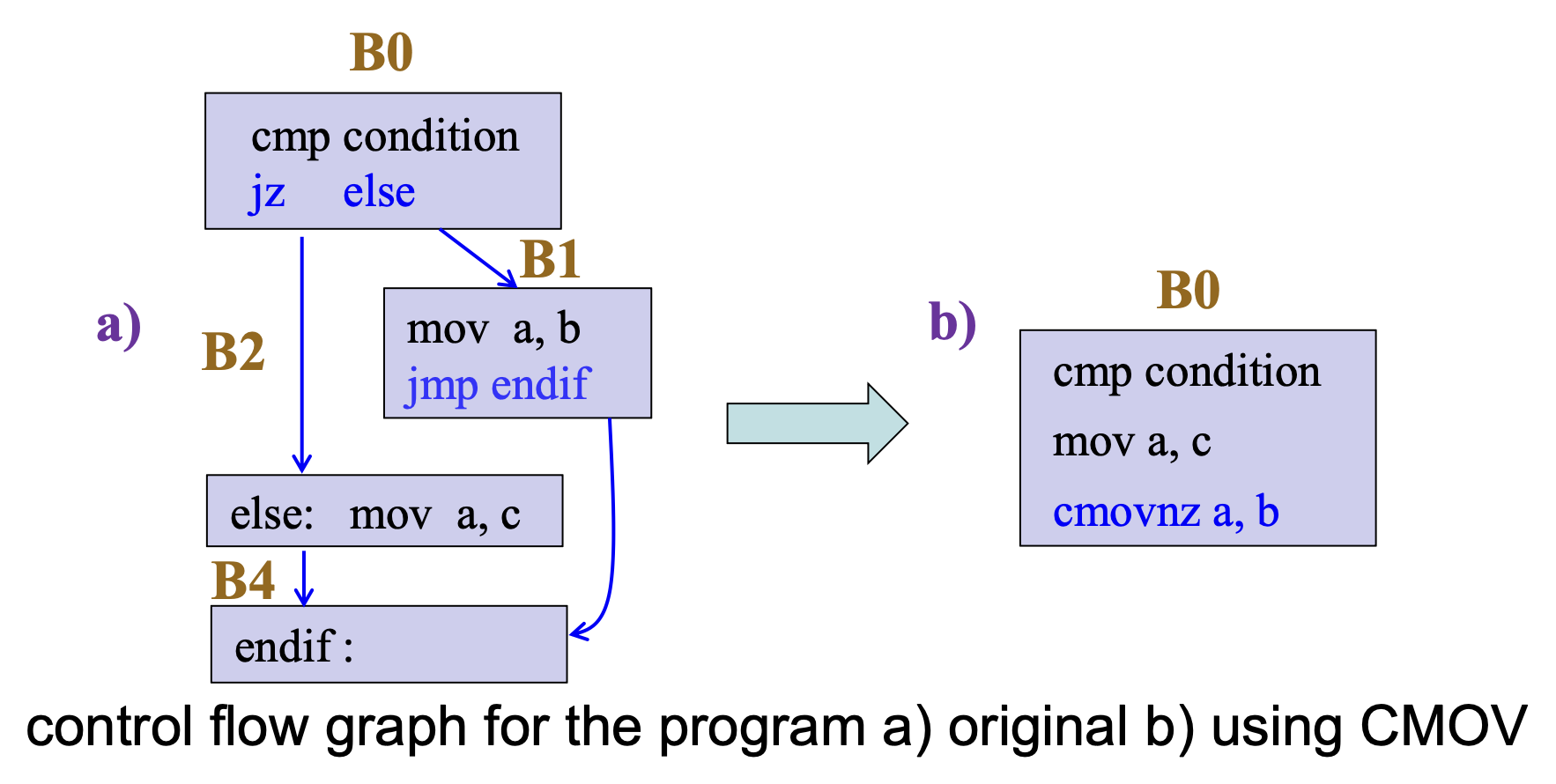
-
此外,
CMOVcc指令将控制依赖转换为数据依赖,并将多个路径中的指令合并到基本块中,这使得基本块包含更多指令,并扩展了指令调度空间
Assembler Details⚓︎
可以通过两种方式使用汇编器(assembler):
- 使用对特定汇编器而言独有的模型
- 使用全段定义,允许对汇编过程进行完全控制,并且对所有汇编器通用
本节将介绍这两种方法,并解释如何通过使用汇编器来组织程序的内存空间,以及一些与汇编器一起使用的重要指令的目的和用法。
Directives vs Instructions⚓︎
汇编语言语句包括伪指令和指令两类:
-
伪指令(directive):告诉汇编器如何做
- 生成机器代码,分配存储等
- 仅在汇编时使用,自身不会产生任何代码
-
指令(instruction):告诉 CPU 做什么
- 编译成机器代码,最终链接到最终的可执行代码中
- 在运行时由 CPU 执行
Directives in MASM⚓︎
MASM 的伪指令能够指示汇编器如何处理操作数或程序的一部分。一些伪指令会生成信息并将其存储在内存中,另一些则不会。
- 数据分配:
DB,DW,DD,DQ,DT - 过程:
PROC,ENDP - 结构:
STRUCT,RECORD - 宏:
MACRO,ENDM - 代码标签:
ALIGN,ORG - 杂项:
EQU,INCLUDE - 段:
SEGMENT,ENDS,ASSUME - 处理器:
.386,.486,.586 - 简化段:
.CODE,.DATA,.STACK,.MODEL,.EXIT
更多伪指令请参考:https://docs.microsoft.com/en-us/cpp/assembler/masm/directives-reference?view=msvc-160
Storing Data in Memory Segment⚓︎
MASM 中用于定义和存储内存数据的伪指令有:
DB:定义字节(define byte)DW:定义字(define word)DD:定义双字(define doubleword)
如果一个数值协处理器 (numeric coprocessor) 在系统中执行软件,那么还有 DQ(定义四字)和 DT(定义十字节)伪指令可用。这些伪指令使用符号名称标记内存位置并指示其大小。
另外,DUP 伪指令允许对相同值进行多次初始化,例如:DATA1 DB 0, 0, 0, 0, 0 等价于 DATA2 DB 5 DUP(0) ; reserves 5 bytes of 0。
