Arithmetic and Logic Instructions⚓︎
约 7963 个字 217 行代码 预计阅读时间 43 分钟
核心知识
-
算术指令
- 加减乘除
- 比较指令
- BCD 和 ASCII 算术指令
-
逻辑指令:
- 与、或、异或、非、移位、旋转
- 位测试
- 位扫描
-
字符串比较指令
Addition, Subtraction and Comparison⚓︎
微处理器中的算术指令主要包括加法、减法和比较。
Addition⚓︎
加法(ADD)在微处理器中以多种形式出现。但唯二不允许的加法类型是内存到内存和段寄存器(段寄存器只能移动、压栈或弹出
当执行加法指令时,标志寄存器的内容会改变。
- 具体来说,改变的位包括符号、零、进位、辅助进位、奇偶校验和溢出标志位
- 但中断、陷阱和其他标志位不会因此改变
各种加法指令:
-
立即数加法:涉及到常量和已知数据的加法
-
内存 - 寄存器加法
- 将参与加法的内存数据移动到
AL(或别的)寄存器中 -
示例:将存储在数据段偏移位置的
NUMB的两个连续字节的数据相加,结果存储在AL寄存器中
- 将参与加法的内存数据移动到
-
数组加法
-
假设一个数据数组(
ARRAY)包含 10 字节,从元素 0 编号到元素 9;下面展示了如何将数组中第 3、5 和 7 个元素的内容相加: -
假设一个数据数组的各元素以字为单位存储,用于在寄存器
AX中形成 16 位的和;下面的指令序列展示了用比例变址寻址将名为ARRAY的内存区域中的第 3、5 和 7 个元素相加ARRAY DW 0, 1, 3, 2, ... ... MOV EBX, OFFSET ARRAY ; address ARRAY MOV ECX, 3 ; address element 3 MOV AX, [EBX + 2 * ECX] ; get element 3 MOV ECX, 5 ; address element 5 ADD AX, [EBX + 2 * ECX] ; add element 5 MOV ECX, 7 ; address element 7 ADD AX, [EBX + 2 * ECX] ; add element 7EBX加载了ARRAY的地址ECX保存了数组元素编号- 比例因子用于将
ECX寄存器的内容乘以 2 以定位数据字
-
-
递增(increment) 指令(
INC)将 1 加到任何寄存器(段寄存器除外)或内存位置-
保持
CF(进位)标志的状态不变 -
作用在内存位置时,数据的大小必须通过使用
BYTE PTR,WORD PTR或DWORD PTR指令来描述,因为汇编器无法确定INC [DI]是字节大小、字大小还是双字大小的递增 -
下表总结
INC指令的各种使用场景汇编语言 操作 INC BLBL = BL + 1INC SPSP = SP + 1INC EAXEAX = EAX + 1INC BYTE PTR [BX]对 BX所寻址的数据段内存位置的字节内容加 1INC WORD PTR [SI]对 SI所寻址的数据段内存位置的字内容加 1INC DWORD PTR [ECX]对 ECX所寻址的数据段内存位置的双字内容加 1INC DATA1对数据段内存位置 DATA1的内容加 1INC RCX对 RCX加 1(64 位模式)
-
-
ADC(带进位加法 (add-with-carry))将进位标志(C)中的位加到操作数数据上- 和
ADD类似,ADC在加法后会影响标志位 -
下图展示了该指令的操作细节:
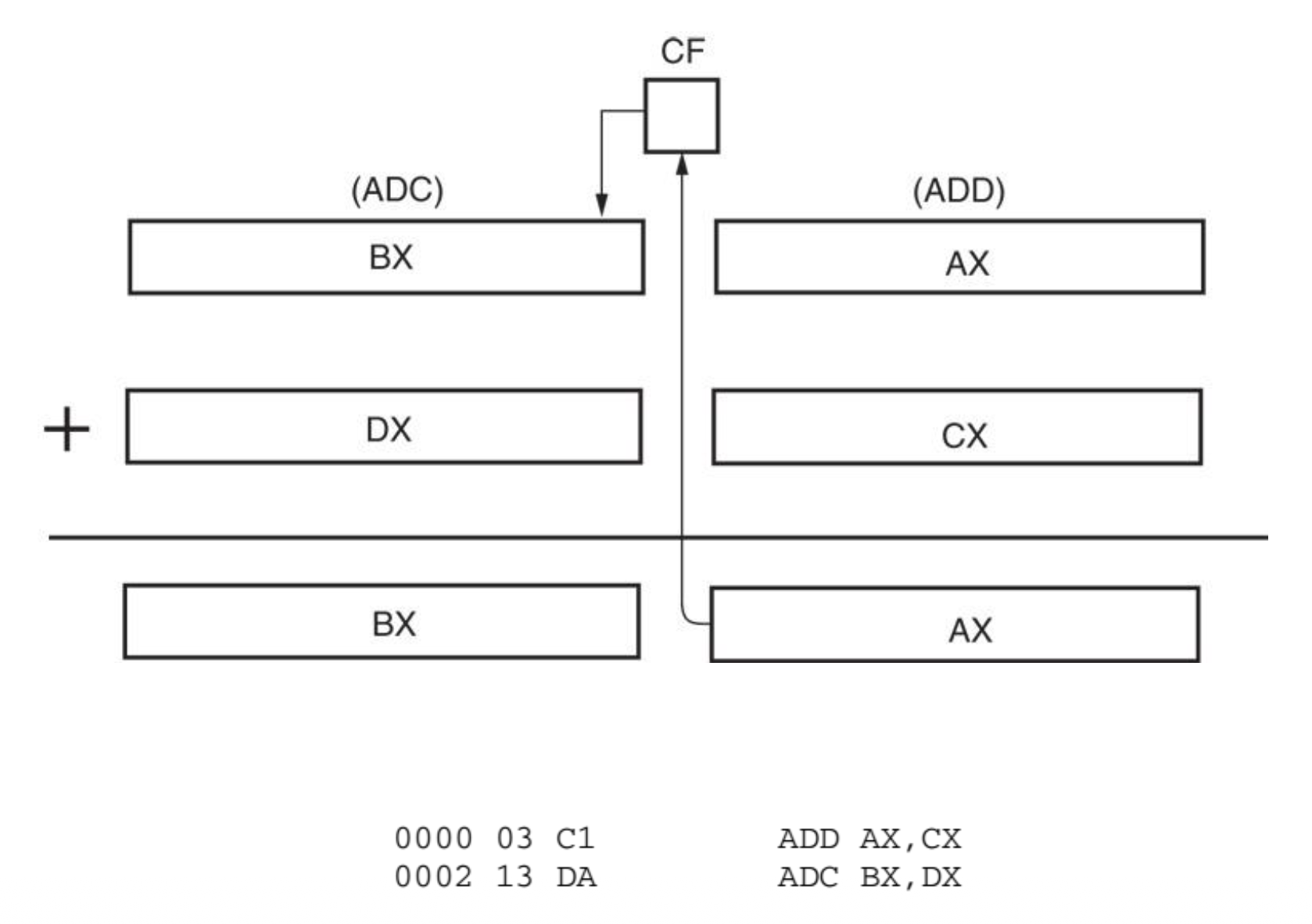
例子
使用
ADC计算两个双字长的长整数之和。; [int1][0:7] = [int1][O:7] + [int2][0:7] .data int1 DD 1,0,0,0,0,0,0,1 int2 DD 1,0,0,0,0,0,0,1 .code MOV EDI, OFFSET int1 MOV ESI, OFFSET int2 MOV ECX, 8 ; ECX = 8 CLC ; start out with carry flag cleared loop: MOV EAX, [ESI] ADC [EDI], EAX ; with carry from previous loop pass LEA ESI, [ESI+4] ; point to next source LEA EDI, [EDI+4] ; point to next destination DEC ECX ; adjust loop count JNZ loop ; if ECX > 0 then repeat
- 和
-
ADC的变体:ADCX和ADOX-
ADD和ADC指令可用于加速大整数算数运算,通过形如右侧的代码序列实现- 问题:这些指令创建了一个依赖链(dependency chain),因此处理器无法并行执行算术运算
-
为了解决这个问题,Intel 引入了第二条进位链,使得两个独立的进位链可同时发生;它们对应
ADC的两个变体ADCX和ADOX - 这两个变体不会相互影响,因为它们有单独的进位标志
ADCX使用进位标志,并保留其他标志不变ADOX使用溢出标志,并保留其他标志不变
例子

-
ADCX、ADOX和MULX指令为大型整数乘法带来了很大便利- 而大型整数算术在密码学(例如 RSA 公钥算法)和高性能计算中有许多应用场景
-
-
XADD(交换和加(exchange and add))-
语法:
XADD des, src,对应操作如下:- 交换
des操作数与src操作数 - 将两个值的和加载到
des操作数中:des = src + des
- 交换
-
是少数改变源操作数的指令之一
-
例子:
-
目标操作数可以是寄存器或内存位置,而源操作数只能是寄存器
- 对于多处理器系统,
XADD可以与LOCK前缀在多处理器系统中结合使用,以允许多个处理器执行一个DO循环 - 等价 C 函数:
int atomic_xadd(atomic_t *v, int inc)XADD将给定的增量inc加到*v上,并原子性地返回*v的先前值XADD在原子值*v上执行原子交换和加法操作- 当多个 CPU 在线时,
XADD会被锁住
XADD可以实现共享计数器和各种数据结构-
XADD可用于乐观锁(optimistic locking),主要适用于高并发系统中例子
以下指令使用乐观锁来安全地通过多个线程更新共享版本。
.data version DD 0 ; shared version number initialized to 0 .code MOV ECX, version ; load the current value of version ...... ; working optimistically MOV EAX, 1 ; EAX = 1 XADD version, EAX ; version ⇔ EAX, version = version+1 CMP EAX, ECX ; check if the value was modified by another thread JNE retry ; if version was updated then rollback ...... retry: ...... ; handle the conflict
-
Subtraction⚓︎
指令集中同样有许多形式的减法(SUB)指令,包括:
- 寄存器减法:每次执行减法运算时,微处理器修改标志寄存器的内容
- 立即数减法:允许常量数据作为减法中的立即操作数
-
DEC(递减(decrement)) :从任何寄存器或内存位置减去 1,并影响除CF外的所有标志位注
由于
INC和DEC会写入除CF之外的标志位,因此如果JCC直接使用来自INC/DEC的标志位,JCC可能会因为意外指令而产生错误依赖,例如:
所以编译器通常不会生成用于循环计数更新的
INC/DEC,或在JCC上重用INC/DEC提供的标志位。 -
带借位的减法(subtract-with-borrow) 指令(
SBB)- 功能与普通减法相同,但包含借位的进位标志(
C)也要从差值中减去 - 宽减法需要借位来传播,就像宽加法传播进位一样
-
下面展示该指令的运算细节:
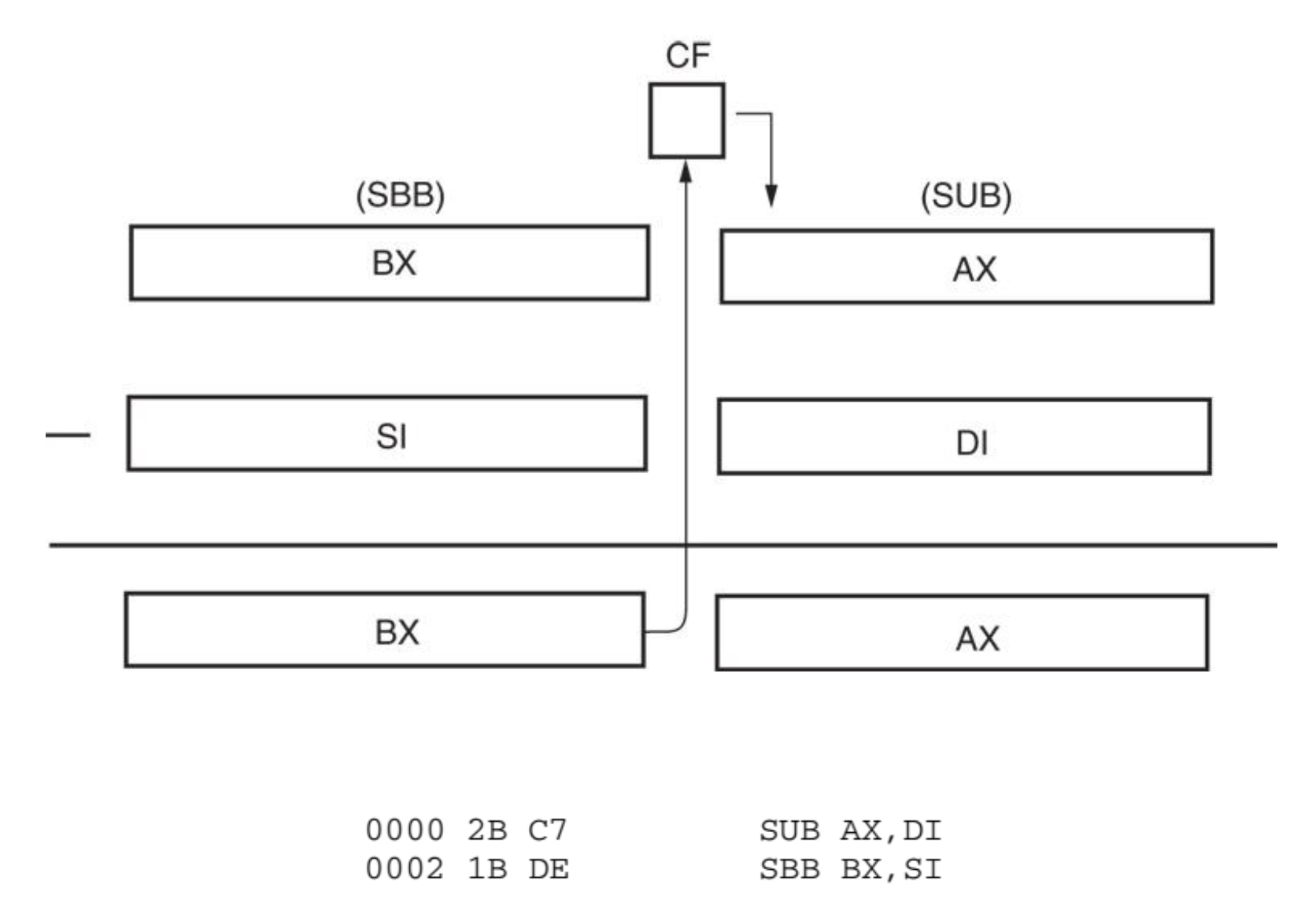
- 功能与普通减法相同,但包含借位的进位标志(
Comparison⚓︎
比较(comparison) 指令(CMP)是一种只改变标志位,而不会改变目标操作数的减法,用于检查寄存器或内存位置的内容与另一个值是否相等。后面通常会跟一个条件跳转指令,用于测试标志位的条件。
| 汇编语言 | 操作 |
|---|---|
CMP CL, BL |
CL - BL |
CMP AX, SP |
AX - SP |
CMP EBP, ESI |
EBP - ESI |
CMP RDI, RSI |
RDI - RSI(64 位模式) |
CMP AX, 2000H |
AX - 2000H |
-
比较和交换指令(
CMPXCHG)比较目的操作数与累加器(accumulator)(隐式操作数 (implicit operand)) ,- 语法:
CMPXCHG des, srcaccu表示累加器(AL/AX/EAX/)- 如果
des == accu,则des = src,ZF = 1 - 如果
des != accu,则accu = des,ZF = 0
例子
CMPXCHG CX, DX-
案例 1:
- 执行前:
(CX)=00FFH, (DX)=00EFH, (AX)=00FFH - 执行后:
(CX)=00EFH, (DX)=00EFH, (AX)=00FFH, ZF=1
- 执行前:
-
案例 2:
- 执行前:
(CX)=00FFH, (DX)=00EFH, (AX)=00EEH - 执行后:
(CX)=00FFH, (DX)=00EFH, (AX)=00FFH, ZF=0
- 执行前:
-
解释:三个寄存器分别表示原子值、新值和旧值(
AX)- 若
CX == AX,DX被拷贝到CX中 - 若
CX != AX,CX被拷贝到AX中 AX保留执行前CX的值
- 若
-
等价 C 函数:
int atomic_cmpxchg(atomic_t *v, int new, int old)- 此函数使用给定的旧值和新值,在原子值
v上执行原子比较交换操作,返回操作前原子变量v的旧值 - 它在操作周围提供显式的内存屏障
- 此函数使用给定的旧值和新值,在原子值
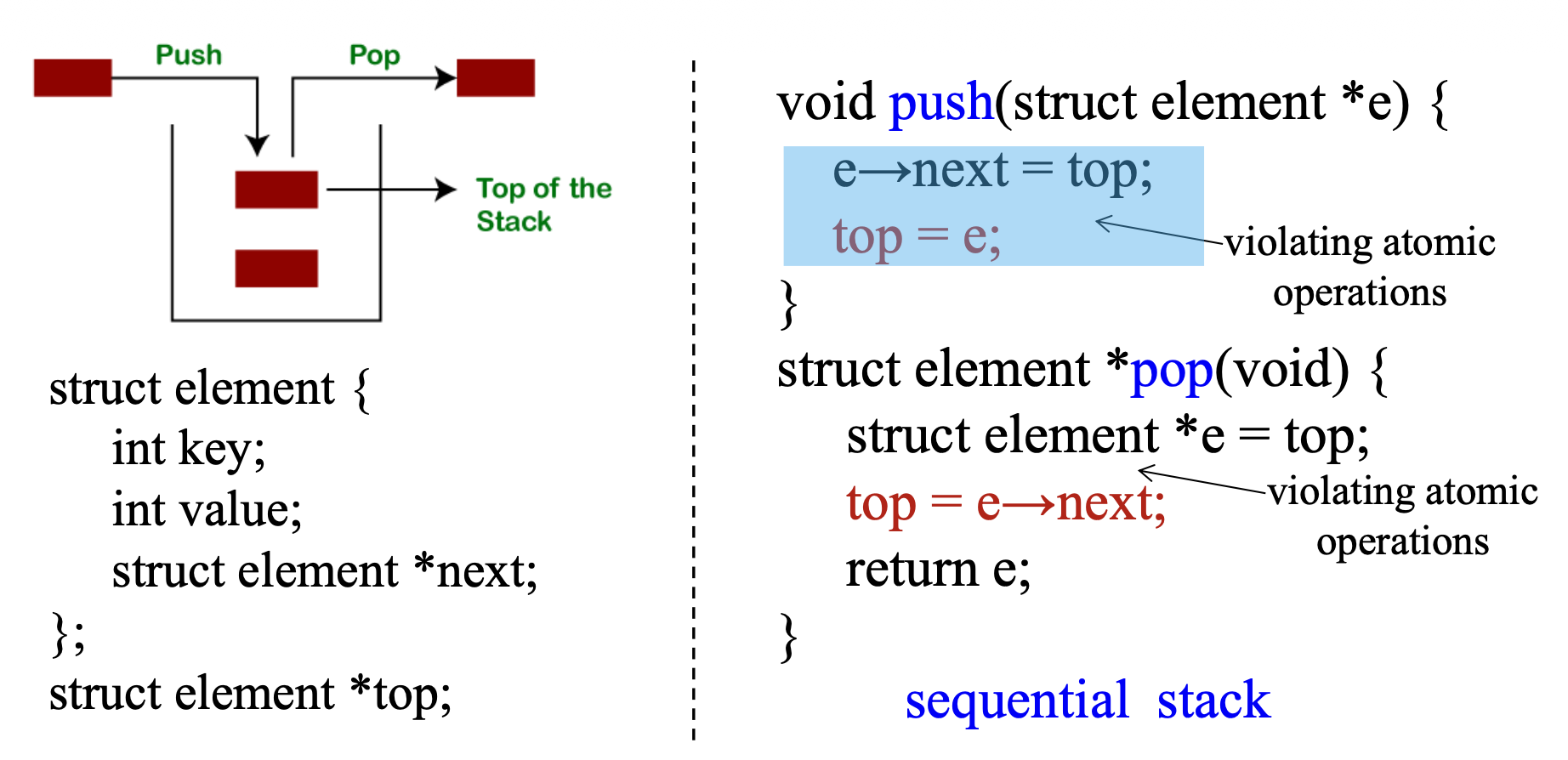
- 顺序栈在可能存在竞态条件的并发系统中将无法工作
- 自旋锁和读写锁可以帮助将锁从一个持有者转移到另一个持有者,但成本高
我们使用
cmpxchg函数解决这一问题: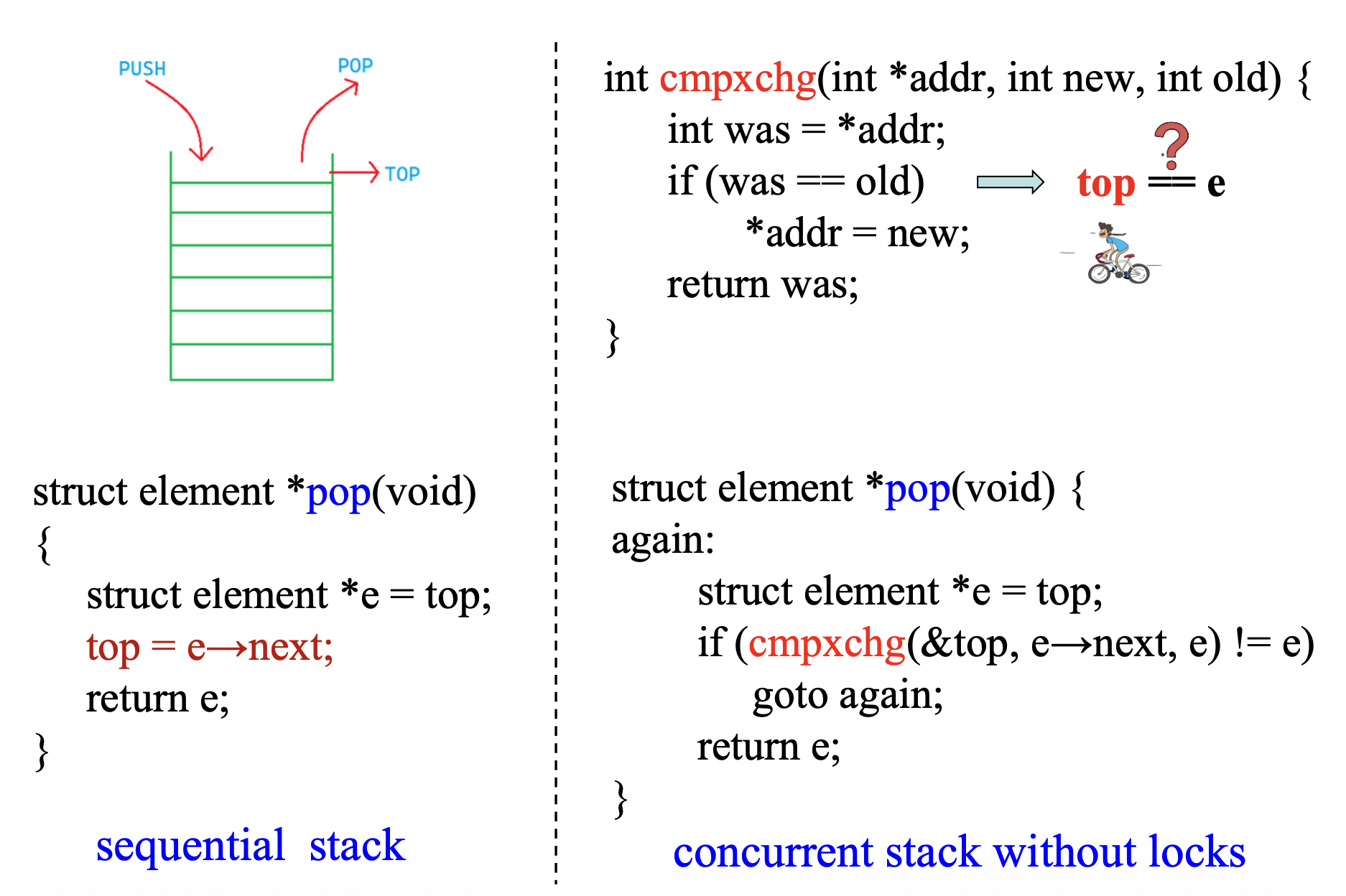
- 语法:
-
CMPXCHG8B指令:比较并交换八个字节-
语法:
CMPXCHG8B [mem64-operand]ECX:EBX:64 位新值(隐式操作数)EDX:EAX:64 位旧值(隐式操作数)- 如果操作数 ==
EDX:EAX,则操作数 =ECX:EBX,ZF = 1,否则EDX:EAX= 操作数,ZF = 0–Z标志位表示比较后的值相等
-
CMPXCHG8B通常在多处理器环境中与LOCK前缀一起使用,以确保原子操作
-
-
CMPXCHG16B:将RDX:RAX中的 128 位值与内存中位于目的操作数的 128 位数字进行比较- 如果值相等,则将
RCX:RBX中的 128 位值存储到目的操作数中,否则目的操作数中的值将加载到RDX:RAX中 CMPXCHG16B要求目的(内存)操作数应为 16 字节对齐
- 如果值相等,则将
Multiplication and Division⚓︎
早期的 8 位微处理器不支持乘法或除法指令,只能通过一系列移位和加减运算来实现。后来制造商们意识到了这种不足,于是他们将乘法和除法纳入了最新的微处理器指令集中。
Multiplication⚓︎
- 乘法指令可在字节、字或双字上执行
- 有无符号整数(
MUL)和符号整数(IMUL)两个版本 - 被乘数(multiplicand) 始终在
AL/AX/EAX寄存器中作为隐式操作数,例如MUL CL ; AX = AL*CL -
积始终是双宽度积(double-width product)
- 两个 8 位数字 -> 一个 16 位积;两个 16 位数字 -> 一个 32 位积;两个 32 位数字 -> 一个 64 位积
- 在 64 位模式下,两个 64 位数字 -> 一个 128 位积
-
8 位乘法
- 被乘数始终在
AL寄存器中- 乘数(multiplier) 可以是任何 8 位寄存器或内存位置
- 使用内存操作数时需要伪指令来指示操作数大小,例如
MUL WORD PTR [BX]
- 没有立即数乘法的形式(形如
MUL 12H) ,除非是IMUL乘法的两个或三个操作数形式 - 积位于
AX -
下面列举一些 8 位乘法指令的使用情况:
汇编语言 操作 MUL CLAL乘以CL;无符号积在AX中IMUL DHAL乘以DH;符号积在AX中IMUL BYTE PTR[BX]AL乘以BX所寻址的数据段内存位置的字节内容;符号积在AX中MUL TEMPAL乘以内存位置TEMP的字节内容;无符号积在AX中
- 被乘数始终在
-
16 位乘法
- 被乘数放在
AX中 - 32 位积放在
DX-AX中DX包含积的高 16 位AX包含积的低 16 位
- 乘数的选取与 8 位乘法类似
- 被乘数放在
-
32 位乘法
EAX寄存器的内容与指令指定的操作数相乘- 64 位积位于
EDX-EAX中,其中EAX包含积的低 32 位
-
64 位乘法
- 128 位积位于
RDX:RAX寄存器对中
- 128 位积位于
-
IMUL指令的三种形式:- 单操作数形式:同
MUL指令 -
双操作数形式:目的操作数是一个寄存器,源操作数是一个立即值、一个寄存器或一个内存位置,中间乘积(输入操作数大小的两倍)被截断并存储在目的操作数位置
-
三操作数形式:第一个源操作数乘以第二个源操作数,中间乘积被截断并存储在目的操作数
- 单操作数形式:同
-
立即数乘法
- 在双操作数或三操作数形式的
IMUL指令中,源操作数可以是一个立即值 - 当使用立即值作为操作数时,它会被符号扩展到目标操作数格式的长度
- 比如