使用问号(?)作为 DB、DW 等伪指令的操作数来为内存预留空间。汇编器会预留一个位置,不会将其初始化为任何特定值。
ALIGN 指令将下一个数据元素或指令对齐到参数的倍数地址,该参数必须是小于或等于段对齐 (segment alignment) 的 2 的幂。
例子
LIST_SEG SEGMENT
DATA1 DB 1,2,3 ; define bytes
DB 45H ; hexadecimal
DATA3 DD 300H ; define doubleword
DD 2.123 ; real
DD 3.34E+12 ; real
LISTA DB ? ; reserve 1 byte
LISTB DB 10 DUP (?) ; reserve 10 bytes
ALIGN 2 ; set word boundary
LISIC DW 100H DUP (0) ; reserve 100H words
LISTD DD 22 DUP (?) ; reserve 22 doublewords
值得注意的是,字大小的数据应放置在字边界上,而双字大小的数据应放置在双字边界上;否则微处理器将花费额外的时间来访问这些数据类型。
思考
请确定指令执行后寄存器 AX 的值。

ASSUME, EQU and ORG⚓︎
-
EQU- 相等伪指令(
EQU)将数字、ASCII 或标签等价于另一个标签,用于定义常量 - 语法:
CONSTANT_NAME EQU expression -
等价指令使程序更清晰并简化调试,例如:
- 相等伪指令(
-
THIS:- 编译器只能将字节、字或双字地址分配给标签
- 要将字节标签分配给字,使用
THIS伪指令 THIS指令始终以THIS BYTE、THIS WORD、THIS DWORD或THIS QWORD的形式出现
-
ORGORG(origin)语句可以改变数据段或代码段中数据的起始偏移地址- 有时,数据或代码的源必须使用
ORG语句分配给一个绝对偏移地址,例如引导扇区入口必须分配给07c00h
-
ASSUME告诉汇编器代码、数据、附加和栈段已选择的名字- 代码段的首条伪指令就要用
ASSUME
- 代码段的首条伪指令就要用
例子
; Using the THIS and ORG directives
DATA_SEG SEGMENT
ORG 300H ; (1)
DATA1 EQU THIS BYTE ; (2)
DATA2 DW ?
DATA_SEG ENDS
CODE_SEG SEGMENT 'CODE' ; (3)
ASSUME CS: CODE_SEG, DS: DATA_SEG
MOV BL, DATA1
MOV AX, DATA2
MOV BH, DATA1+1
CODE_SEG ENDS
- 使用
ORG伪指令设置位置 - 使用
THIS伪指令将一个字地址标签赋给一个字节标签 - 使用
SEGMENT伪指令定义一个程序段
PROC and ENDP⚓︎
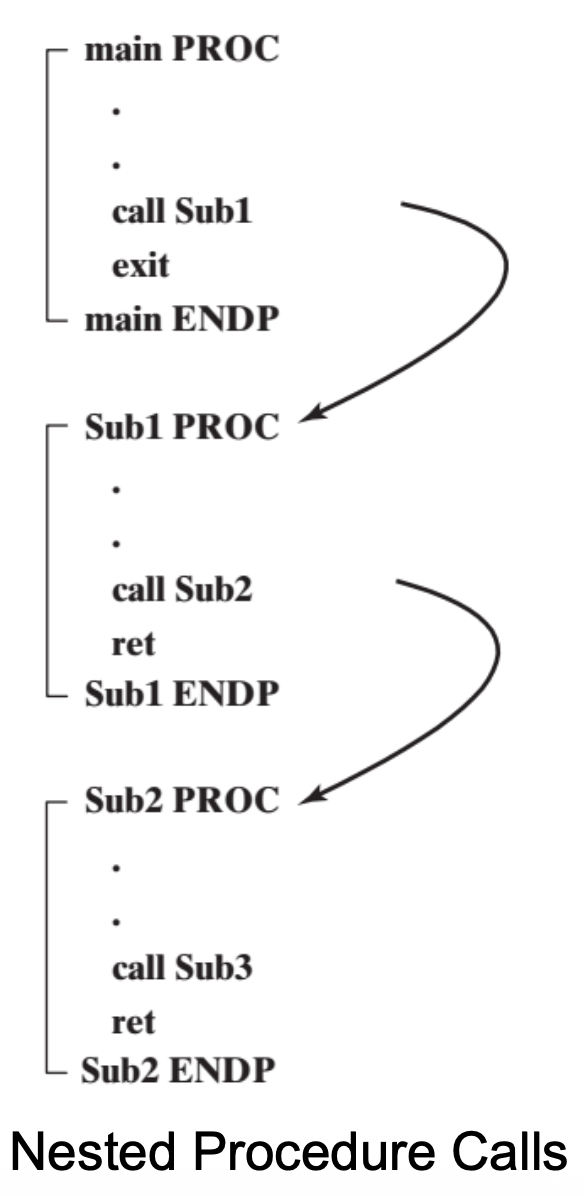
PROC 和 ENDP 伪指令表示一个必须赋予名称的过程(procedure)(子程序(subroutine))的开始和结束。
PROC 伪指令可以跟随 NEAR 或 FAR(后者仅在 32 位系统中有效)
NEAR过程是指位于程序相同代码段中的过程,通常被认为是局部的FAR过程可能位于内存系统的任何位置,被认为是全局的
例子
下面有一个名为 SumOf 的过程,它通过传递寄存器参数来计算三个 32 位整数的和。
- 将三个整数赋给
EAX、EBX、ECX - 该过程用
EAX返回和
.data
theSum DWORD ?