IMUL CX, DX, 12H指令将12H乘以DX,并将一个 16 位符号积留在CX中 - 注意,双操作数形式会被汇编为三操作数以支持立即数乘法,例如,
IMUL BX, 16H->IMUL BX, BX, 16H
- 在双操作数或三操作数形式的
-
MUL和IMUL的差别:前者用零扩展填充高位,而后者用符号扩展填充高位
-
受
MUL影响的标志-
当积完全能被寄存器容纳时(结果没有被截断
) ,MUL指令清零OF和CF标志,否则OF和CF标志被置 1
-
CF和OF标志表示积的上半部分是否包含有效数字
-
-
受
IMUL影响的标志-
当中间乘积的符号整数值与符号扩展操作数大小的截断乘积不同时,
CF和OF标志被置一,否则CF和OF标志被清零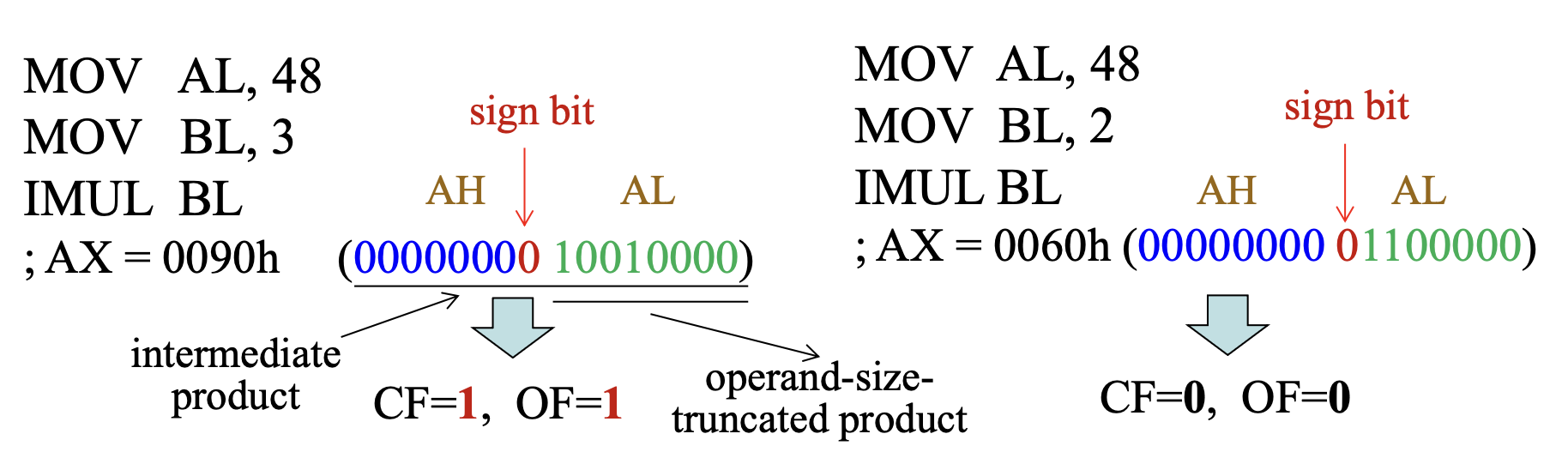
-
使用两个和三个操作数形式时,由于截断,应检查
CF或OF标志以确保没有重要的位丢失
-
思考
为什么 MUL 只有单操作数形式,而 IMUL 有扩展的双操作数和三操作数形式?
- 随着编程语言和编译器的开发,Intel 发现符号整数(如 C 中的
int)的使用频率远高于无符号整数(例如,表达式x = y * 10或x = y * z) - 因此,Intel 引入了
IMUL的双操作数和三操作数形式,以简化在汇编级别实现高级语言乘法语义的实现
为什么 IMUL 指令的两位操作数和三位操作数形式使用截断乘法而不是扩展乘法?
- 单操作数的
MUL和IMUL最初是为高精度 / 大数字算术(例如加密、哈希计算)等场景设计的,这些场景更依赖于完整的 2N 位结果,因此它们使用扩展乘法 - 在编程语言中,对于像
c = a * b(其中a、b和c都是相同的int类型)这样的常见表达式,程序员关注的是结果的低 N 位,因此IMUL的双操作数和三操作数形式使用截断乘法
Division⚓︎
- 除法可在 8 位、16 位和 32 位数字上执行;而在 64 位模式下,可以实现 128 位数字除以 64 位数字
- 存在无符号整数(
DIV)和符号整数(IDIV)版本 - 被除数始终是双倍宽度的
- 不存在立即数除法指令
- 除法相关的错误有除以零、除法溢出(发生在一个大数除以一个小数时)等;但不管是什么除法错误,微处理器都会生成一个中断,在屏幕上显示错误信息
-
8 位除法
- 使用
AX存储被除数(dividend)(16 位) ,而除数(divider) 位于 8 位寄存器或内存中 -
结果存储在
AL:= 商(quotient),AH:= 余数(remainder)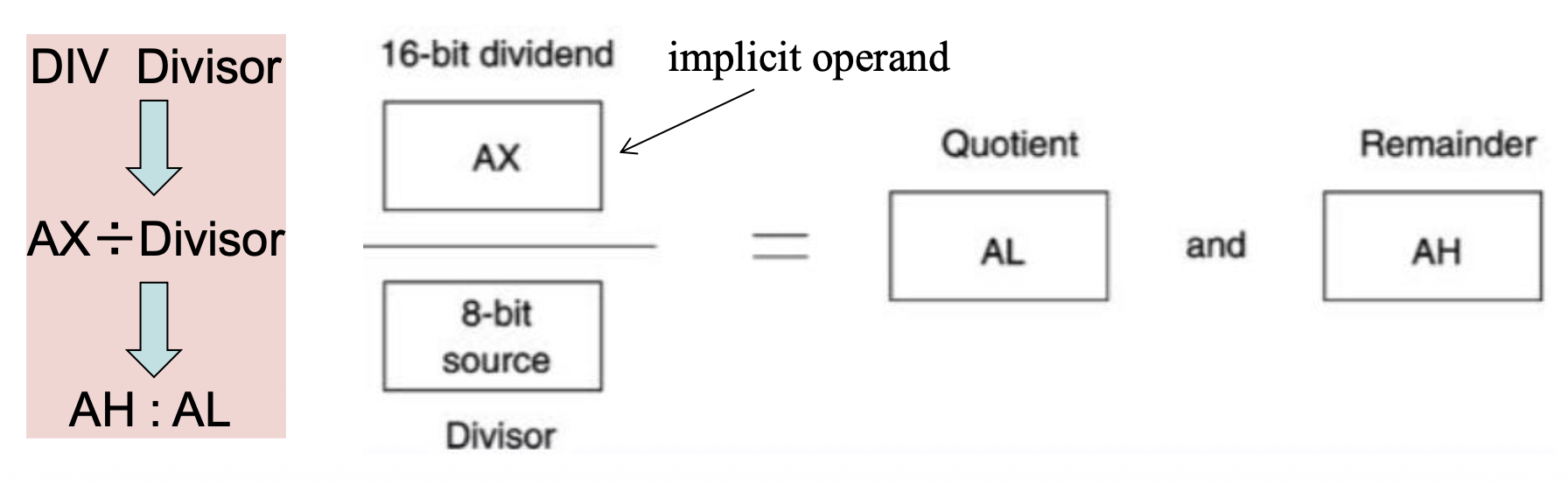
-
商或正或负,而余数始终取被除数的符号;这种舍入模式称为向零舍入(round-to-zero)
- 示例:
IDIV BL- 对于
AX = 10H(+16) 和BL = 0FDH(-3)- 结果:商为 -5 (
AL),余数为 1 (AH)
- 结果:商为 -5 (
- 对于
AX = 0FFF0H(-16) 和BL = 03H(+3)- 结果:商为 -5 (
AL),余数为 -1 (AH)
- 结果:商为 -5 (
- 对于
例子
- 使用
-
16 位除法
- 此时以
DX-AX作为被除数(32 位) - 在 80386 以上的处理器中,使用
MOVZX指令对数字进行零扩展
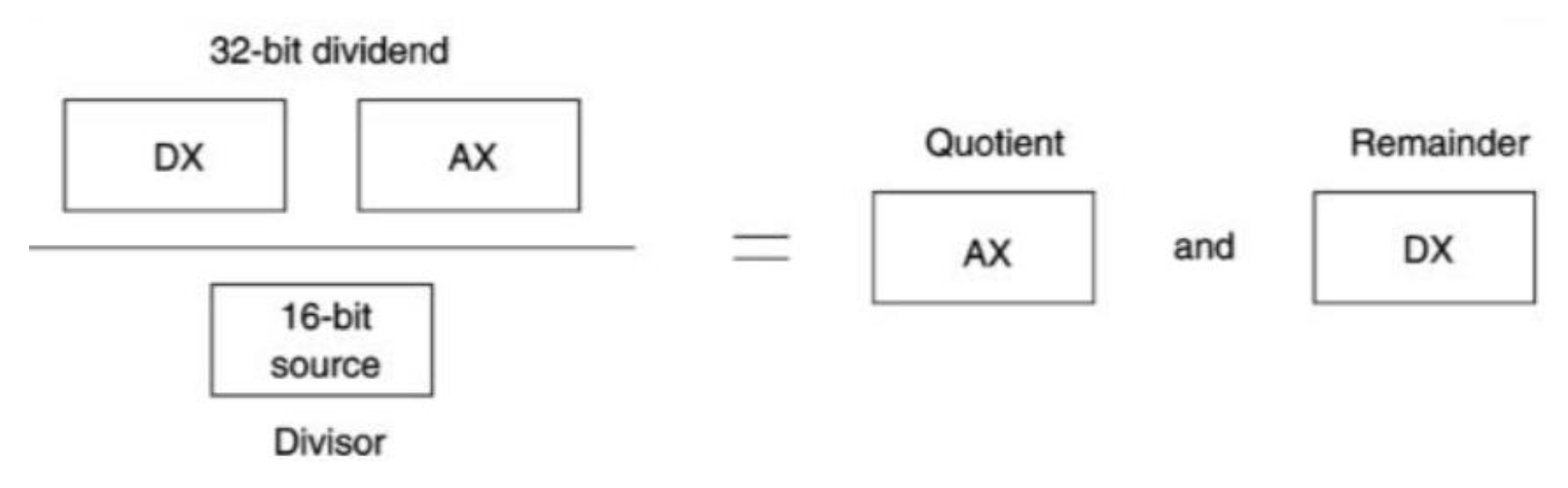
- 此时以
-
32 位除法
- 80386 及以上的处理器支持在无符号或符号数上执行 32 位除法
EDX-EAX中的 64 位内容除以指令指定的操作数- 32 位的商和余数分别在
EAX和EDX中
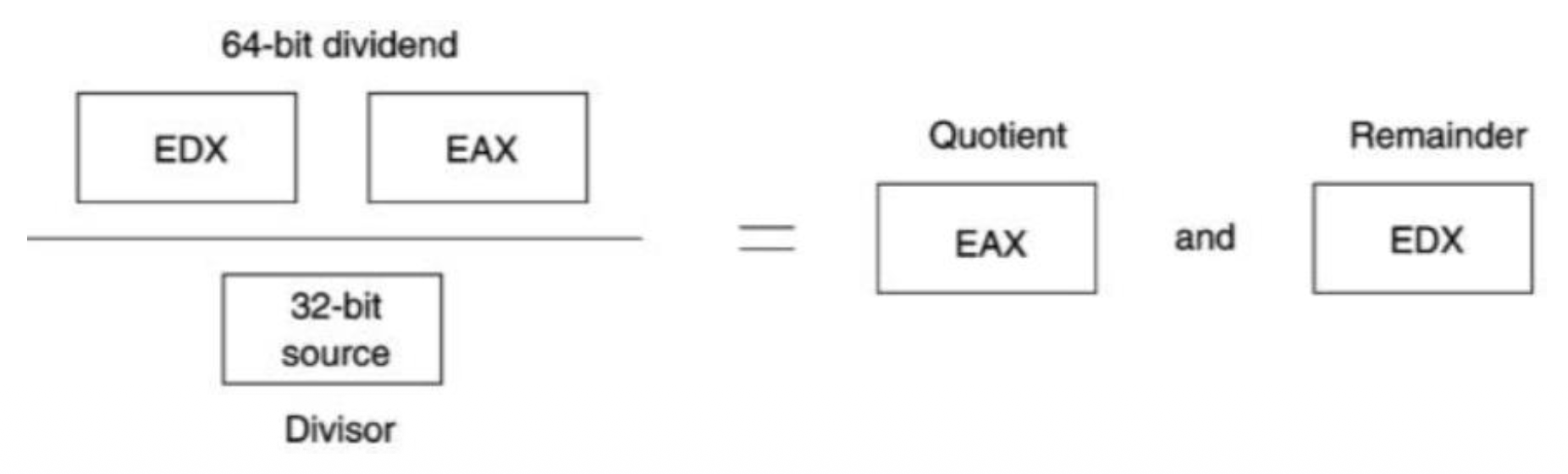
-
64 位除法
- 处于 64 位模式的 Pertium 4 可在无符号或符号数上执行 32 位除法
- 使用
RDX-RAX来保存被除数 - 商和余数分别在
RAX和RDX中
-
3 种类型的符号扩展:
-
CBW/CWDE/CDQE:将AL/AX/EAX中的符号字节 / 字 / 双字转换为符号字 / 双字 / 在RAX中的四字指令 Op/En 64 位模式 兼容 / 传统模式 描述 CBWZO有效 有效 AX := AL的符号扩展CWDEZO有效 有效 EAX := AX的符号扩展CDQEZO有效 不适用 RAX := EAX的符号扩展 -
CWD/CDQ/CQO:将 rAX的符号位拷贝到 rDX寄存器的所有位上-
以下例子展示了通过
CWD指令对 2 个 16 位符号数的除法
-
-
MOVSX/MOVSXD:将源操作数(寄存器 / 内存位置)的内容通过符号扩展拷贝到目标操作数(寄存器)MOVSX reg16, reg/mem8 MOVSX reg32, reg/mem16 MOVSX reg32, reg/mem8 MOVSX reg64, reg/mem16 MOVSX reg64, reg/mem8 MOVSXD reg64, reg/mem32-
MOVZX:将源操作数(寄存器 / 内存位置)的内容通过零扩展拷贝到目标操作数(寄存器)
-
-
-
余数有以下几种处理方式:
- 截断求商(dropped to truncate the quotient):比如 13 / 2 = 6
- 舍入求商(round the quotient):如果除法是无符号的,舍入需要将余数与除数的一半进行比较,以决定是否将商数向上取整(比如 13 / 2 = 7)
- 分数余数(fractional remainder):比如 13 / 2 = 6.5
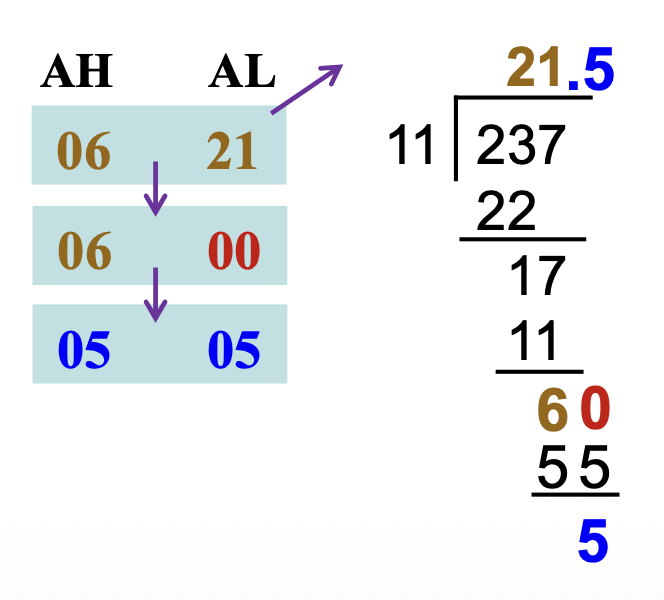
例子
下面展示了一个将 AX 除以 BL 的程序,并舍入无符号结果(即,AX / BL)
0000 F6 F3 DIV BL ; divide
0002 02 E4 ADD AH, AH ; double remainder
0004 ЗА ЕЗ CMP AH, BL ; test for rounding
0006 72 02 JB NEXT ; if OK
0008 FE CO INC AL ; round
000A NEXT:
- 在比较之前将余数加倍,以决定是否舍入求商
INC指令在比较后舍入AL的内容
下面展示了如何将 13 除以 2。
0000 B8 000D MOV AX, 13 ; load 13
0003 B3 02 MOV BL, 2 ; load 2
0005 F6 F3 DIV BL ; 13/2
0007 A2 0003 R MOV ANSQ, AL ; save quotient
000A BO 00 MOV AL, O ; clear AL
000C F6 F3 DIV BL ; generate remainder
000E A2 0004 R MOV ANSR, AL ; save remainder
- 8 位商被保存在内存位置
ANSQ中,然后 AL 被清零 - 接下来,
AX的内容再次除以 2,以生成一个分数余数 - 在第二次除法后,
AL寄存器的值为80H - 如果将二进制点(基数)放置在
AL的最左边位之前,则AL中的小数余数为 0.510 或 0.100000002 - 余数保存在内存位置
ANSR中
BCD and ASCII Arithmetic⚓︎
微处理器同时支持 BCD(二进制编码的十进制 (binary-coded decimal))和 ASCII 数据的算术操作。但这些指令在 64 位模式下是无效的,强行使用会抛出无效操作码异常(invalid-opcode exception)。
BCD Arithmetic⚓︎
- BCD 运算发生在如小型终端(例如,收银机)和其他很少需要复杂算术的系统中
-
两种使用 BCD 数据进行运算的算术指令:
DAA(加法后十进制调整 (decimal just after addition))指令紧随 BCD 加法之后DAS(减法后十进制调整 (decimal just after subtraction))紧随 BCD 减法之后- 两者都纠正加法或减法的结果,使其成为 BCD 数,并且这些指令使用寄存器
AX作为源和目标
-
DAA指令:- 调整两个压缩(packed) BCD 值的总和,以创建一个压缩 BCD 结果
- 仅在跟随
ADD或ADC指令后面时才有用,这些指令将两个 2 位数字的压缩 BCD 值相加(以二进制方式相加) ,并将字节结果存储在AL寄存器中 - 然后该指令调整
AL寄存器的内容,使其包含正确的 2 位数字压缩 BCD 结果 - 如果检测到十进制进位,则
CF和AF(在加法后保存进位(半进位) )标志会相应设置
例子
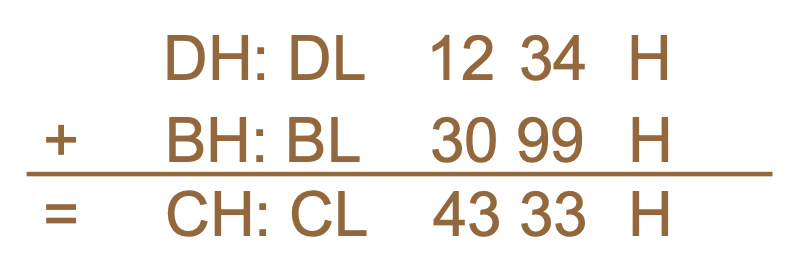
0000 BA 1234 MOV DX, 1234H ; load 1234 BCD 0003 BB 3099 MOV BX, 3099Н ; load 3099 BCD 0006 8A C3 MOV AL, BL ; sum BL and DL 0008 02 C2 ADD AL, DL ; AL = CDH 000A 27 DAA ; AL = 33H, CF = 1 000B 8A C8 MOV CL, AL ; answer to CL 000D 9A C7 MOV AL, BH ; sum BH, DH and carry 000F 12 C6 ADC AL, DH ; AL = 43H 0011 27 DAA 0012 8A E8 MOV CH, AL ; answer to CH ; CX = 4333H -
DAS指令:除了做减法运算外,和DAA指令基本一致例子