.code
main PROC
; Before calling SumOf, values are assigned to EAX, EBX, and ECX
mov eax, 10000h ; argument
mov ebx, 20000h ; argument
mov ecx, 30000h ; argument
call Sumof ; EAX = (EAX + EBX + ECX)
; After the CALL, the sum in EAX are copied to “theSum” variable
mov theSum, eax ; save the sum
main ENDP
MACRO and ENDM⚓︎
MACRO和ENDM伪指令表示一个宏(macro)(一个具名的汇编语言语句块)- 调用一个宏过程时,它的代码副本将直接插入到程序中被调用的位置
- 这种类型的自动代码插入也称为内联展开(inline expansion)
例子
一个名为 mPutchar 的宏接收一个输入,并通过调用 WriteChar 将其显示在控制台上。
mPutchar MACRO char
push eax
mov al, char ; passing arguments to the procedure
call WriteChar
pop eax
ENDM
- 语句
mPutchar 'A'调用mPutchar并传递字母A - 汇编器的预处理器将该语句扩展为以下代码:
宏也可以在数据段中使用,比如为 GDT 描述符定义一个宏。
例子

INCLUDE⚓︎
INCLUDE 伪指令用于在汇编过程中将给定文件名的源代码插入到当前源文件中。
语法:INCLUDE filename

Memory Organization⚓︎