0000 BA 1234 MOV DX, 1234H ; load 1234 BCD 0003 BB 3099 MOV BX, 3099Н ; load 3099 BCD 0006 8A C3 MOV AL, BL ; subtract DL from BL 0008 2A C2 SUB AL, DL 000A 2F DAS 000B 8A C8 MOV CL, AL ; answer to CL 000D 9A C7 MOV AL, BH ; subtract DH 000F 1A C6 SBB AL, DH 0011 2F DAS 0012 8A E8 MOV CH, AL ; answer to CH
ASCII Arithmetic⚓︎
- ASCII 算术指令与编码数字一起工作,值
30H到39H代表 0 到 9 -
有以下四种指令:
AAA(ASCII 加法后调整)AAS(ASCII 减法后调整)AAM(ASCII 乘法后调整)AAD(ASCII 除法前调整)
-
这些指令使用寄存器
AX作为源和目标 -
AAA指令:- 在使用
ADD指令后,使用AAA指令来添加两个未压缩的(unpacked) BCD 数字 AL寄存器是AAA指令的隐式源操作数和目标操作数-
AAA指令将AL中的值调整为未压缩的 BCD 结果- 如果
AL[3:0] > 9或AF = 1,则AL = AL + 6,AH = 1,并设置CF = 1和AF = 1 - 否则,
CF = 0,AF = 0 - 在任何情况下,
AL[7:4] = 0,将正确的小数位留在AL[3:0]中
- 如果
-
AAA指令可以添加 ASCII 数字,而无需屏蔽掉高四位'3'
例子
LLM 能否理解
AAA指令应该是对本学期第二次实验的预告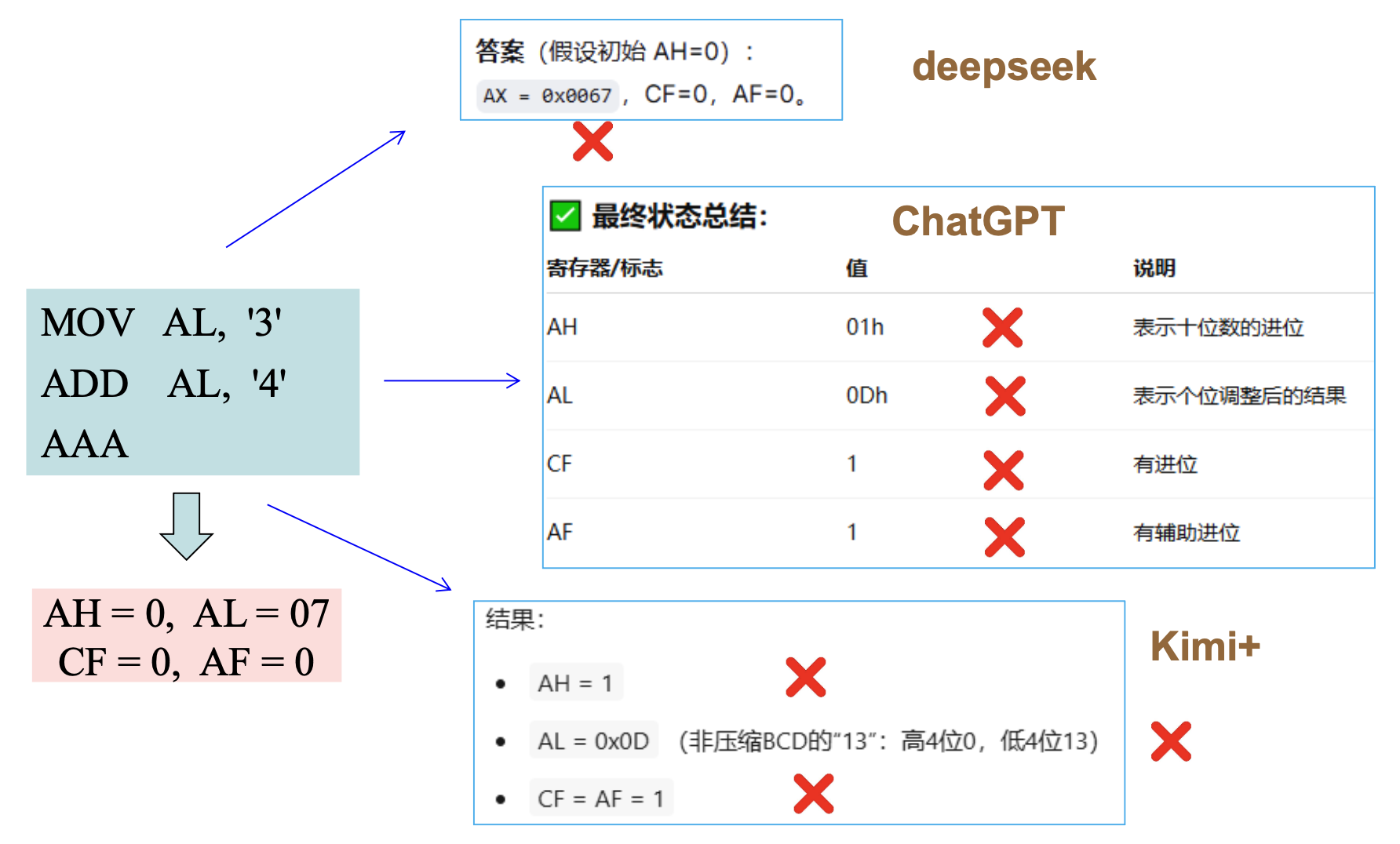

- 在使用
-
AAS指令:在 ASCII 减法后调整AX寄存器 AAM指令:- 在对两个一位数的未压缩 BCD 数字进行乘法运算后,遵循乘法指令
- 该指令将二进制转换为未压缩的 BCD
- 如果
AX中出现介于0000H和0063H之间的二进制数字,该指令将其转换为 BCD
AAD指令:- 出现在除法前
- 要求
AX寄存器在执行前包含两位未压缩的 BCD 数字(非 ASCII)
Logic Instructions⚓︎
逻辑运算在低级软件 (low-level software) 中提供二进制位控制,允许设置、清除或补位。
- 低级软件以机器语言或汇编语言形式出现,并且常用于控制系统中的 I/O 设备
除 NOT 指令外,逻辑指令始终会对这些标志位产生影响:
OF和CF标志清零- 更改
SF、ZF和PF标志 AF标志状态是未定义的
当在寄存器或内存位置中操作二进制数据时,最右边的位记为第 0 位。
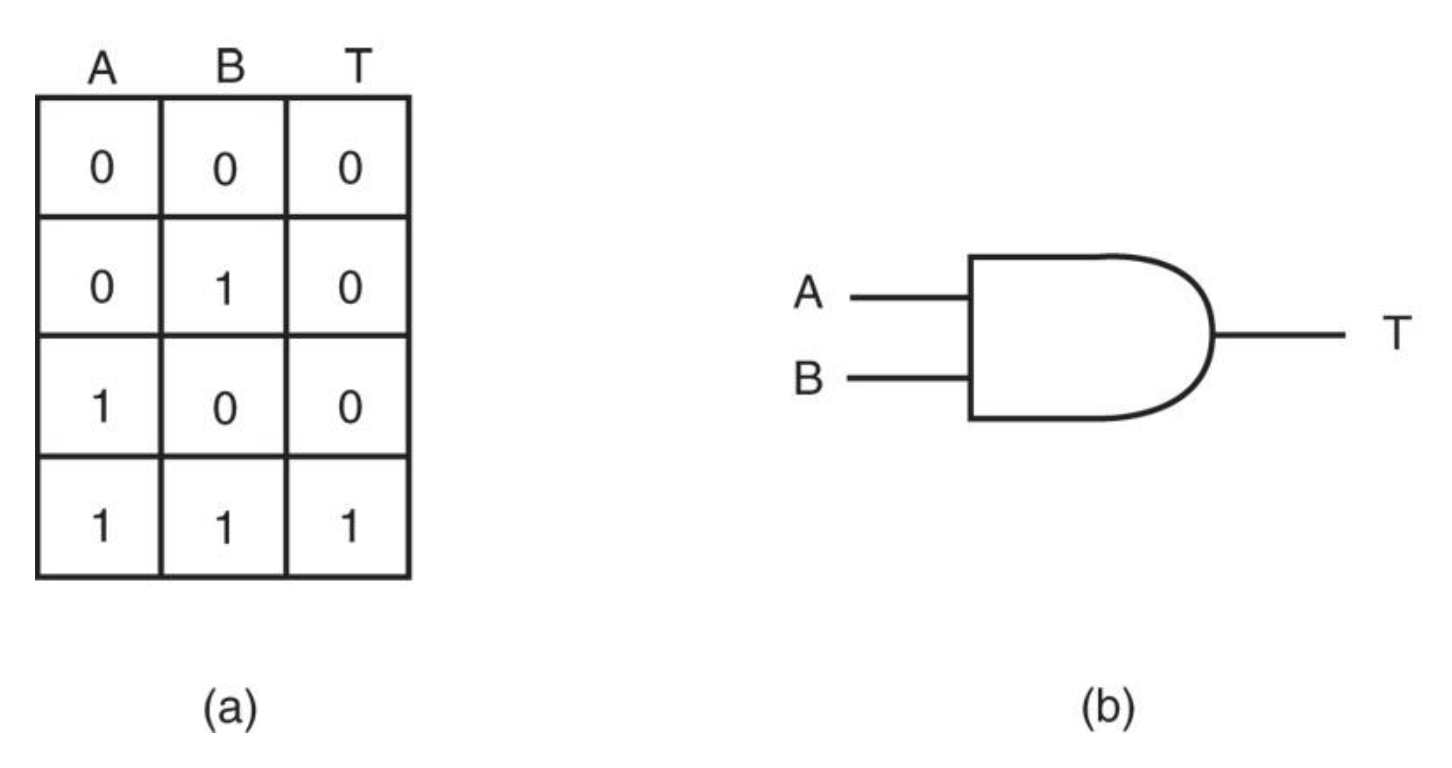
AND⚓︎
- 执行逻辑乘法,通过真值表说明
- 如果所需速度不是太快,
AND可以替代离散的 AND 门- 通常保留用于嵌入式控制应用
- 在 8086 中,
AND指令通常在约 1μs 内执行- 使用较新版本时,执行速度大大提高
-
可用于实现掩码(masking) 操作,即清除二进制数的位
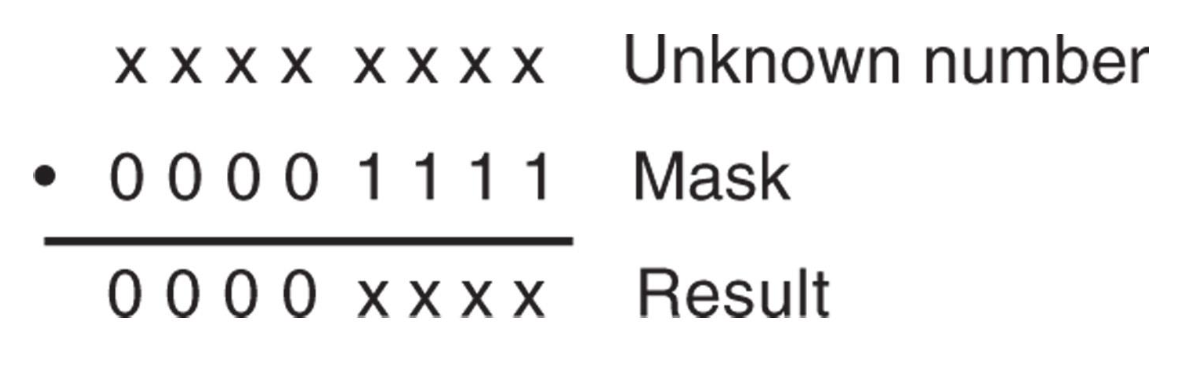
-
可以使用
AND掩码去除最左边的四个二进制位位置,将 ASCII 编码的数字转换为 BCD
-
-
支持除内存到内存和段寄存器寻址之外的所有模式
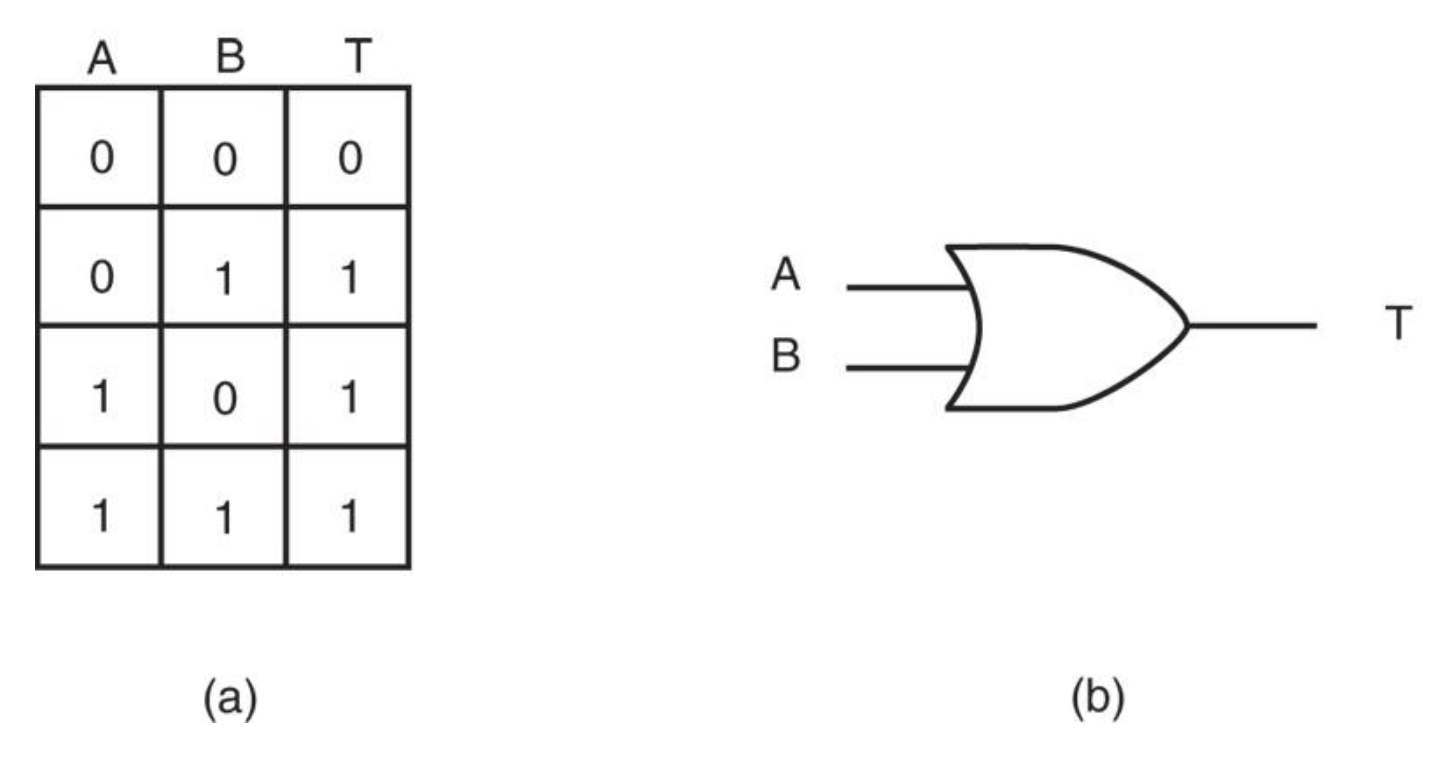
OR⚓︎
-
执行逻辑加法,通常称为包含或(inclusive-or) 函数
- 如果有任何输入为 1,就会生成逻辑 1 输出
- 只有当所有输入均为 0 时,输出才为 0
-
OR 门及真值表:
-
使用除段寄存器寻址以外的任何寻址模式
-
使用
OR指令将数字中的某些位(强行)置 1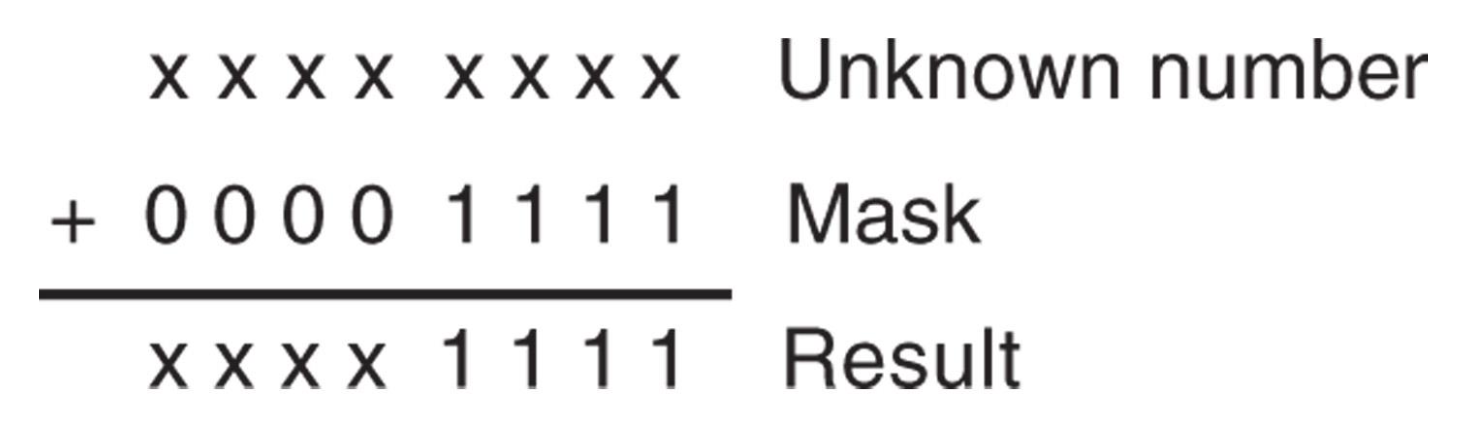
Exclusive-OR⚓︎
- 与
OR唯一不同的是,当输入为 1, 1 时,异或(exclusive-OR) 产生 0 - 实际上可将规则总结为:若输入都是 0 或者都是 1,则输出为 0;如果输入不同,则输出为 1
- 异或有时被称为比较器(comparator)
-
XOR 门及真值表:
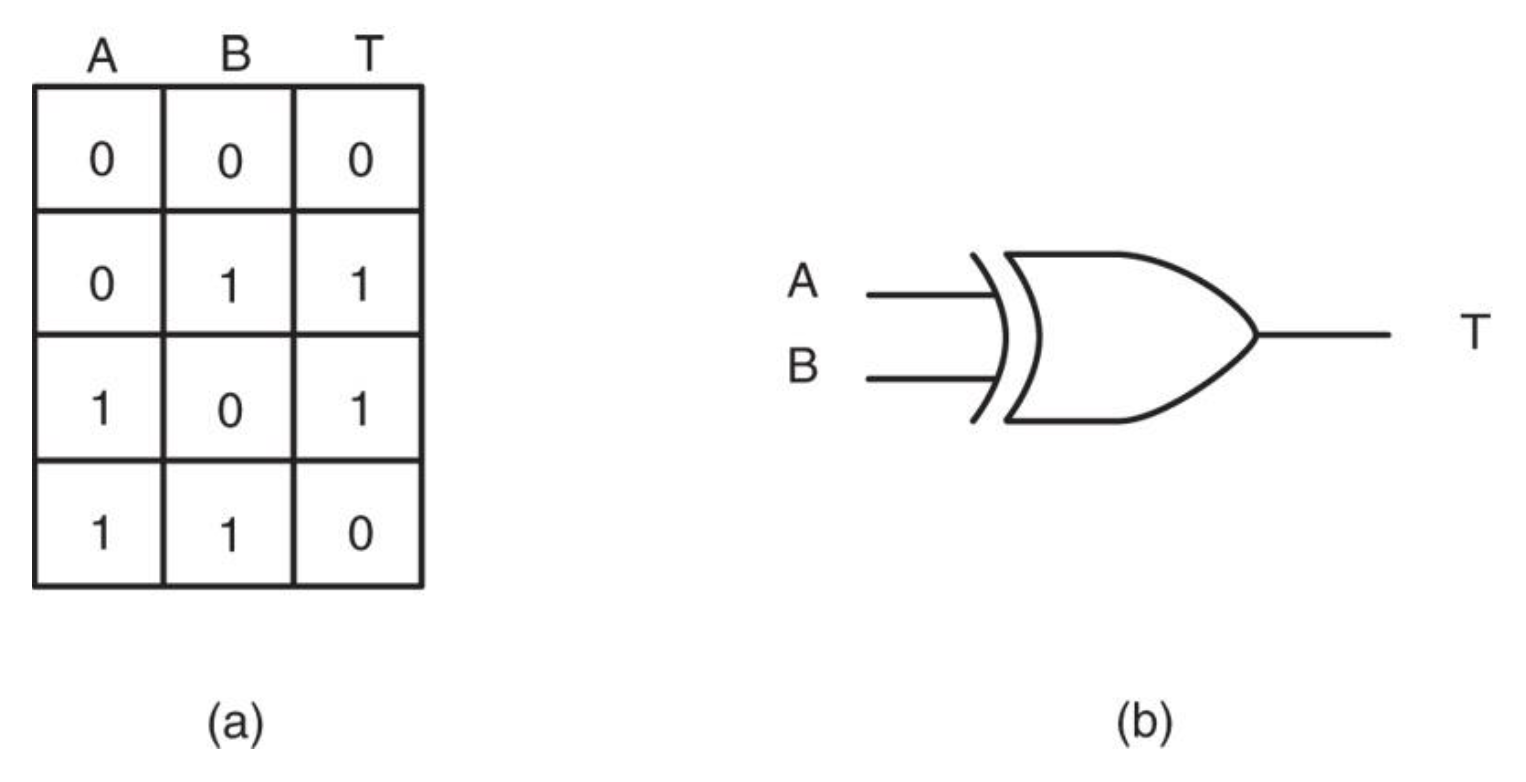
-
使用除段寄存器寻址以外的任何寻址模式
-
可用于反转寄存器或内存位置的某些位
- 当 1 与 \(X\) 进行异或时,结果是 \(\overline{X}\)
- 当 0 与 \(X\) 进行异或时,结果是 \(X\)
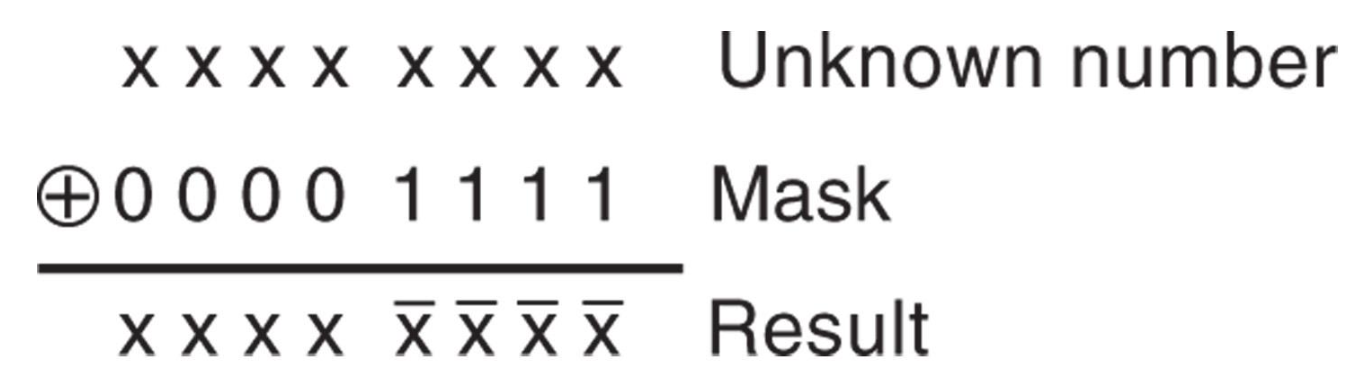
-
另一个常见用途是将寄存器清零(自己跟自己做异或)
Test and Bit Test Instructions⚓︎
TEST执行AND操作,但只影响标志寄存器(表示测试结果的条件)- 通常后面紧跟
JZ(如果为零则跳转 (jump if zero))或JNZ(如果不为零则跳转 (jump if not zero))指令 - 目标操作数通常与立即数进行比较
例子
测试 AL 寄存器最右边和最左边的位;用 1 选择最右边的位,128 选择最左边的位
-
CMP和TEST是常用于比较的指令,这些指令被称为条件指令(conditionals) -
TEST same, same用于确定一个符号数是否大于 0 -
TEST EAX, EAX和CMP EAX, 0几乎相同,但前者比后者更短 -
从 80386 处理器开始引入了额外的测试指令,用于测试单个位的位置
-
由源操作数选定目标操作数中被测位的位置
汇编语言 操作 BT测试目标操作数中由源操作数指定的位 BTC测试目标操作数中由源操作数指定的位,并对该位进行求反(complement) 操作 BTR测试目标操作数中由源操作数指定的位,并重置(reset)(置为 0)该位 BTS测试目标操作数中由源操作数指定的位,并设置(set)(置为 1)该位 -
例子:
BT AX, 4指令测试AX的第 4 位- 测试结果位于进位标志位
CF - 若第 4 位是 1,
CF置位 - 若第 4 位是 0,
CF清零
- 测试结果位于进位标志位
-
NOT and NEG⚓︎
NOT指令反转一个字节、字或双字的所有位NEG对一个数取二进制补码,得到该数的相反数NOT和NEG可以使用除段寄存器寻址以外的任何寻址模式NOT被认为是逻辑操作,NEG被认为是算术操作-
NOT指令不影响任何标志位,而NEG指令影响的标志位有:- 如果操作数 = 0,则
CF= 0,否则CF= 1 OF、SF、ZF、AF和PF标志位根据结果设置
- 如果操作数 = 0,则
-
为什么
NOT指令不修改任何标志位
例子
符号函数:

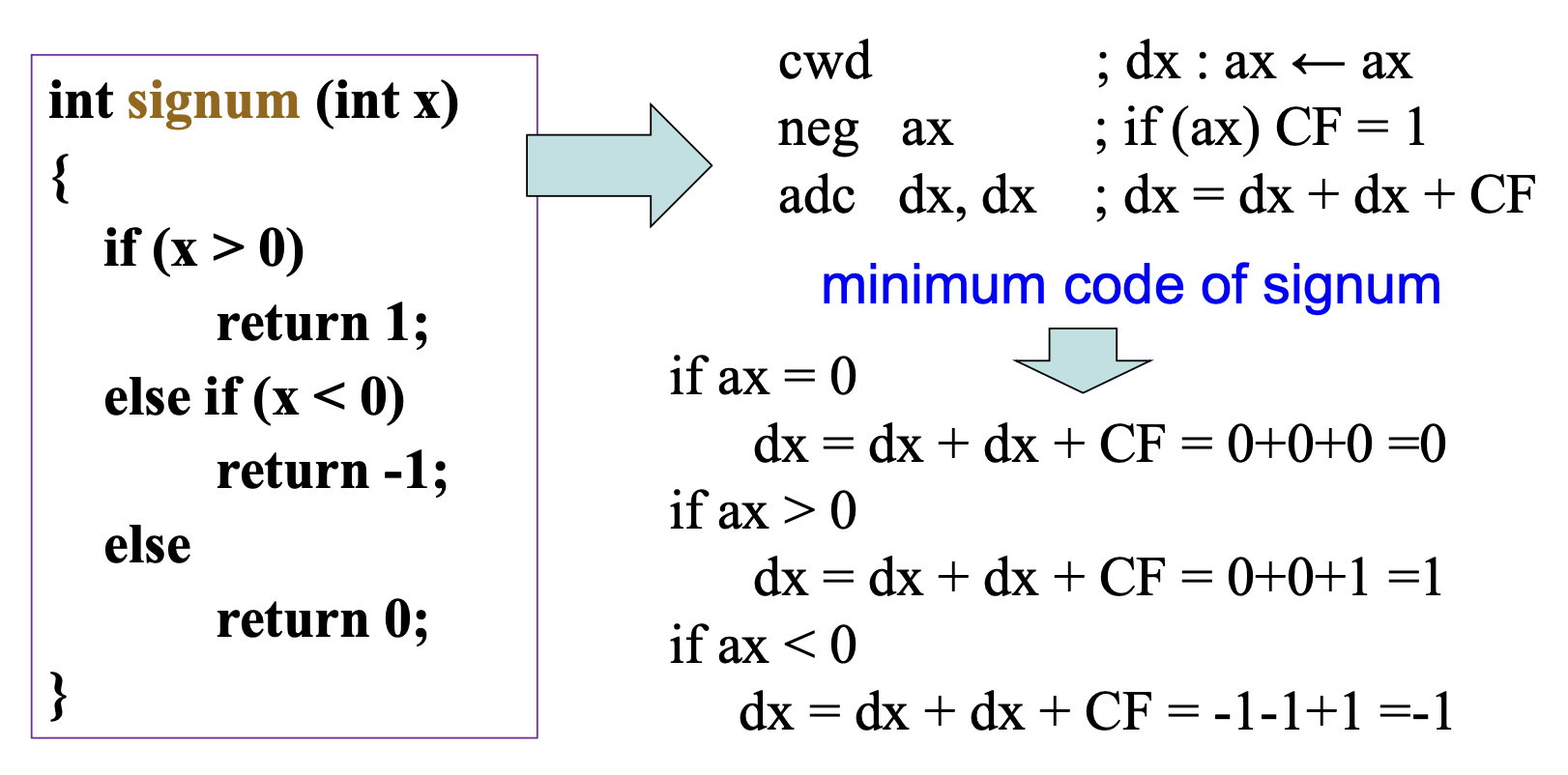
signum 函数的最小代码由一个叫做 superoptimizer 的程序生成。
Shift⚓︎
-
移位指令将数字左移或右移到寄存器或内存位置中
- 还可以执行简单的算术运算,如乘以 2 +n 的幂(左移)和除以 2 -n 的幂(右移)
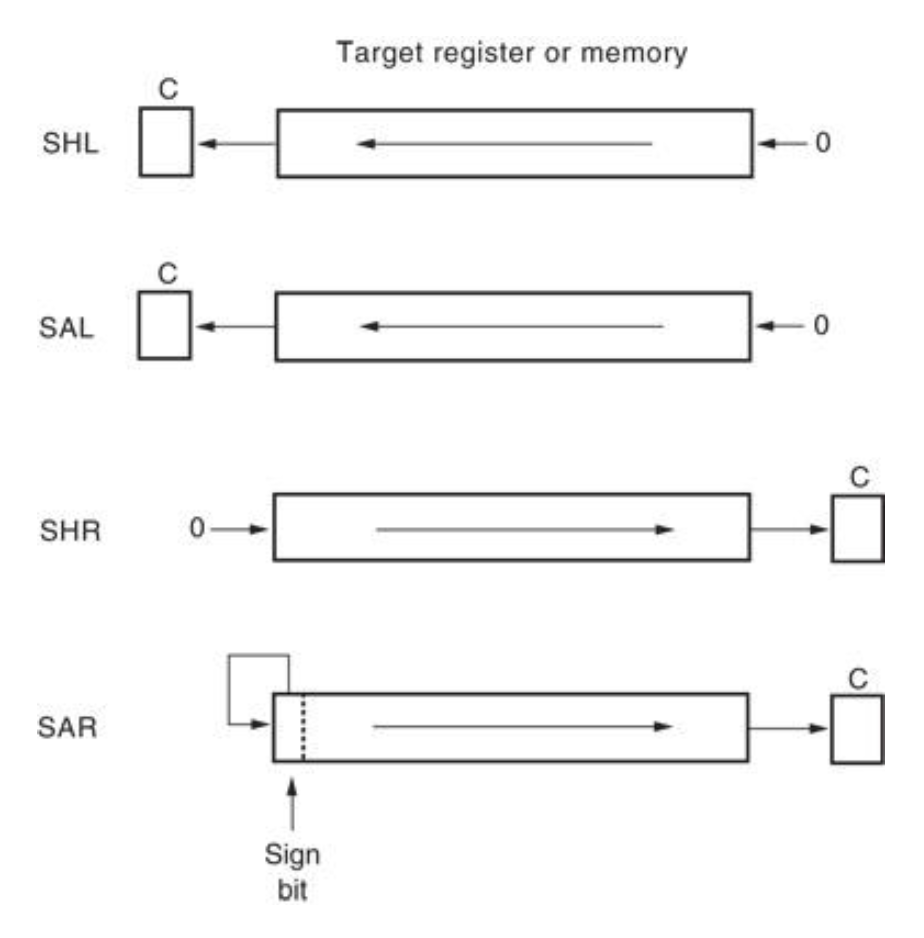
-
微处理器的指令集包含四种不同的移位指令:
- 两个是逻辑(logical) 移位;两个是算术(arithmetic) 移位
- 语法:
SHL/SAL/SHR/SAR REG/MEM, Count
-
下图展示了这四种移位运算:
SHL和SAL将目标操作数的位向左移动(所以两者执行相同的操作)SHR用 0 填充左边空出来的位SAR用符号位填充左边空出来的位
-
一些例子:
汇编语言 操作 SHL AX, 1AX进行逻辑左移 1 位SHR BX, 12BX进行逻辑右移 12 位SHR ECX, 10ECX进行逻辑右移 10 位SHL RAX, 50RAX进行逻辑左移 50 位(64 位模式)SAL DATA1, CL数据段内存位置 DATA1的内容进行算术左移,位移量由CL指定SHR RAX, CLRAX进行逻辑右移,位移量由CL指定(64 位模式)SAR SI, 2SI进行算术右移 2 位SAR EDX, 14EDX进行算术右移 14 位 -
计数操作数可以是一个立即值或
CL寄存器-
以下示例展示了如何以两种不同方式将
DX寄存器左移 14 位:
-
-
在 16 位或 32 位模式下,移位计数是一个模 32 的计数,即计数范围在 0-31 内
- 在 64 位模式下,移位计数是一个模 64 的计数,即计数范围在 0-63 内
SAR和SHR指令可用于执行目标操作数按 2 的幂次的符号或无符号除法-
负数的
SAR舍入:- 对于负数,
IDIV指令得到的商会被舍入至 0,而SAR指令会将其舍入至负无穷,两者结果并不一致 (inconsistency)


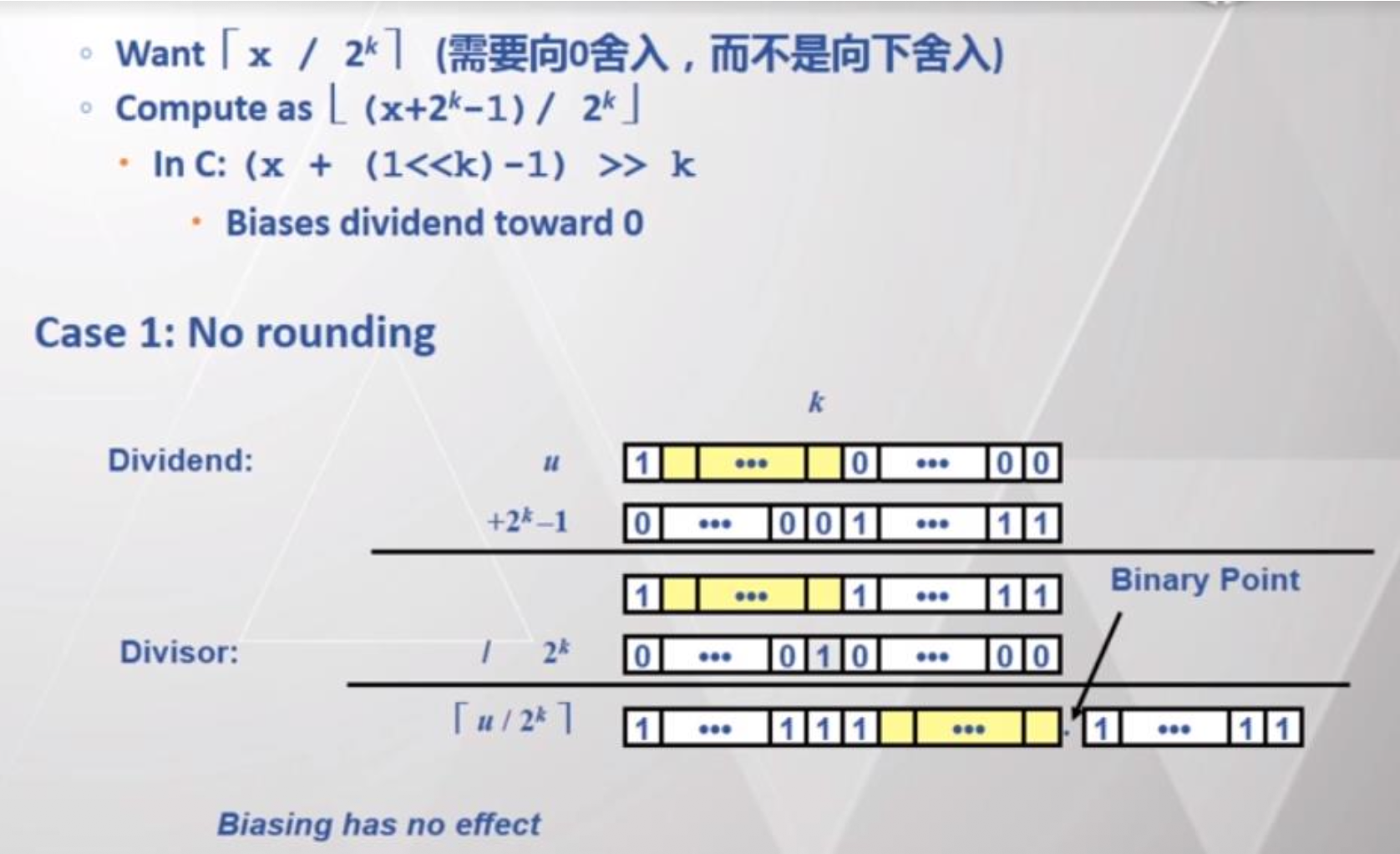
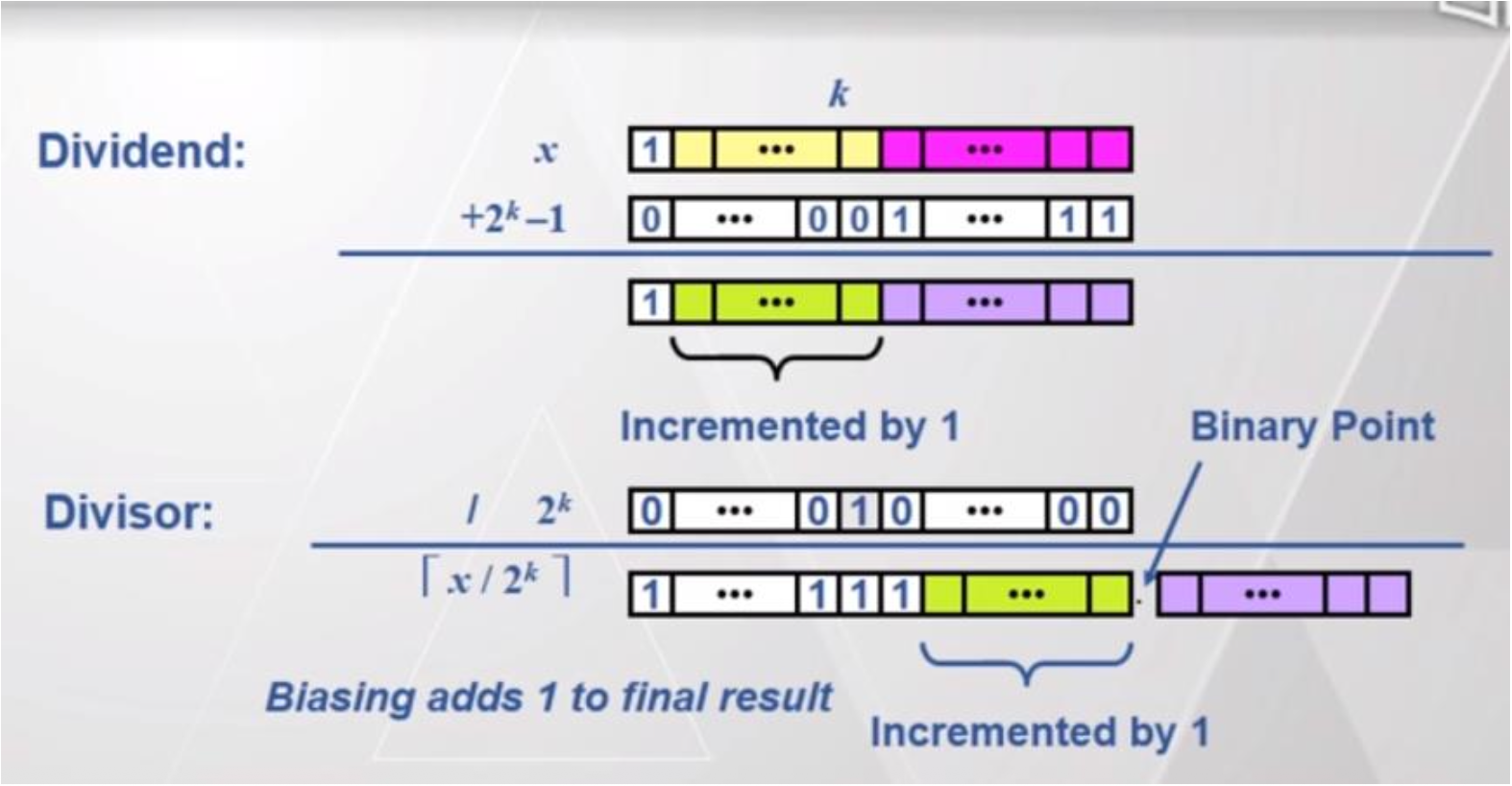

- 对于负数,
-
双精度移位(从 80386 开始)
-
两个指令
: SHLD(左移)和SHRD(右移) ,本质上是跨寄存器的移位
-
每条指令包含三个操作数(
SHLD/SHRD D, S, Count) ,而不是 2 个 - 例如指令
SHLD reg1, reg2, imm8将寄存器reg1和reg2连接起来,并将它们左移由imm8指定的数量 - 两个函数都使用两个 16 位、32 位或 64 位寄存器,或者一个 16 位、32 位或 64 位内存位置和一个寄存器