内存组织(memory organization) 定义了软件的内存相关属性,包括代码大小、数据指针、指令编码、段组合类型和段加载顺序等。汇编器使用两种基本格式来定义内存组织:
- 一种方法使用全段定义(full-segment definitions):提供了对汇编语言任务的更好的控制,建议用于复杂程序
- 另一种方法使用模型(models)
- MASM 汇编器提供了许多内存模型可供选择,从小型到大型不等,这些模型控制着段寄存器的使用方式和指针的默认大小
- 使用
.MODEL指令来确定代码和数据指针的大小
Full-Segment Definitions⚓︎
全段定义使用 SEGMENT、ENDS 和 ASSUME 指令来定义段,并通知汇编器和链接器。
name SEGMENT [readonly] [align] [combine] [use] ['combine-class']
statements
name ENDS
cseg SEGMENT readonly word use32 'code'
mov ax, 10
inc ax
ret
cseg ENDS
Processor Directive VS Segment Attribute⚓︎
- 处理器伪指令(例如,
.286、 .386)隐式定义默认操作模式 - 段属性(segment attributes)(
use16/use32)显式指定局部段内的操作模式,允许它重写默认模式 -
逻辑上必须匹配,例如:
.286-> 应与use16一起使用.386-> 可与use16或use32一起使用
-
它们共同工作以实现灵活的模式切换,例如混合 16 位和 32 位操作模式
Controlling Segments with the ASSUME Directive⚓︎
- 段伪指令不说明段类型,而
ASSUME伪指令为汇编器提供此信息 -
形式如下:
-
有效的