例子
-
Rotation⚓︎
- 通过在寄存器或内存位置中旋转信息来定位二进制数据,要么从一端到另一端,要么通过进位标志
-
语法:
ROL/ROR/RCL/RCR REG/MEM, Count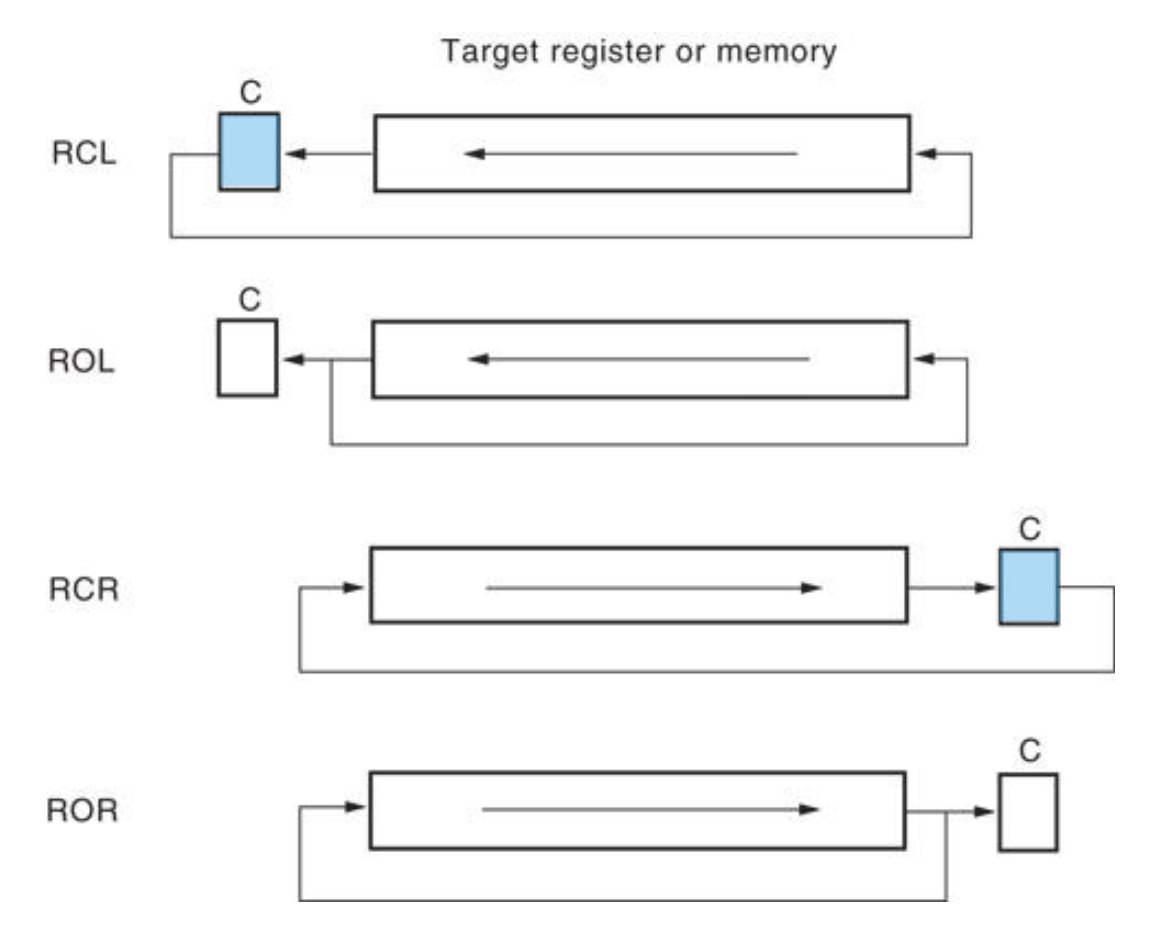
-
左旋(
ROL)和右旋(ROR)不包括CF标志 - 而进位左旋 (rotate through carry left)(
RCL)和进位右旋 (rotate through carry right)(RCR)将CF标志移入最高或最低有效位 - 旋转计数可以是立即数或寄存器
CL的值 - 旋转指令通常用于将宽数字向左或向右移动
例子
128 位值除以 2 的除法:
Bit Scan Instructions⚓︎
位扫描指令逐位扫描数字,找到其中置为 1 的位
- 在 80386 及以上处理器中可用
BSF(位向前扫描 (bit scan forward))从最低位向左扫描源数字BSR(位反向扫描 (bit scan reverse))从最高位向右扫描源数字- 语法:
BSF/BSR REG, REG/MEM - 如果没找到置为 1 的位,则设置零标志(
ZF = 1) - 如果找到置为 1 的位,则清除零标志(
ZF = 0) ,并将该位的位编号放入目标操作数中
例子
令 EAX = 60000000H = 0110 0000 0000 0000 0000 0000 0000 0000B
-
BSF EBX, EAXEBX = 29(位 29 是 1)ZF = 0
-
BSR EBX, EAXEBX = 30(位 30 是 1)ZF = 0
-
扩展:
TZCNT(尾部零计数 (tailing zero count))计算尾部零比特的数量LZCNT(前导零计数 (leading zero count))返回前导零比特的数量- 它们和
BSF/BSR之间的主要区别在于:- 如果源操作数 = 0(没有 1 位
) ,则BSF/BSR中目标操作数的内容是未定义的,而TZCNT/LZCNT提供操作数大小作为输出 - 如果源操作数 = 0,
BSF/BSR仅影响ZF,而TZCNT/LZCNT同时设置ZF和CF(ZF = 1, CF = 1) ,否则清零
- 如果源操作数 = 0(没有 1 位
例子
令
EAX = 60000000H = 0110 0000 0000 0000 0000 0000 0000 0000B-
LZCNT EBX, EAXEBX = 1(一个前导位)ZF = 0,CF = 0
-
BSR EBX, EAXEBX = 30(位 30 是 1)ZF = 0
String Comparisons⚓︎
- 字符串指令非常强大,能让程序员相对轻松地操作大量数据块
- 数据块操作通过
MOVS / LODS / STOS / INS / OUTS进行(上一章介绍过了) - 另外一些字符串指令能将内存的一部分,与常量或另一部分内存进行测试,包括
: SCAS(字符串扫描)和CMPS(字符串比较)
SCAS⚓︎
SCAS指令将使用内存操作数指定的字节、字、双字或四字与AL、AX或EAX中的值(隐式操作数)进行比较,然后在EFLAGS中设置状态标志以记录结果- 内存操作数地址根据当前操作模式的地址大小属性从
ES:EDI读取 -
操作数的大小可根据指令选择:
SCASB(字节比较)SCASW(字比较)SCASD(双字比较)
-
SCAS使用方向标志(D)来选择DI/EDI的自动增减操作 SCAS可以在块比较前使用条件重复前缀REPE(相等时重复)或REPNE(不相等时重复)
例子
- 假设内存的一个部分长度为 100 字节,并从位置
BLOCK开始 - 必须测试这个内存部分,以查看是否有任何位置包含
00H - 以下程序展示了如何使用
SCASB指令搜索内存的这一部分以查找00H
MOV DI, OFFSET BLOCK ; address data
CLD ; auto-increment
MOV CX, 100 ; load counter
XOR AL, AL ; clear AL
REPNE SCASB
在 SCASB 指令结束后
- 如果
ZF = 1,则某个位置包含00H - 如果
CX = 0且ZF = 0,则所有数据都不匹配00H
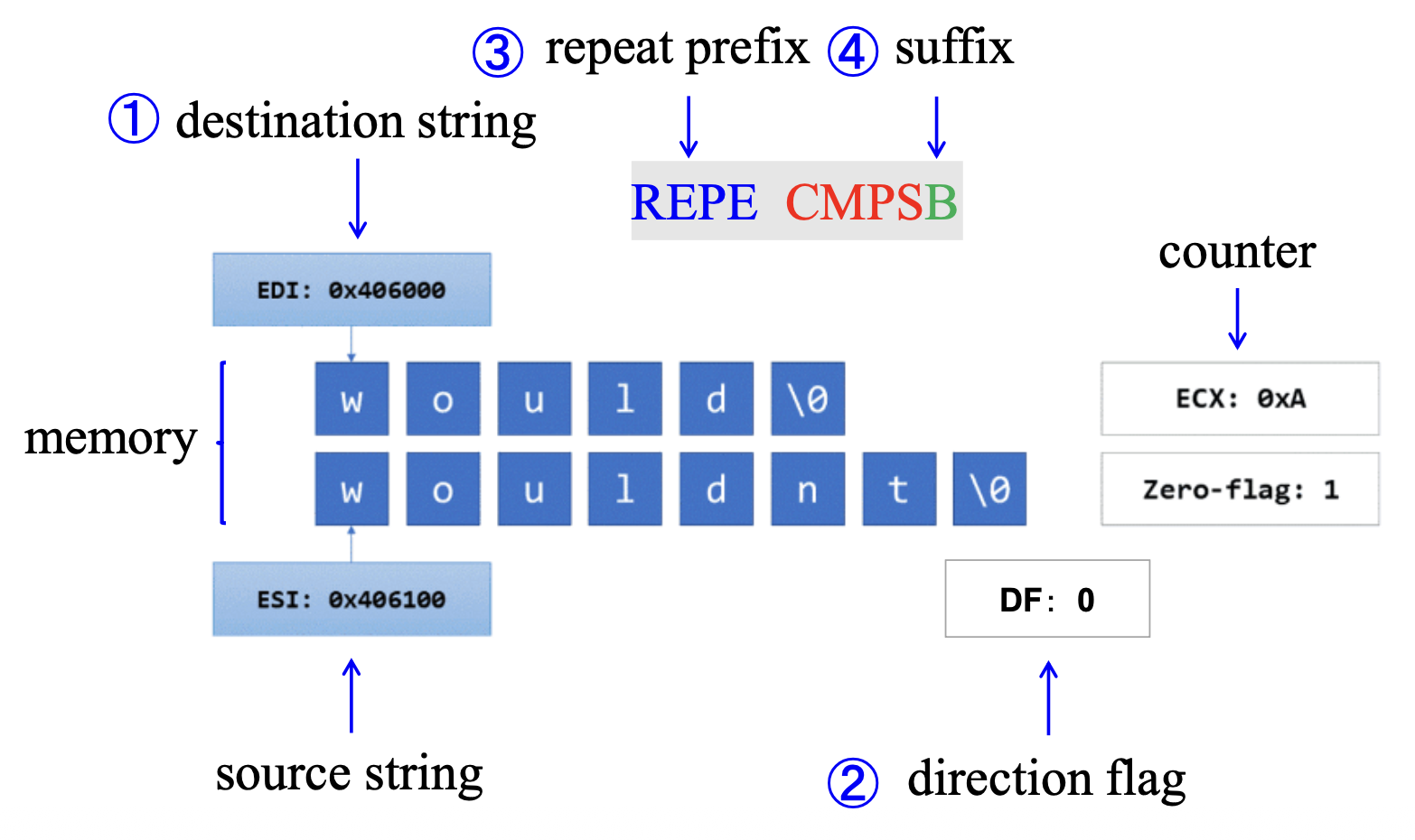
CMPS⚓︎
-
始终比较两个内存区域,数据以字节(
CMPSB) 、字(CMPSW)或双字(CMPSD)的形式进行比较- 由
SI/ESI寻址的数据段内存位置的内容,与由DI/EDI寻址的附加段内存的内容进行比较 CMPS指令会递增 / 递减计数器
- 由
-
通常与
REPE或REPNE前缀一起使用- 替代方案是
REPZ(在零时重复)和REPNZ(在非零时重复)
- 替代方案是
例子
评论区