ASSUM伪指令使用示例:ASSUME DS:DSEGASSUME CS:CSEG, DS:DSEG, ES:DSEG, SS:SSEGASSUME CS:CSEG, DS:NOTHING
-
当汇编器遇到一条指令(例如
MOV var, 0)时,它首先做的是确定var的段 - 如果
var没有在当前假设的任何一个段中声明,那么汇编器将生成一个错误,声称程序无法访问该变量 - 将
ASSUME伪指令放在程序中所有过程之前是理想的位置,因为程序中声明为段的段指针很少改变(除了过程入口和出口处)
END⚓︎
END伪指令用于通知汇编器某个模块的结束- 通常,每个源模块都将有一个
END语句作为模块的最后一行;只有一个模块可以有一个这种形式的END语句 END指令还可以设置程序的入口点(entry point)- 语法:
END label- 比如:
END start,此时它指定标签start是程序的入口点,DOS 将在该地址开始执行程序
- 比如:
例子

Models⚓︎
- 内存模型是 MASM 独有的
.MODEL伪指令包括 MASM 实模式下六个内存模型,即tiny、small、compact、medium、large和huge- 对于保护模式,还可使用
flat模型 - 使用如
@DATA、@STACK、@CODE的特殊伪指令来识别各种段 .MODEL不用于 x64 的 MASM
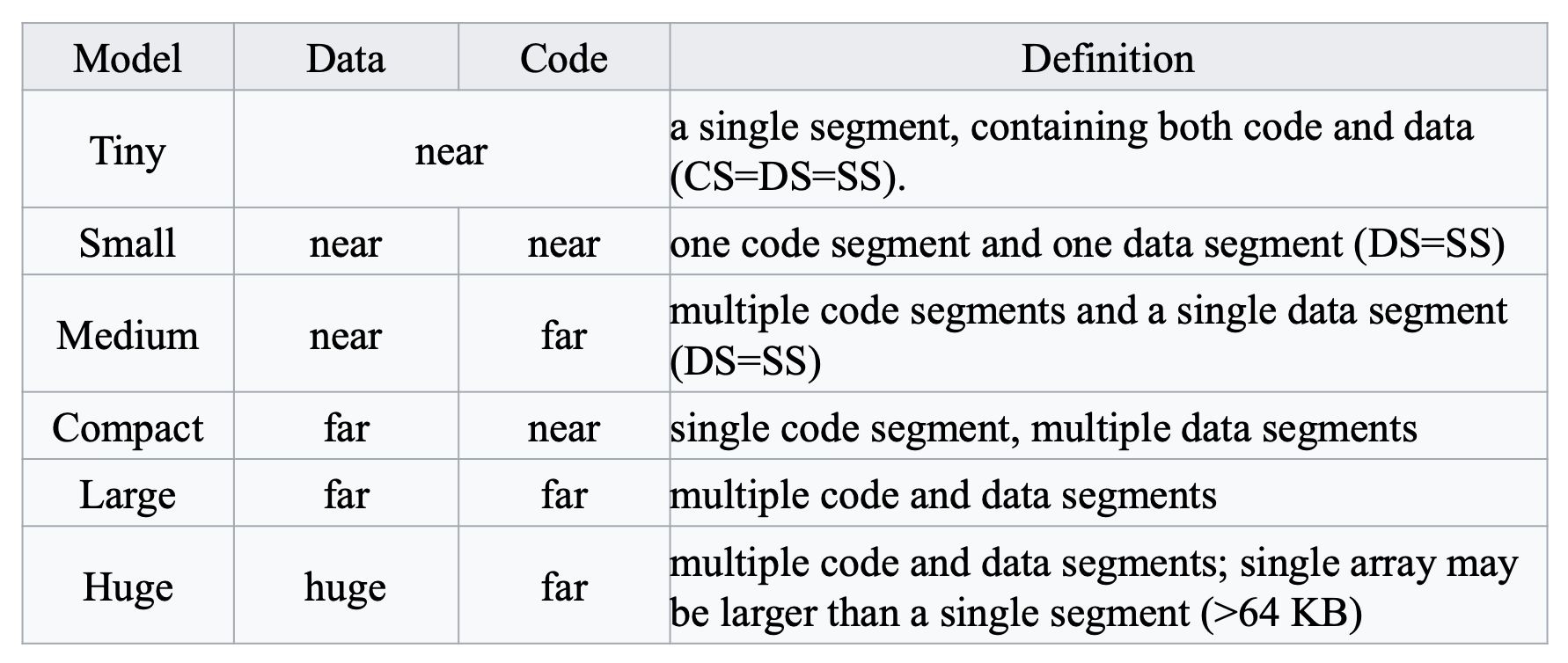
选择可容纳数据和代码的最小内存模型,因为近引用比远引用操作更高效。
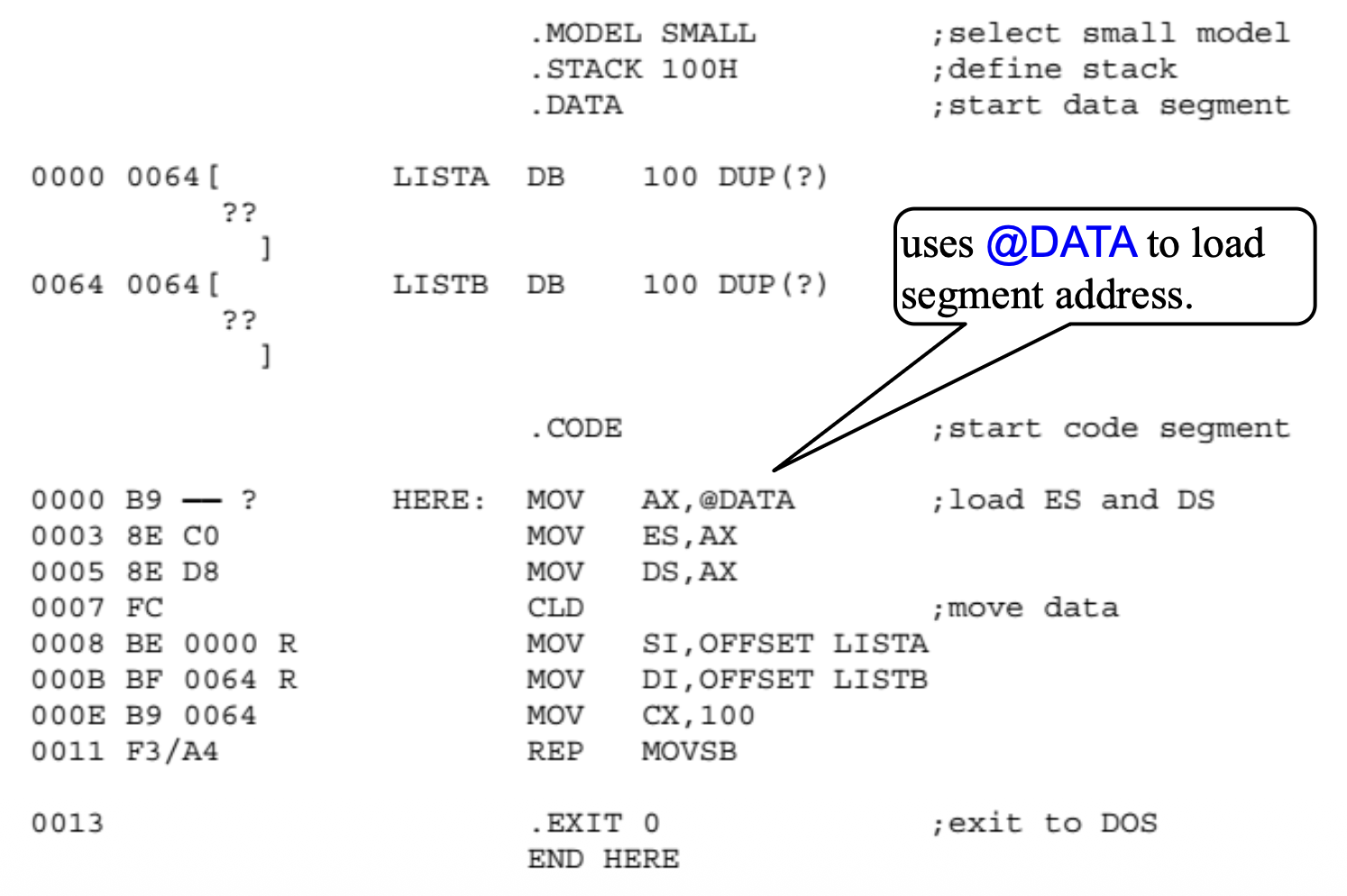
例子
以下指令序列说明了 .MODEL 语句如何定义一个短程序的参数,该程序将 100 字节内存块(LISTA)的内容复制到第二个 100 字节内存块(LISTB)中。
评论区